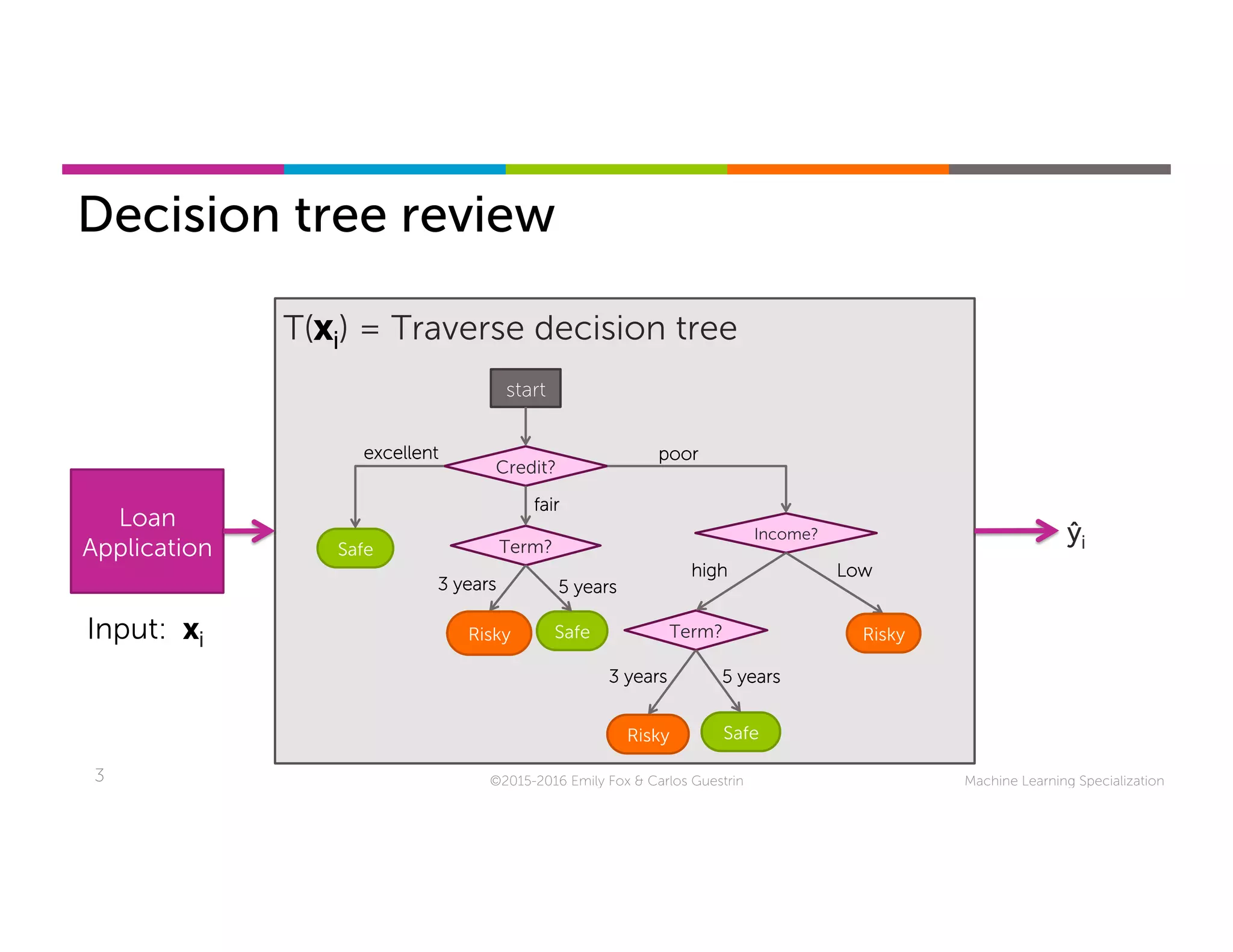
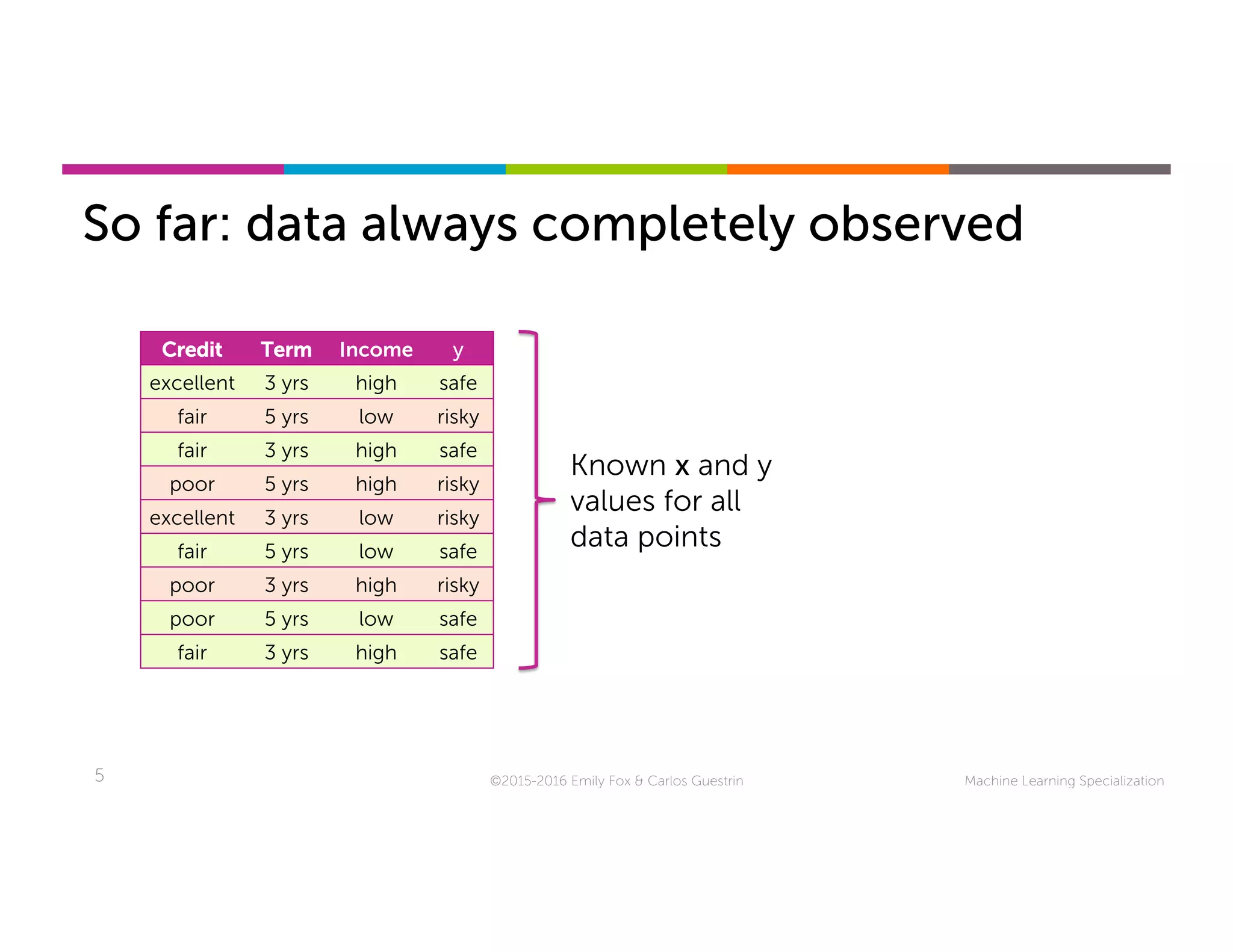
