Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
MS
Uploaded by
Masaki Saito
PDF, PPTX
17,393 views
Caffeのデータレイヤで夢が広がる話
Caffeのデータレイヤに手を加えることで,いろいろと可能性が広がる話をします
Engineering
◦
Read more
36
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 17
2
/ 17
3
/ 17
4
/ 17
5
/ 17
6
/ 17
7
/ 17
8
/ 17
9
/ 17
10
/ 17
11
/ 17
12
/ 17
13
/ 17
14
/ 17
15
/ 17
16
/ 17
17
/ 17
More Related Content
PDF
Development and Experiment of Deep Learning with Caffe and maf
by
Kenta Oono
PDF
ディープラーニング最近の発展とビジネス応用への課題
by
Kenta Oono
PDF
Elasticsearchと機械学習を実際に連携させる
by
nobu_k
PPTX
SensorBeeでChainerをプラグインとして使う
by
Daisuke Tanaka
PDF
Python 機械学習プログラミング データ分析演習編
by
Etsuji Nakai
PDF
Kerasで深層学習を実践する
by
Kazuaki Tanida
PDF
Introduction to Chainer and CuPy
by
Kenta Oono
PDF
How to Develop Experiment-Oriented Programs
by
Kenta Oono
Development and Experiment of Deep Learning with Caffe and maf
by
Kenta Oono
ディープラーニング最近の発展とビジネス応用への課題
by
Kenta Oono
Elasticsearchと機械学習を実際に連携させる
by
nobu_k
SensorBeeでChainerをプラグインとして使う
by
Daisuke Tanaka
Python 機械学習プログラミング データ分析演習編
by
Etsuji Nakai
Kerasで深層学習を実践する
by
Kazuaki Tanida
Introduction to Chainer and CuPy
by
Kenta Oono
How to Develop Experiment-Oriented Programs
by
Kenta Oono
What's hot
PDF
Deep Learning技術の最近の動向とPreferred Networksの取り組み
by
Kenta Oono
PDF
20171212 gtc pfn海野裕也_chainerで加速する深層学習とフレームワークの未来
by
Preferred Networks
PDF
PFN のオンプレML基盤の取り組み / オンプレML基盤 on Kubernetes 〜PFN、ヤフー〜
by
Preferred Networks
PPTX
ChainerでDeep Learningを試す為に必要なこと
by
Jiro Nishitoba
PDF
東北大学講義資料 実世界における自然言語処理 - すべての人にロボットを - 坪井祐太
by
Preferred Networks
PPTX
SensorBeeのご紹介
by
Daisuke Tanaka
PDF
ヤフー音声認識サービスでのディープラーニングとGPU利用事例
by
Yahoo!デベロッパーネットワーク
PDF
日本神経回路学会セミナー「DeepLearningを使ってみよう!」資料
by
Kenta Oono
PDF
経済学のための実践的データ分析 1. イントロダクション/Jupyter Notebook をインストールする
by
Yasushi Hara
PPTX
Jupyter Notebookでscikit-learnを使った機械学習・画像処理の基本
by
Norihiko Nakabayashi
PDF
TensorFlowによるニューラルネットワーク入門
by
Etsuji Nakai
PDF
Chainer入門と最近の機能
by
Yuya Unno
PDF
Introduction to Chainer (LL Ring Recursive)
by
Kenta Oono
PDF
210609 Biopackthon: BioImageDbs for ExperimentalHub (修正版)
by
Satoshi Kume
PDF
Jubatusの特徴変換と線形分類器の仕組み
by
JubatusOfficial
PPTX
JSAI's AI Tool Introduction - Deep Learning, Pylearn2 and Torch7
by
Kotaro Nakayama
PDF
機械学習を利用したちょっとリッチな検索
by
nobu_k
PDF
Jubatusにおける機械学習のテスト@MLCT
by
Yuya Unno
PDF
SensorBeeの紹介
by
Shuzo Kashihara
PDF
bigdata2012nlp okanohara
by
Preferred Networks
Deep Learning技術の最近の動向とPreferred Networksの取り組み
by
Kenta Oono
20171212 gtc pfn海野裕也_chainerで加速する深層学習とフレームワークの未来
by
Preferred Networks
PFN のオンプレML基盤の取り組み / オンプレML基盤 on Kubernetes 〜PFN、ヤフー〜
by
Preferred Networks
ChainerでDeep Learningを試す為に必要なこと
by
Jiro Nishitoba
東北大学講義資料 実世界における自然言語処理 - すべての人にロボットを - 坪井祐太
