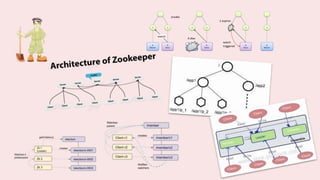
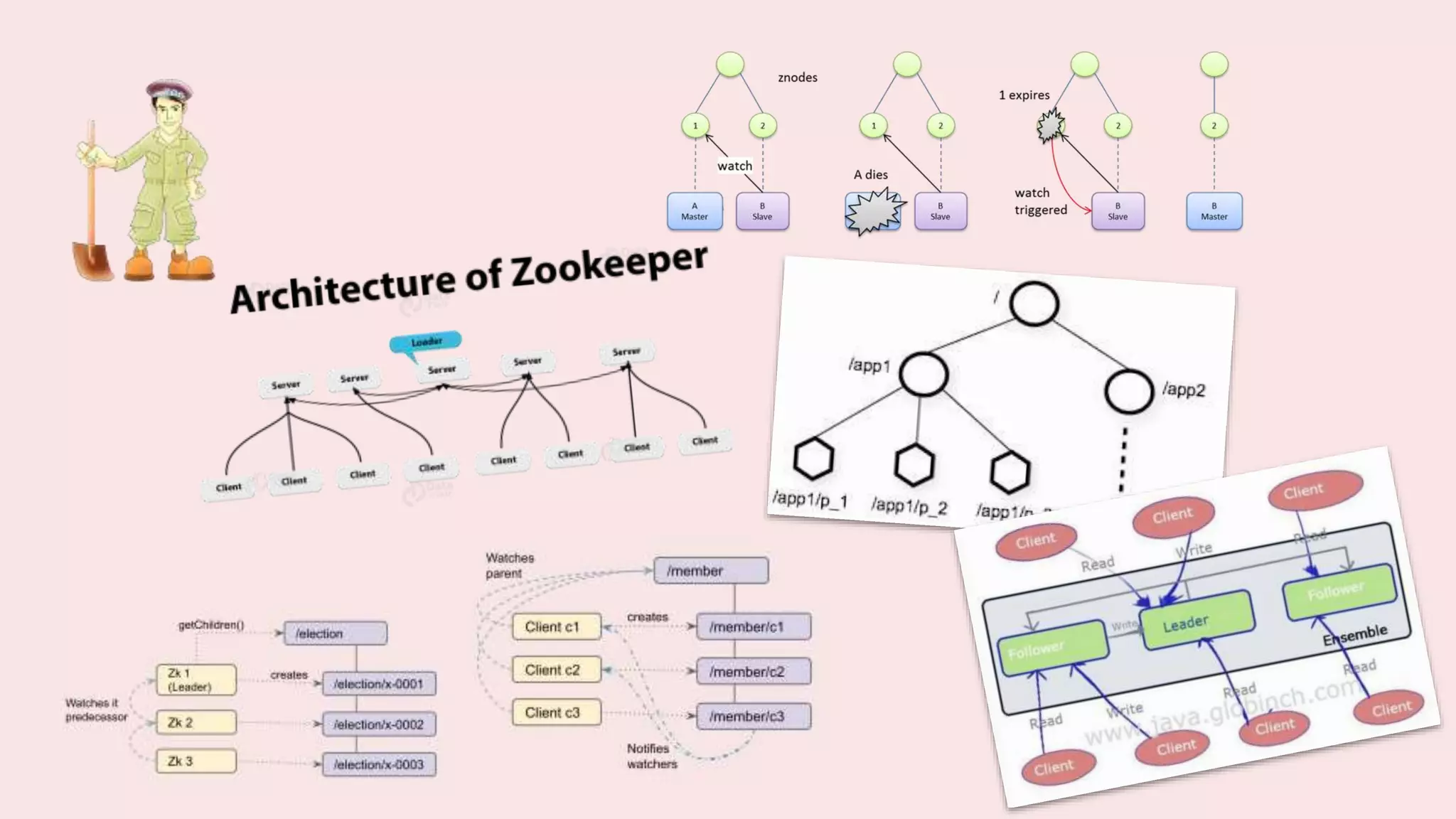
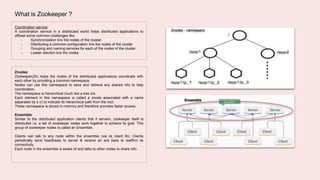
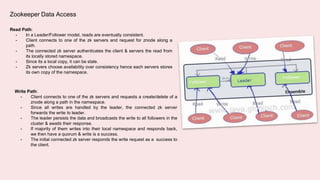
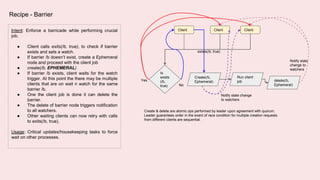
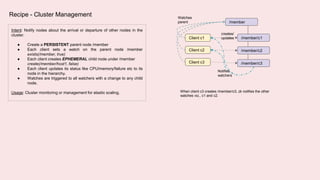
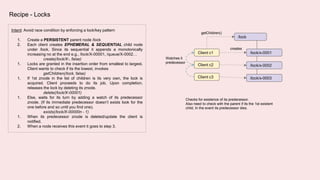
A coordination service like Zookeeper helps distributed applications coordinate by providing common services like synchronization, configuration sharing, naming, and leader election. Zookeeper uses an ensemble of servers running as a cluster. It stores data in a hierarchical namespace of znodes. Clients can read and write znodes, set watches on znodes to get notified of changes, and rely on Zookeeper to handle session and server failures in a transparent way. Some common usage recipes for Zookeeper include barriers for synchronization, cluster management using ephemeral znodes, queues using sequential znodes, locks for mutual exclusion, and leader election.