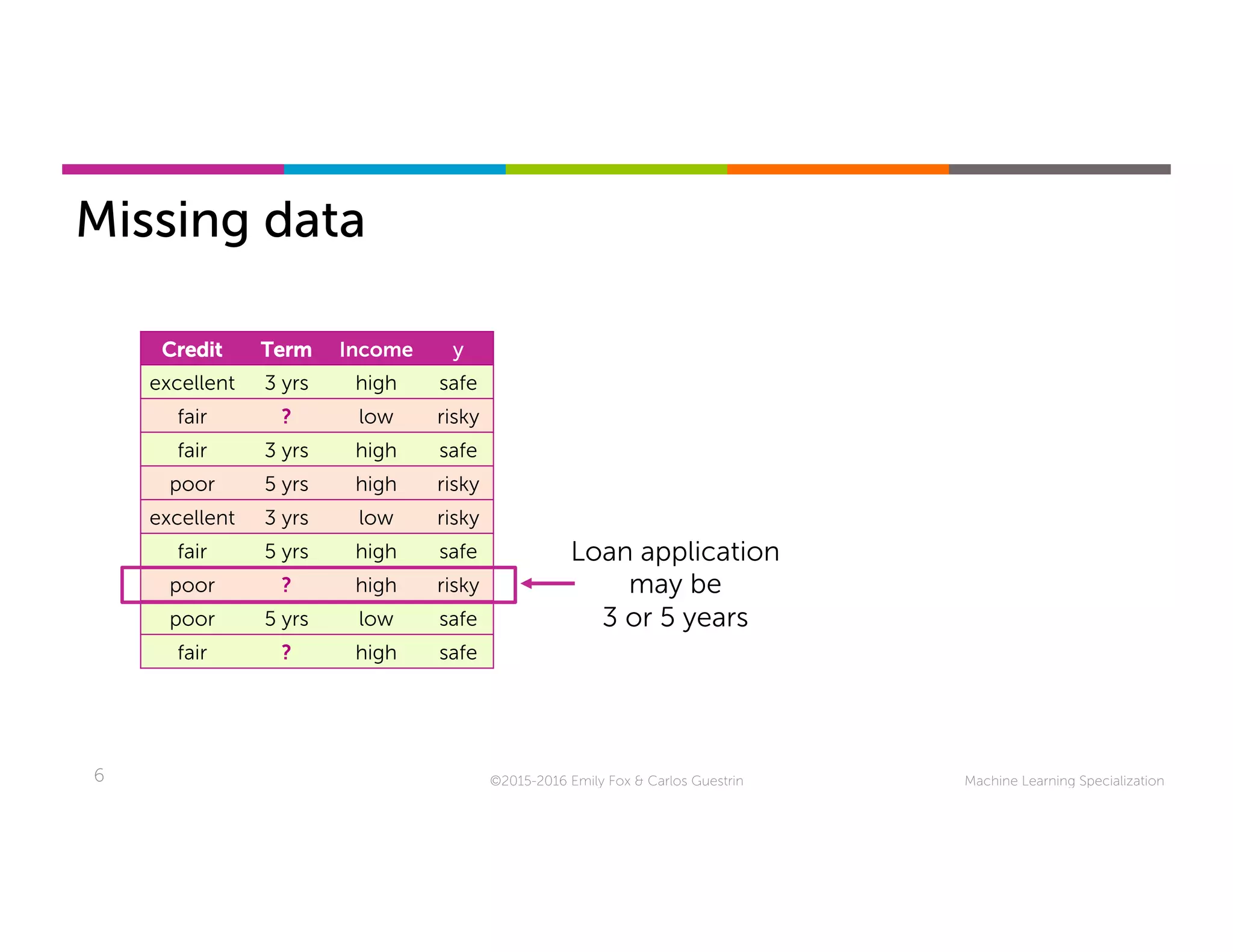