by
Preferred Networks
SensorBeeのご紹介
by
Daisuke Tanaka
ヤフー音声認識サービスでのディープラーニングとGPU利用事例
by
Yahoo!デベロッパーネットワーク
日本神経回路学会セミナー「DeepLearningを使ってみよう!」資料
by
Kenta Oono
経済学のための実践的データ分析 1. イントロダクション/Jupyter Notebook をインストールする
by
Yasushi Hara
Jupyter Notebookでscikit-learnを使った機械学習・画像処理の基本
by
Norihiko Nakabayashi
TensorFlowによるニューラルネットワーク入門
by
Etsuji Nakai
Chainer入門と最近の機能
by
Yuya Unno
Introduction to Chainer (LL Ring Recursive)
by
Kenta Oono
210609 Biopackthon: BioImageDbs for ExperimentalHub (修正版)
by
Satoshi Kume
Jubatusの特徴変換と線形分類器の仕組み
by
JubatusOfficial
JSAI's AI Tool Introduction - Deep Learning, Pylearn2 and Torch7
by
Kotaro Nakayama
機械学習を利用したちょっとリッチな検索
by
nobu_k
Jubatusにおける機械学習のテスト@MLCT
by
Yuya Unno
SensorBeeの紹介
by
Shuzo Kashihara
bigdata2012nlp okanohara
by
Preferred Networks
Similar to Caffeのデータレイヤで夢が広がる話
PDF
Convolutional Neural Network @ CV勉強会関東
by
Hokuto Kagaya
PPTX
いきなりAi tensor flow gpuによる画像分類と生成
by
Yoshi Sakai
PDF
エヌビディアが加速するディープラーニング ~進化するニューラルネットワークとその開発方法について~
by
NVIDIA Japan
PDF
B3スタートアップ コンピュータビジョンの現在と未来にやるべきこと(東京電機大学講演)
by
cvpaper. challenge
PPTX
はじめての人のためのDeep Learning
by
Tadaichiro Nakano
PDF
Convolutional Neural Networks のトレンド @WBAFLカジュアルトーク#2
by
Daiki Shimada
PDF
自習形式で学ぶ「DIGITS による画像分類入門」
by
NVIDIA Japan
PDF
2値化CNN on FPGAでGPUとガチンコバトル(公開版)
by
Hiroki Nakahara
PDF
R-CNNの原理とここ数年の流れ
by
Kazuki Motohashi
PDF
[論文紹介] Convolutional Neural Network(CNN)による超解像
by
Rei Takami
PDF
ハンズオン1: DIGITS によるディープラーニング入門
by
NVIDIA Japan
PPTX
2018/06/23 Sony"s deep learning software and the latest information
by
Sony Network Communications Inc.
PPTX
Densely Connected Convolutional Networks
by
harmonylab
PDF
Deep Learningライブラリ 色々つかってみた感想まとめ
by
Takanori Ogata
PDF
20140131 R-CNN
by
Takuya Minagawa
PDF
Caffeでお手軽本格ディープラーニングアプリ @potatotips
by
Takuya Matsuyama
PPTX
ゼロから深層学習を学ぶ方法 - CMS大阪夏祭り2017
by
Tomo Masuda
PDF
MIRU_Preview_JSAI2019
by
Takayoshi Yamashita
PDF
DIGITSによるディープラーニング画像分類
by
NVIDIA Japan
PDF
ハンズオン セッション 1: DIGITS によるディープラーニング入門
by
NVIDIA Japan
Convolutional Neural Network @ CV勉強会関東
by
Hokuto Kagaya
いきなりAi tensor flow gpuによる画像分類と生成
by
Yoshi Sakai
エヌビディアが加速するディープラーニング ~進化するニューラルネットワークとその開発方法について~
by
NVIDIA Japan
B3スタートアップ コンピュータビジョンの現在と未来にやるべきこと(東京電機大学講演)
by
cvpaper. challenge
はじめての人のためのDeep Learning
by
Tadaichiro Nakano
Convolutional Neural Networks のトレンド @WBAFLカジュアルトーク#2
by
Daiki Shimada
自習形式で学ぶ「DIGITS による画像分類入門」
by
NVIDIA Japan
2値化CNN on FPGAでGPUとガチンコバトル(公開版)
by
Hiroki Nakahara
R-CNNの原理とここ数年の流れ
by
Kazuki Motohashi
[論文紹介] Convolutional Neural Network(CNN)による超解像
by
Rei Takami
ハンズオン1: DIGITS によるディープラーニング入門
by
NVIDIA Japan
2018/06/23 Sony"s deep learning software and the latest information
by
Sony Network Communications Inc.