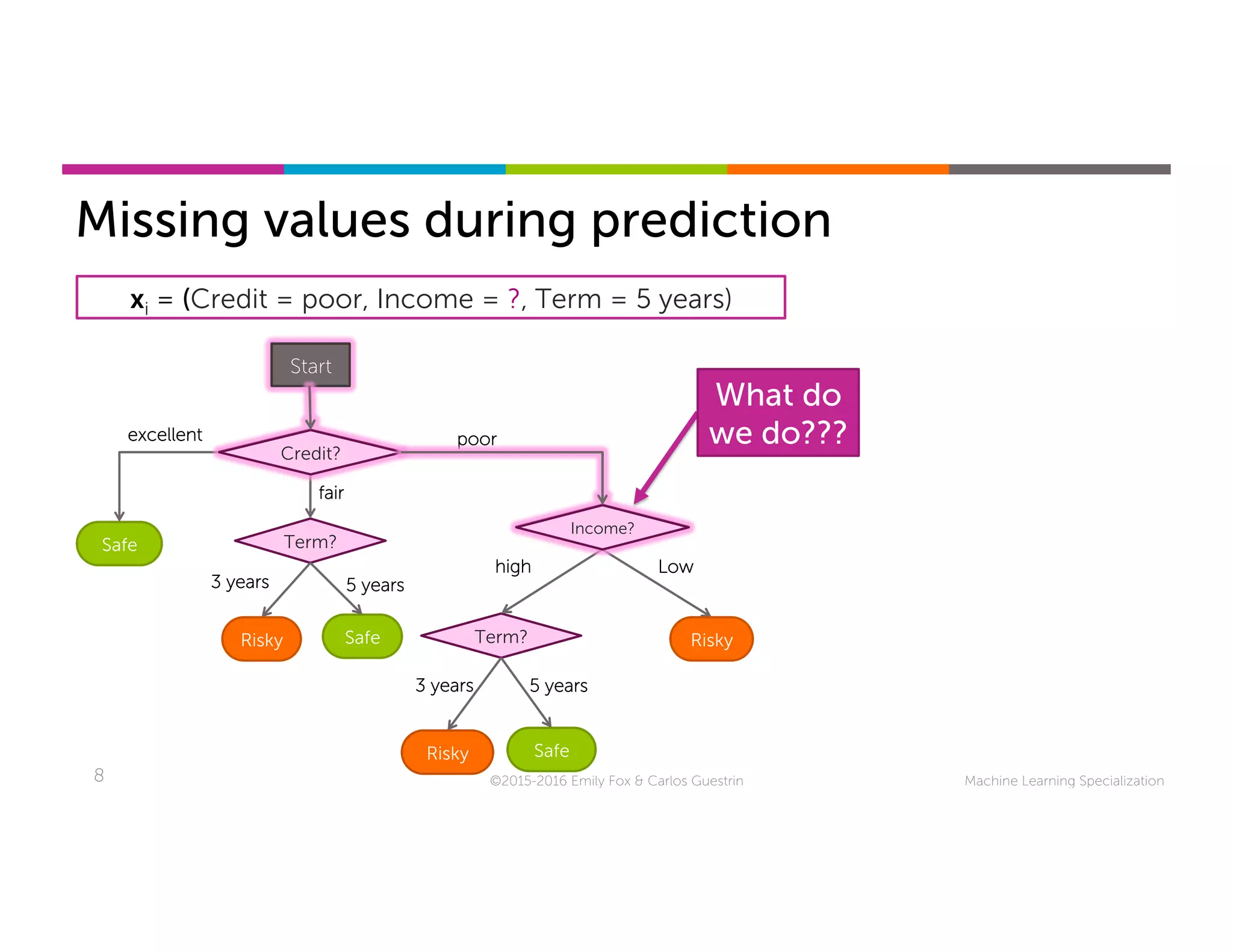
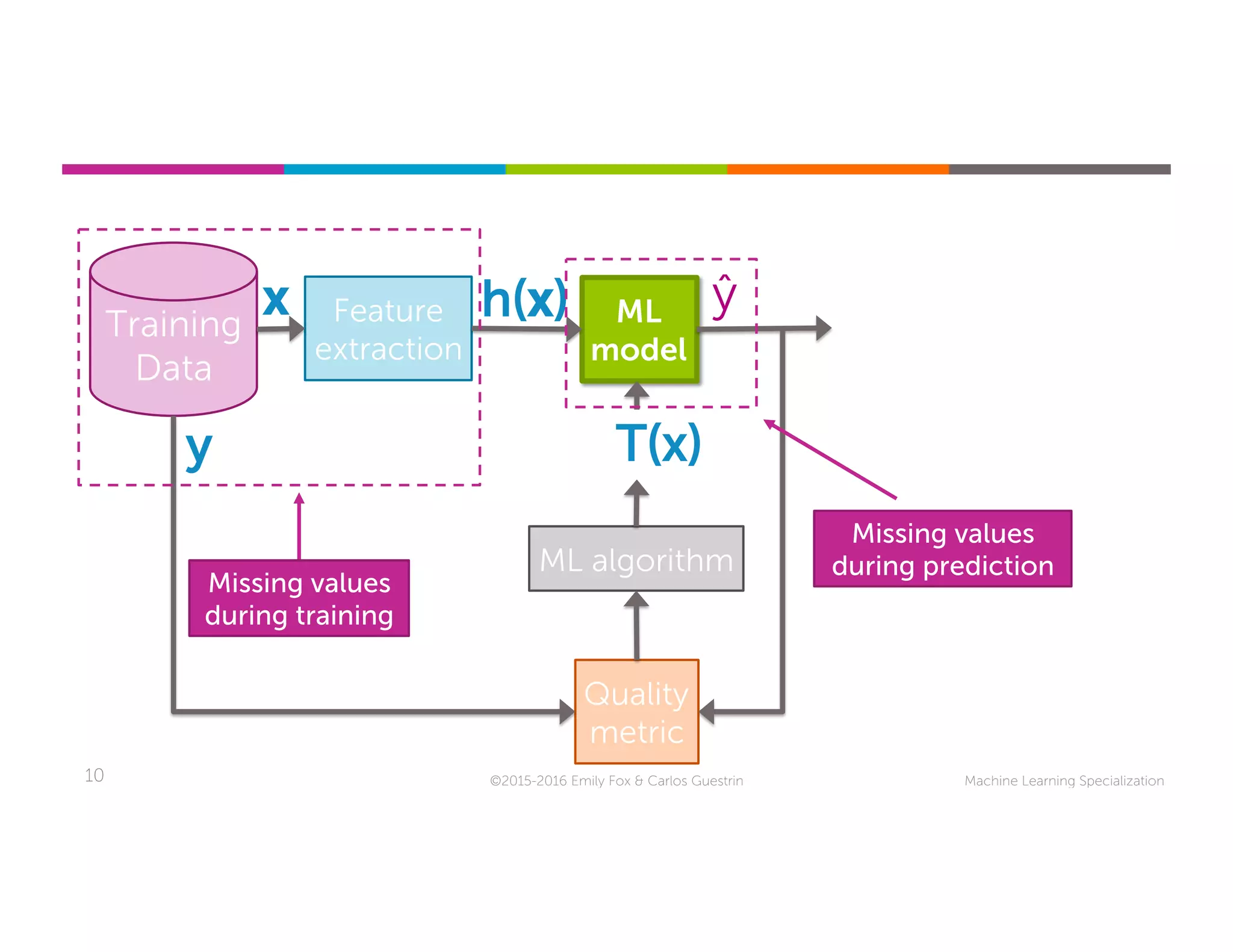