Densely Connected Convolutional Networks
by
harmonylab
Deep Learningライブラリ 色々つかってみた感想まとめ
by
Takanori Ogata
20140131 R-CNN
by
Takuya Minagawa
Caffeでお手軽本格ディープラーニングアプリ @potatotips
by
Takuya Matsuyama
ゼロから深層学習を学ぶ方法 - CMS大阪夏祭り2017
by
Tomo Masuda
MIRU_Preview_JSAI2019
by
Takayoshi Yamashita
DIGITSによるディープラーニング画像分類
by
NVIDIA Japan
ハンズオン セッション 1: DIGITS によるディープラーニング入門
by
NVIDIA Japan
Caffeのデータレイヤで夢が広がる話
1.
Caffeのデータレイヤで夢が広がる話 第27回コンピュータビジョン勉強会@関東 2015/01/31 @rezoolab (齋藤
真樹)
2.
自己紹介 • 東北大学岡谷研D2 齋藤
真樹 (DC2) – Twitter ID: @rezoolab – コンピュータビジョンに関する理論研究 • 主な業績: CVPR 2本 (+1?) – コンピュータビジョン最先端ガイド6 執筆 – 真面目に就職先探していますのでお気軽に お声がけください
3.
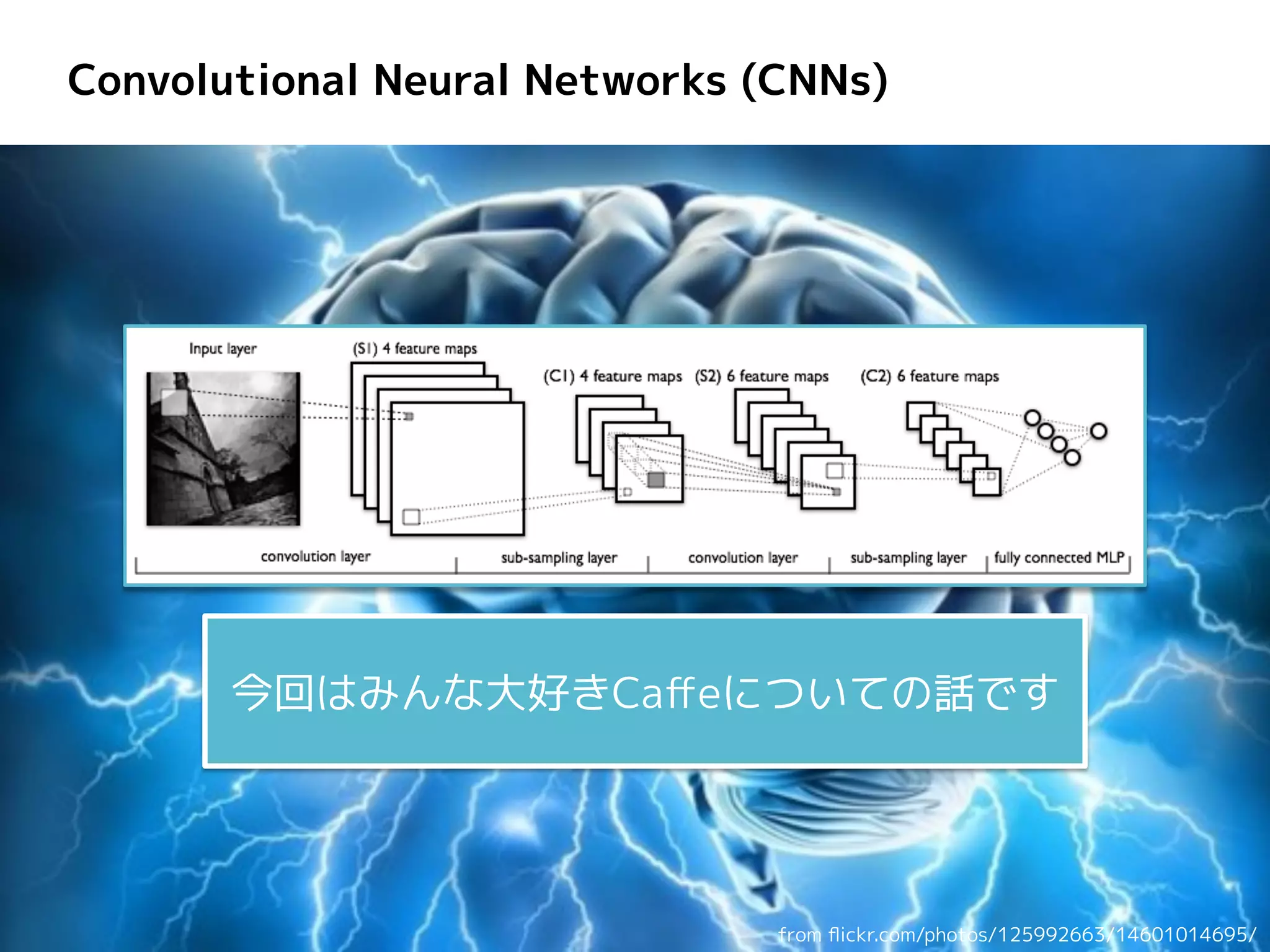
Convolutional Neural Networks
(CNNs) from flickr.com/photos/125992663/14601014695/ 今回はみんな大好きCaffeについての話です
4.
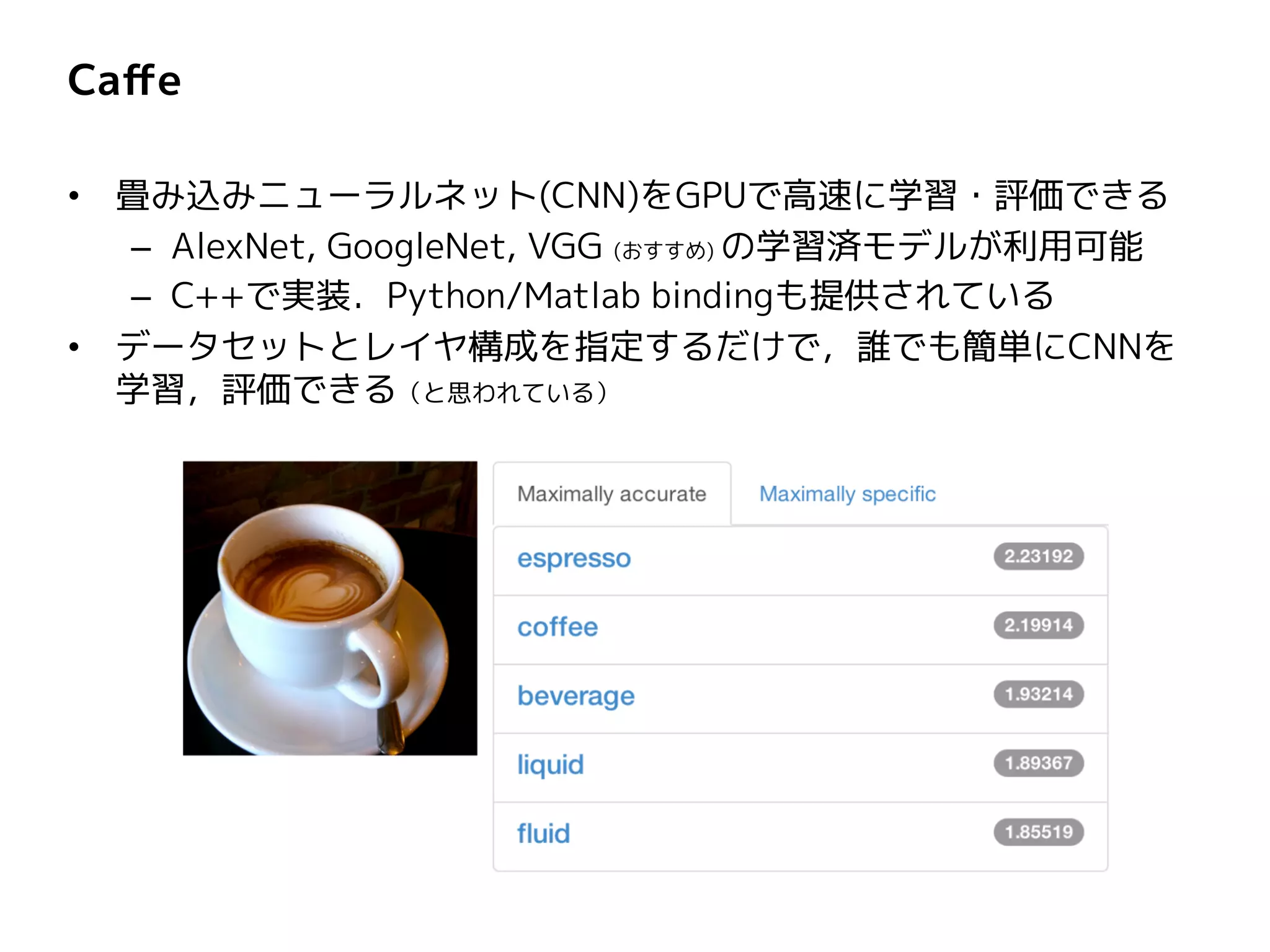
Caffe • 畳み込みニューラルネット(CNN)をGPUで高速に学習・評価できる – AlexNet,
GoogleNet, VGG (おすすめ) の学習済モデルが利用可能 – C++で実装.Python/Matlab bindingも提供されている • データセットとレイヤ構成を指定するだけで,誰でも簡単にCNNを 学習,評価できる(と思われている)
5.