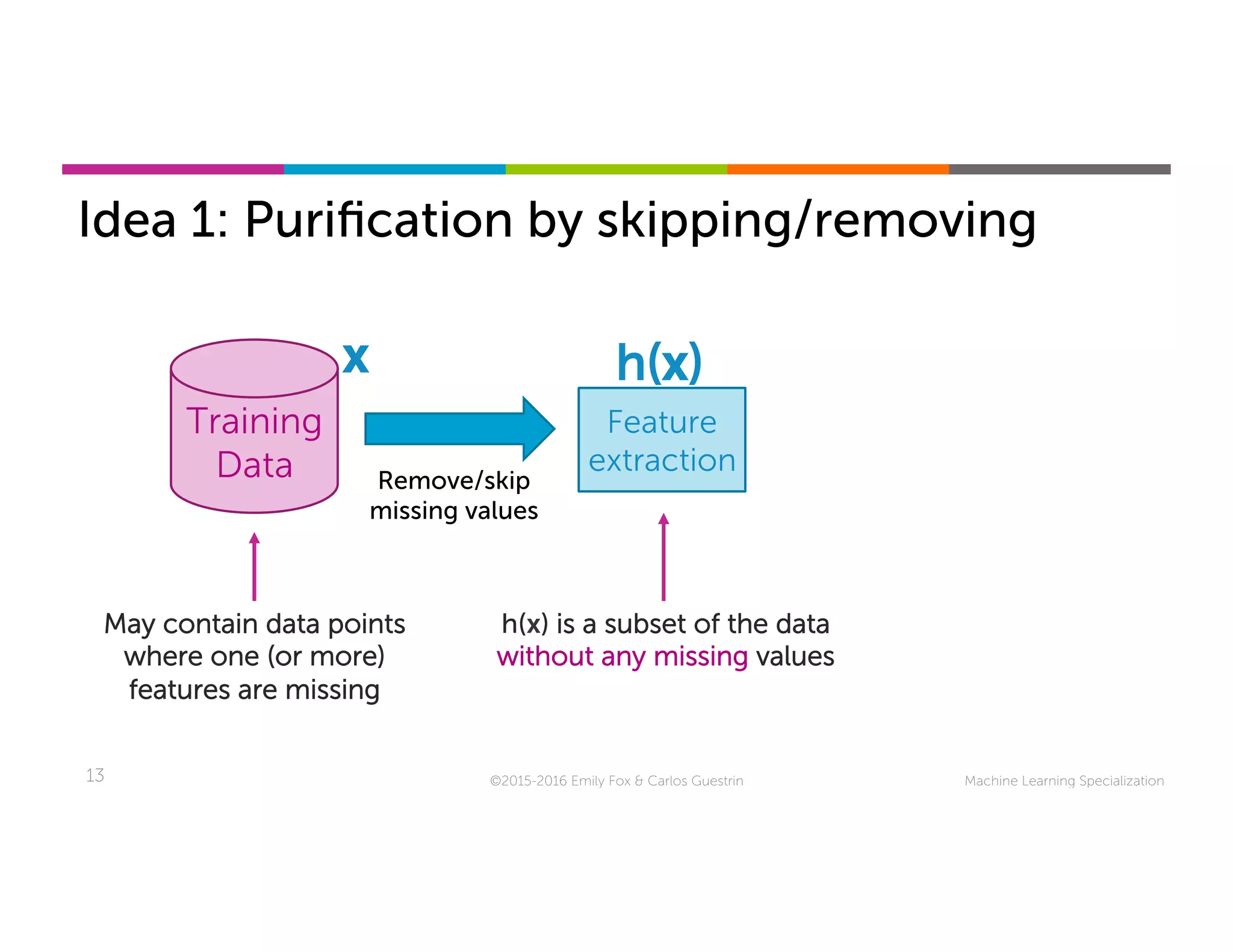