Caffe難易度表 (独断と偏見) 比較的取りかかりやすい • Pre-trained
modelを利用した特徴量抽出 • 106オーダーの画像を使って一から多クラス分類 • Transfer Learningによる多クラス分類 ちょっと難しい • 回帰問題,セグメンテーション問題への応用 • C++弄って独自のレイヤを実装,評価 結構難しい • Deep Boltzmann Machineの実装 • Recurrent Neural Networkの実装 • 最高精度達成してトップ会議通す(超赤海)
6.
Caffeのアーキテクチャ (学習時) • CaffeのネットワークはBlobとLayerの2種類から成り立つ –
Blob: CNNの実データを格納するデータ構造 – Layer: 畳み込みやプーリング,内積などの操作単位 “data” “conv1” “pool1” “fc1” “loss” Layer Blob “label” [( , 3), ( , 5), …] 3 Key-Value Store “data” “conv1” “pool1” “fc1” “loss”
7.
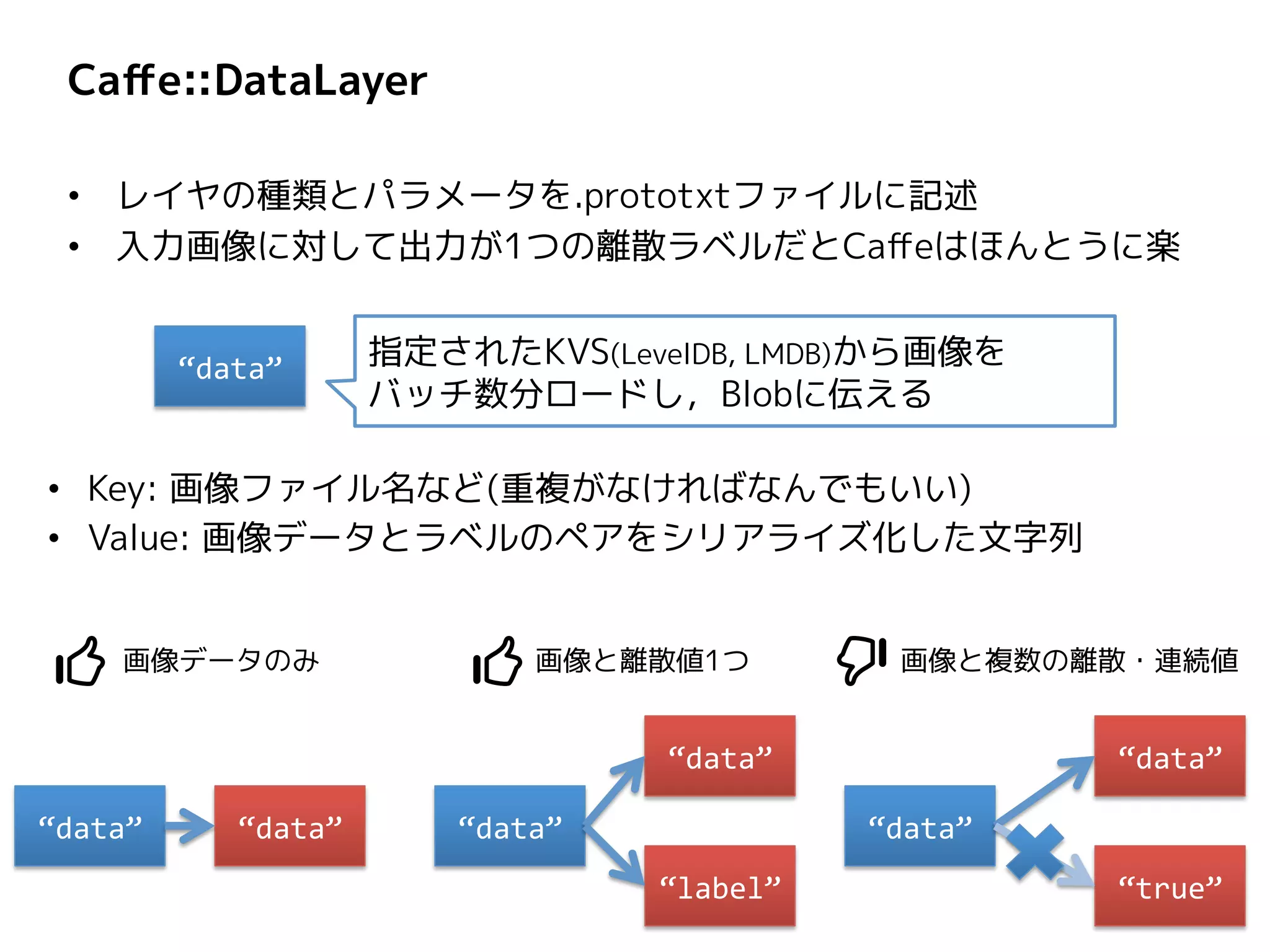
Caffe::DataLayer • レイヤの種類とパラメータを.prototxtファイルに記述 • 入力画像に対して出力が1つの離散ラベルだとCaffeはほんとうに楽 “data”
指定されたKVS(LevelDB, LMDB)から画像を バッチ数分ロードし,Blobに伝える “data” “data” “true” • Key: 画像ファイル名など(重複がなければなんでもいい) • Value: 画像データとラベルのペアをシリアライズ化した文字列 “data” “data” “label” “data” “data” 画像データのみ 画像と離散値1つ 画像と複数の離散・連続値
8.
データレイヤ問題を解決するための2つの方法 データレイヤを増やす
9.
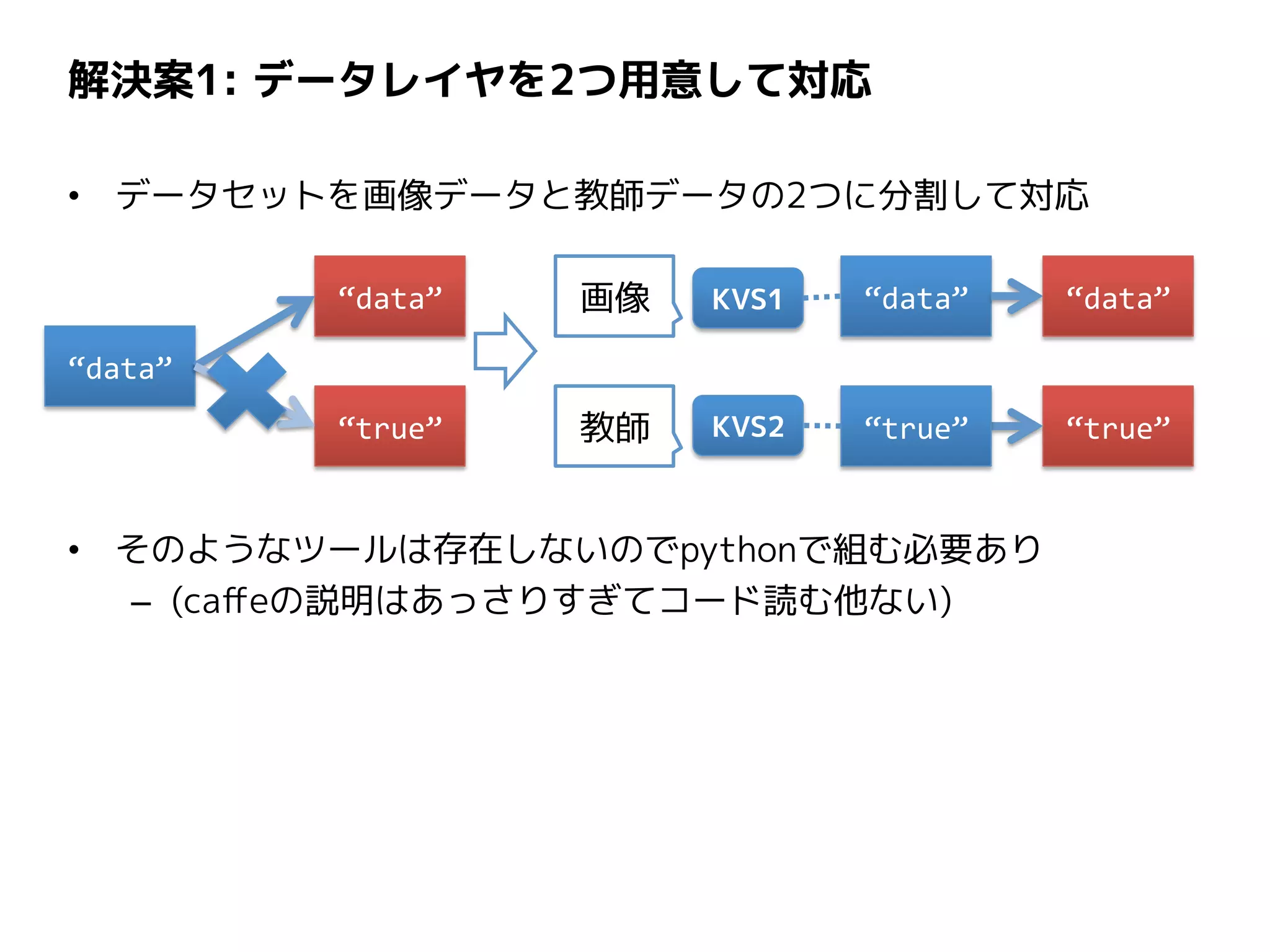
解決案1: データレイヤを2つ用意して対応 • データセットを画像データと教師データの2つに分割して対応 •
そのようなツールは存在しないのでpythonで組む必要あり – (caffeの説明はあっさりすぎてコード読む他ない) “data” “data” “true” 画像 “data” “data” “true”“true”教師 KVS1 KVS2
10.