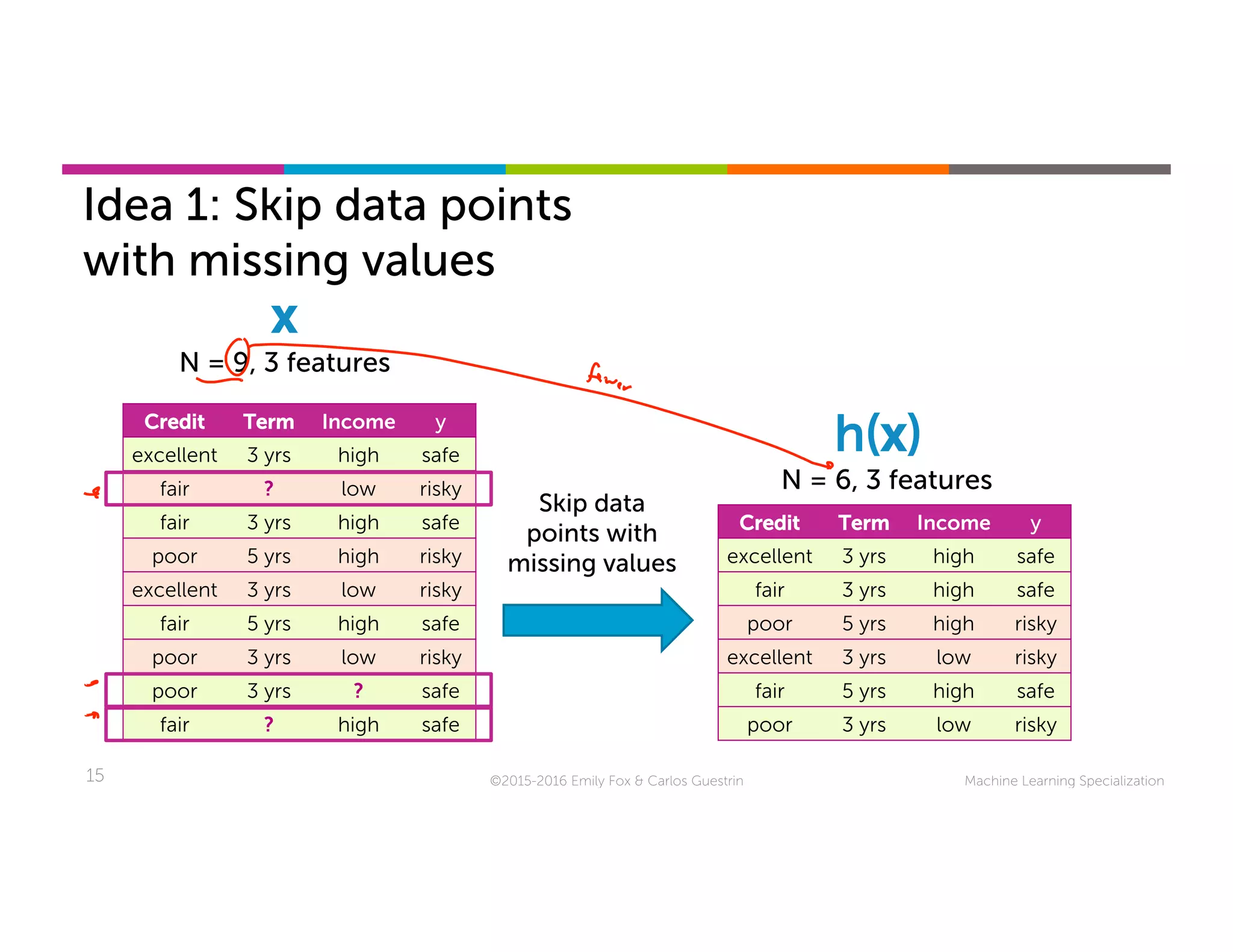
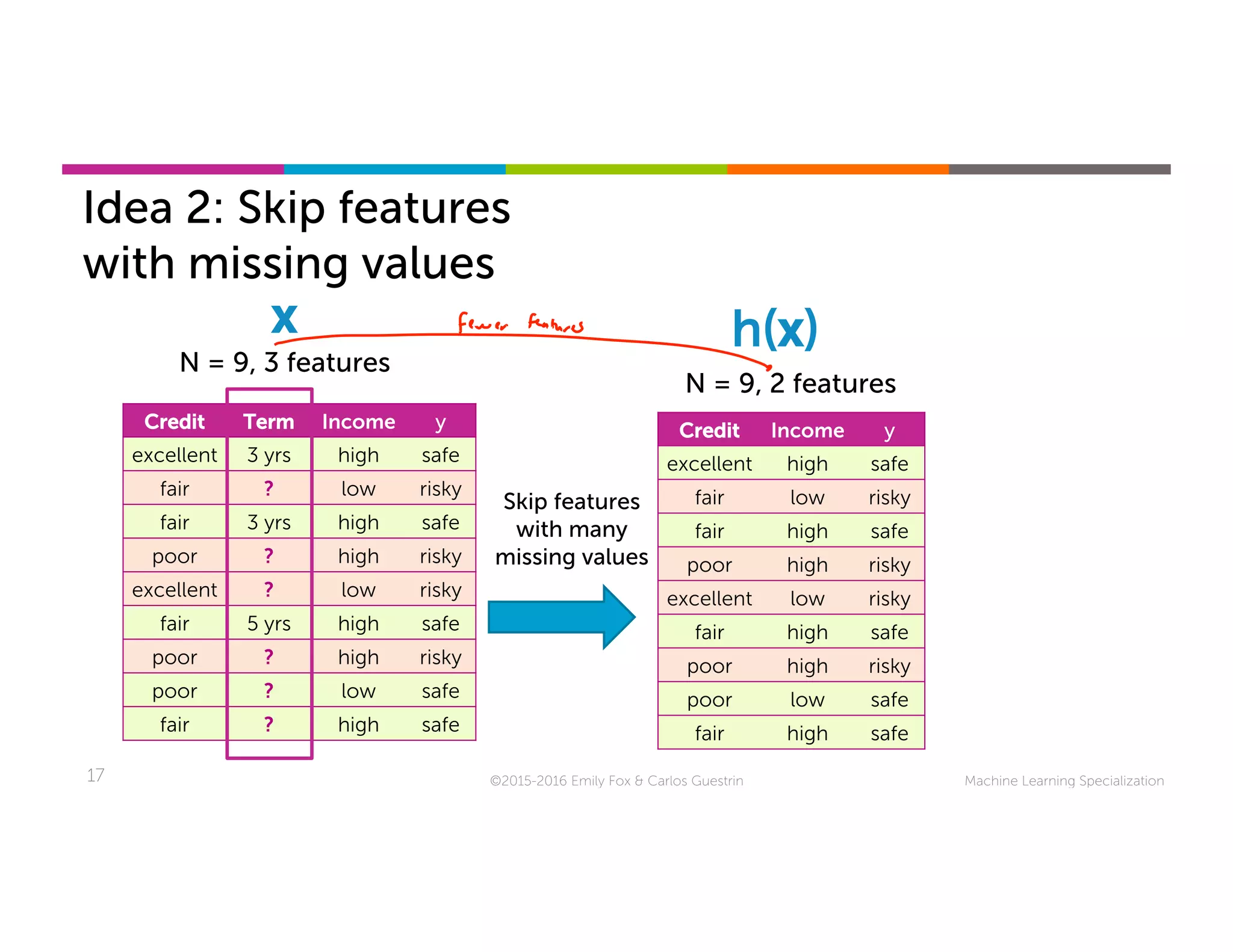