解決案1: データレイヤを2つ用意して対応 • 画像データ用KVSの作り方 –
Valueの実態はProtocol Bufferで定義された構造体Datum – ndarrayをdatumに変換するcaffe.io.array_to_datum()がある shapeは (channels, height, width) 整合性のためにBGRオーダーがベター import cv2 from caffe.io import array_to_datum # load an image (BGR order) and serialize it img = cv2.resize(cv2.imread(path), shape).transpose([2,0,1]) img_datum = array_to_datum(img) img_str = img_datum.SerializeToString() # put img_str into KVS db.Put(key=path, value=img_str)
11.
解決案1: データレイヤを2つ用意して対応 • 教師データ用KVSの作り方 –
そのような便利関数は存在しない(世間は厳しい) – 浮動小数点の配列を格納するためのフィールド “Datum::float_data”の中に入れる from caffe.io import caffe_pb2 # suppose that arr is a one-dimensional np.ndarray d = caffe_pb2.Datum() d.float_data.extend(list(arr)) d.channels, d.height, d.width = arr.size, 1, 1 datum_str = d.SerializeToString() # put datum_str into KVS kvs2.Put(key=path, value=datum_str)
12.
自前でデータレイヤを作る データレイヤ問題を解決するための2つの方法
13.
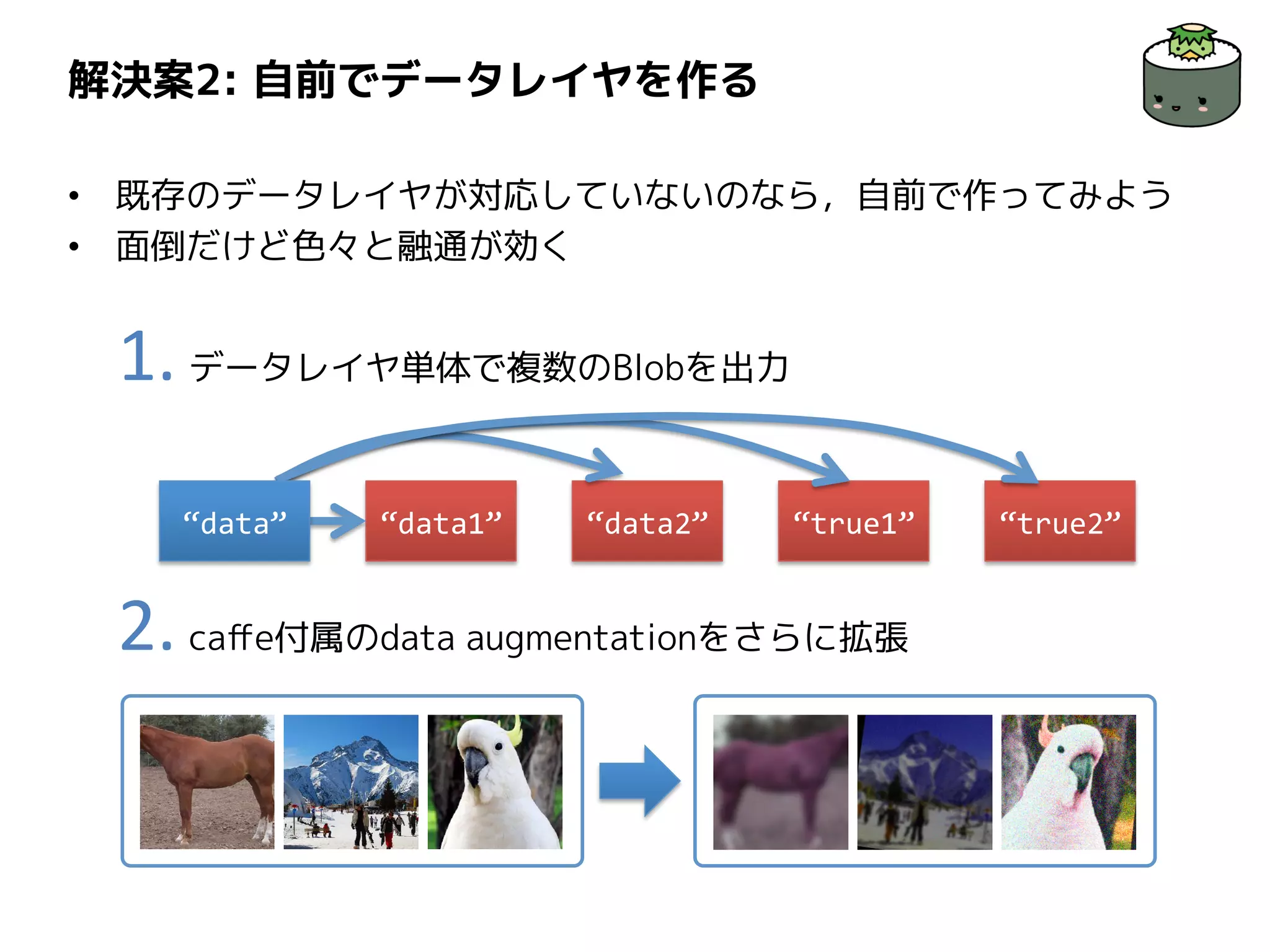
解決案2: 自前でデータレイヤを作る • 既存のデータレイヤが対応していないのなら,自前で作ってみよう •
面倒だけど色々と融通が効く 1. データレイヤ単体で複数のBlobを出力 2. caffe付属のdata augmentationをさらに拡張 “data1” “true1”“data2” “true2”“data”
14.
Caffe (client) 解決案2: 自前でデータレイヤを作る •
http経由でBlobを取得するHTTPDataLayerを作りました – データ加工等の面倒な箇所はすべてサーバに委託 “localhost/blob” Server KVS1 “data” http request response KVS2 “data1” “data2” [“data1”, “data2”] [blob1, blob2]
15.
解決案2: 自前でデータレイヤを作る DEMO
16.
まとめ • Caffeで識別以外の学習を行う方法は2つある 1. データレイヤを2つ作成してがんばる 2.
データレイヤを新しく作成する • 応用としてデータレイヤ用のhttpクライアントとサーバを書いた • 研究室で試運転中.機能を整えたらGithubで公開
17.
おわり ※アイコンはCC BY 3.0のDripiconsを使用しました:
http://www.flaticon.com/packs/dripicons/ ※イラストはCC BY-NC-ND 4.0の寿司ゆきを使用しました: http://awayuki.net/sushiyuki/
Download



![Caffeのアーキテクチャ (学習時)
• CaffeのネットワークはBlobとLayerの2種類から成り立つ
– Blob: CNNの実データを格納するデータ構造
– Layer: 畳み込みやプーリング,内積などの操作単位
“data” “conv1” “pool1” “fc1” “loss”
Layer
Blob
“label”
[( , 3), ( , 5), …]
3
Key-Value
Store
“data” “conv1” “pool1” “fc1” “loss”](https://image.slidesharecdn.com/caffe-150130114749-conversion-gate02/75/Caffe-6-2048.jpg)

![解決案1: データレイヤを2つ用意して対応
• 画像データ用KVSの作り方
– Valueの実態はProtocol Bufferで定義された構造体Datum
– ndarrayをdatumに変換するcaffe.io.array_to_datum()がある
shapeは (channels, height, width)
整合性のためにBGRオーダーがベター
import cv2
from caffe.io import array_to_datum
# load an image (BGR order) and serialize it
img = cv2.resize(cv2.imread(path), shape).transpose([2,0,1])
img_datum = array_to_datum(img)
img_str = img_datum.SerializeToString()
# put img_str into KVS
db.Put(key=path, value=img_str)](https://image.slidesharecdn.com/caffe-150130114749-conversion-gate02/75/Caffe-10-2048.jpg)


![Caffe (client)
解決案2: 自前でデータレイヤを作る
• http経由でBlobを取得するHTTPDataLayerを作りました
– データ加工等の面倒な箇所はすべてサーバに委託
“localhost/blob”
Server
KVS1
“data”
http request
response
KVS2
“data1”
“data2”
[“data1”, “data2”]
[blob1, blob2]](https://image.slidesharecdn.com/caffe-150130114749-conversion-gate02/75/Caffe-14-2048.jpg)








































![[論文紹介] Convolutional Neural Network(CNN)による超解像](https://cdn.slidesharecdn.com/ss_thumbnails/cnn-presen-161218113749-thumbnail.jpg?width=640&height=640&fit=bounds)