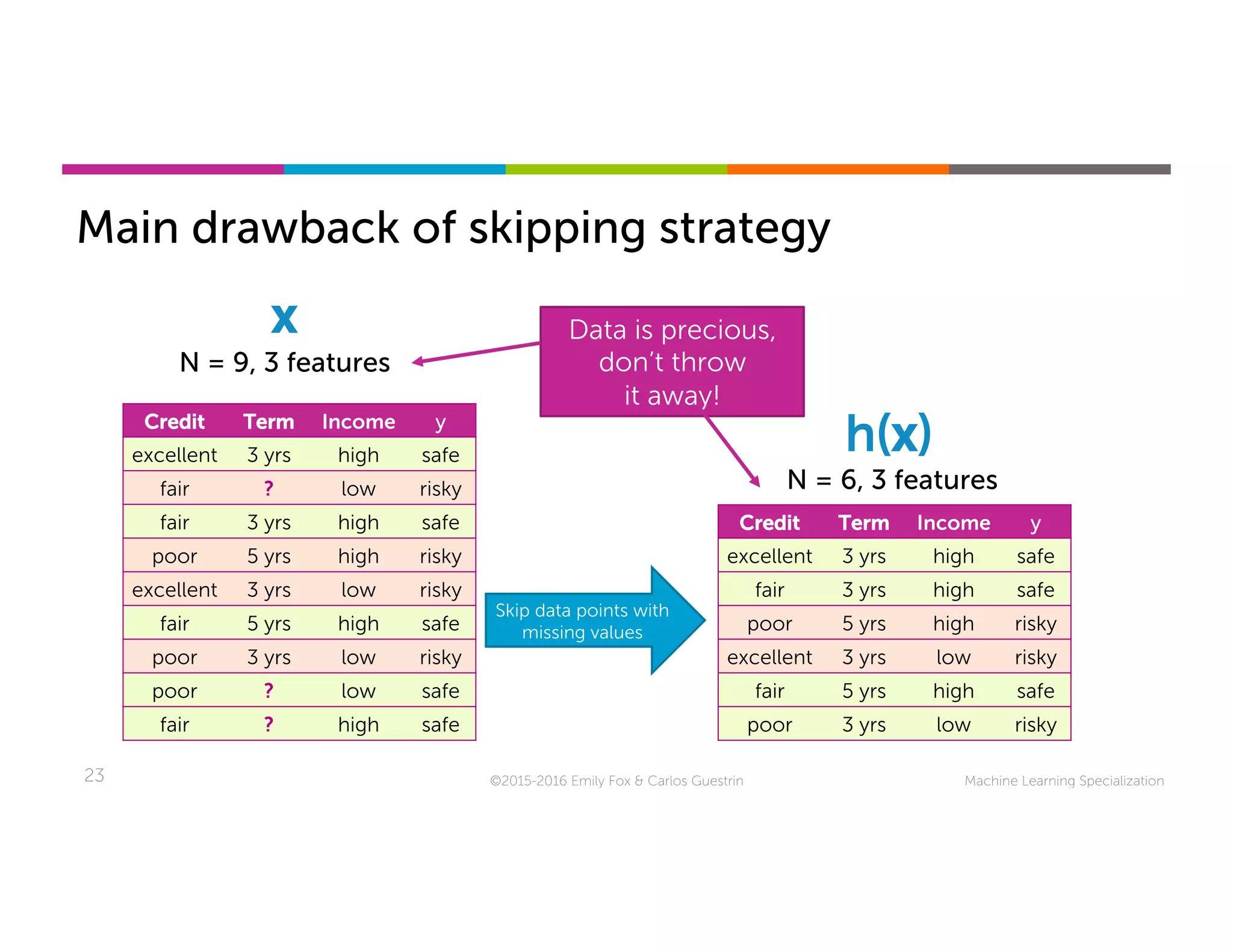
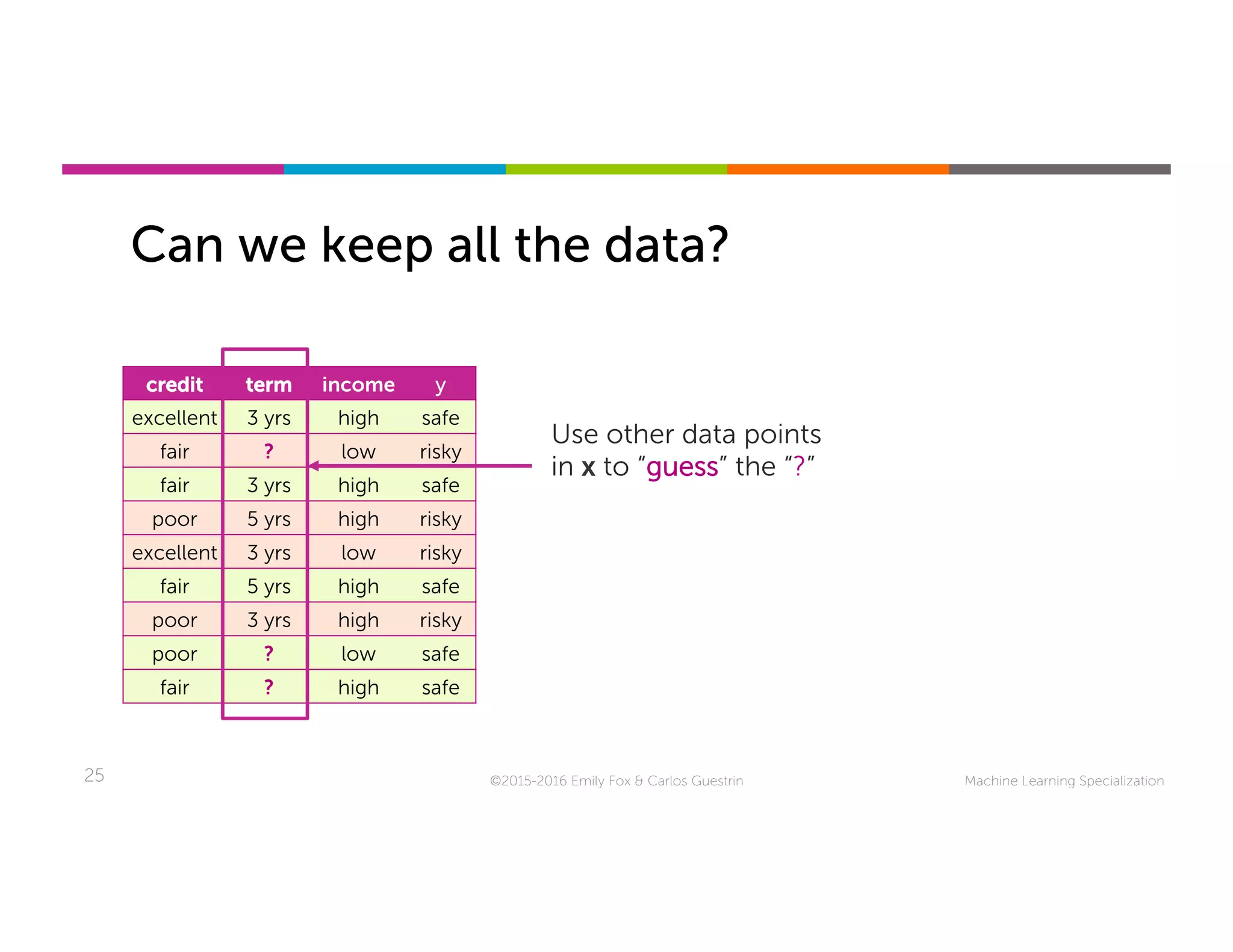
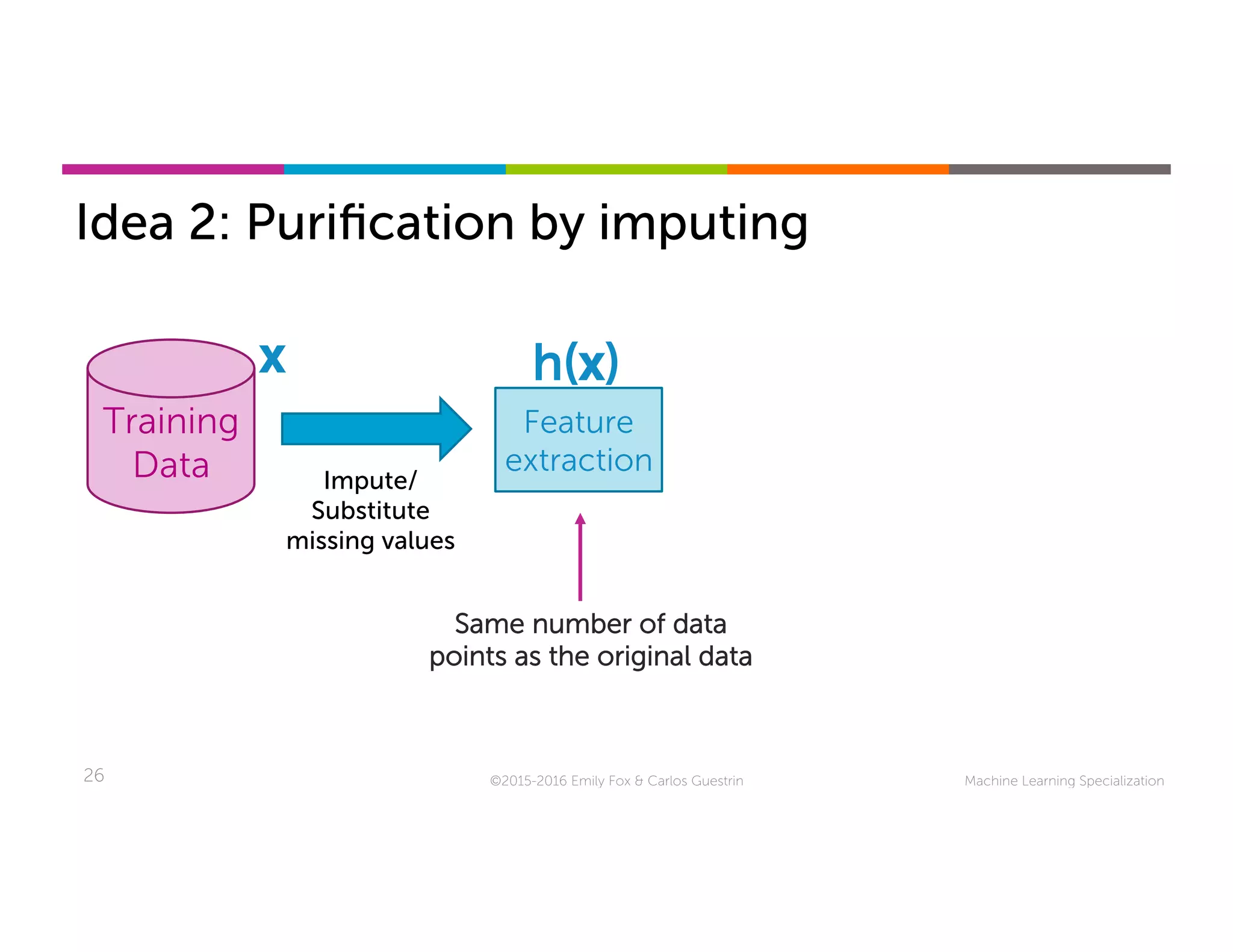
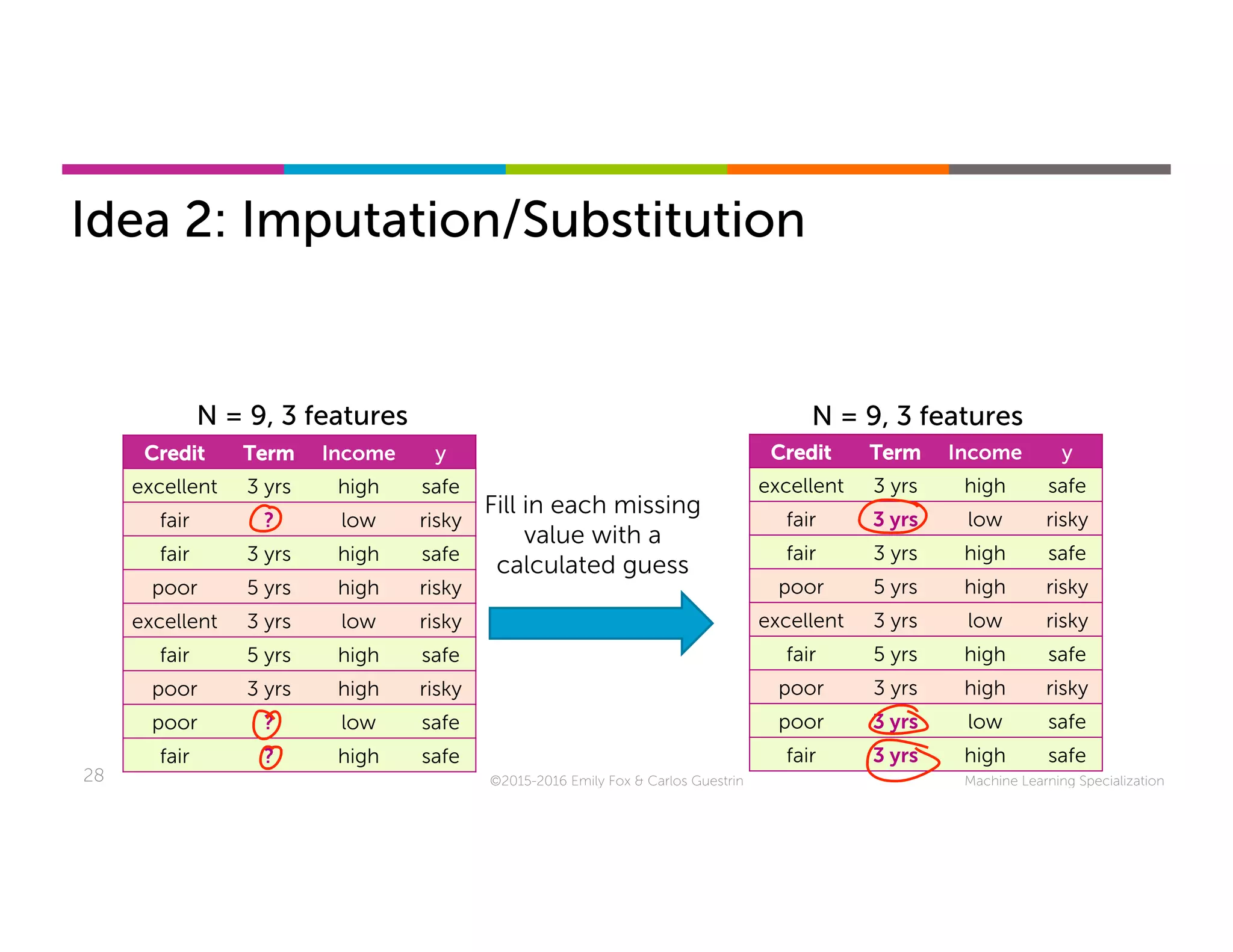
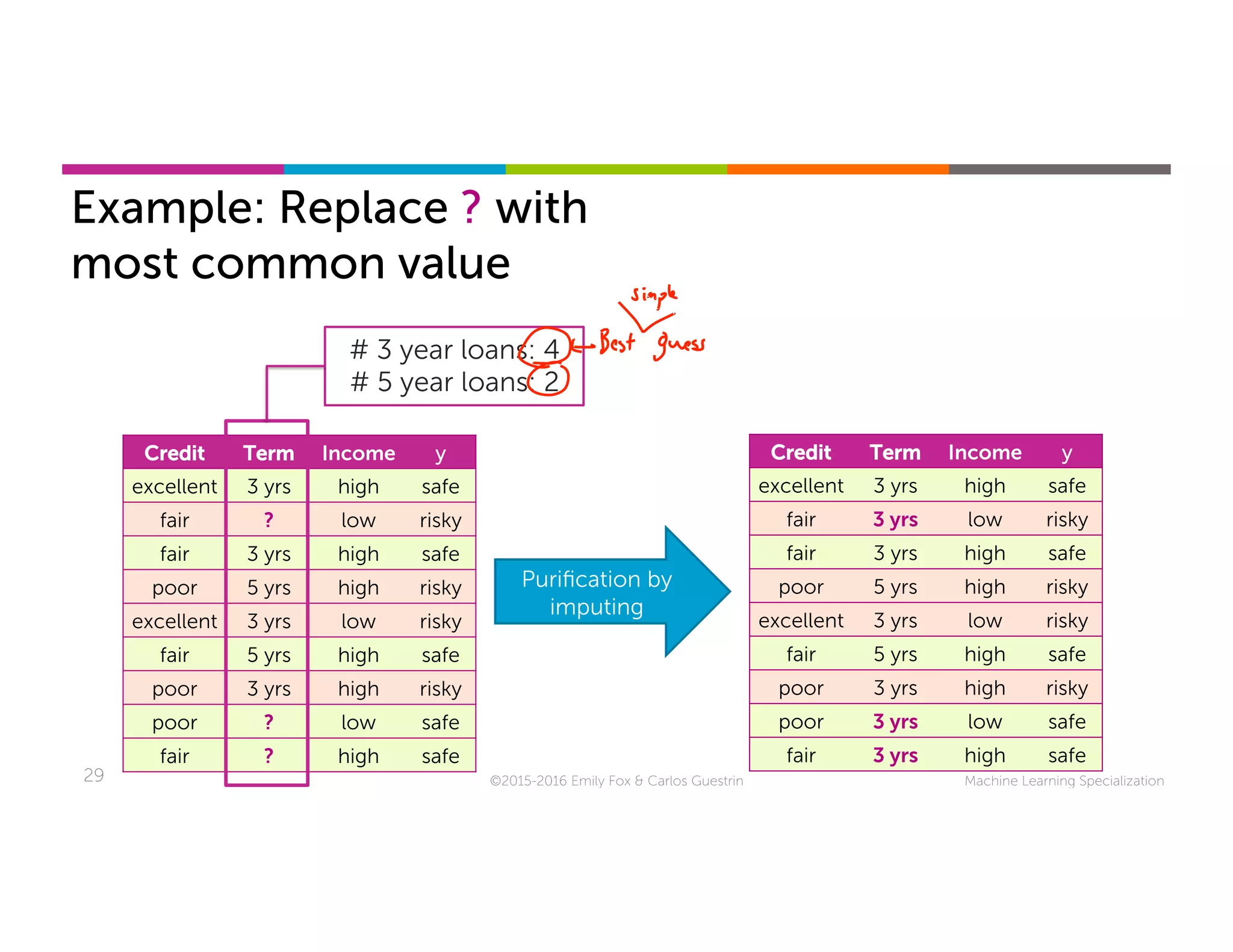
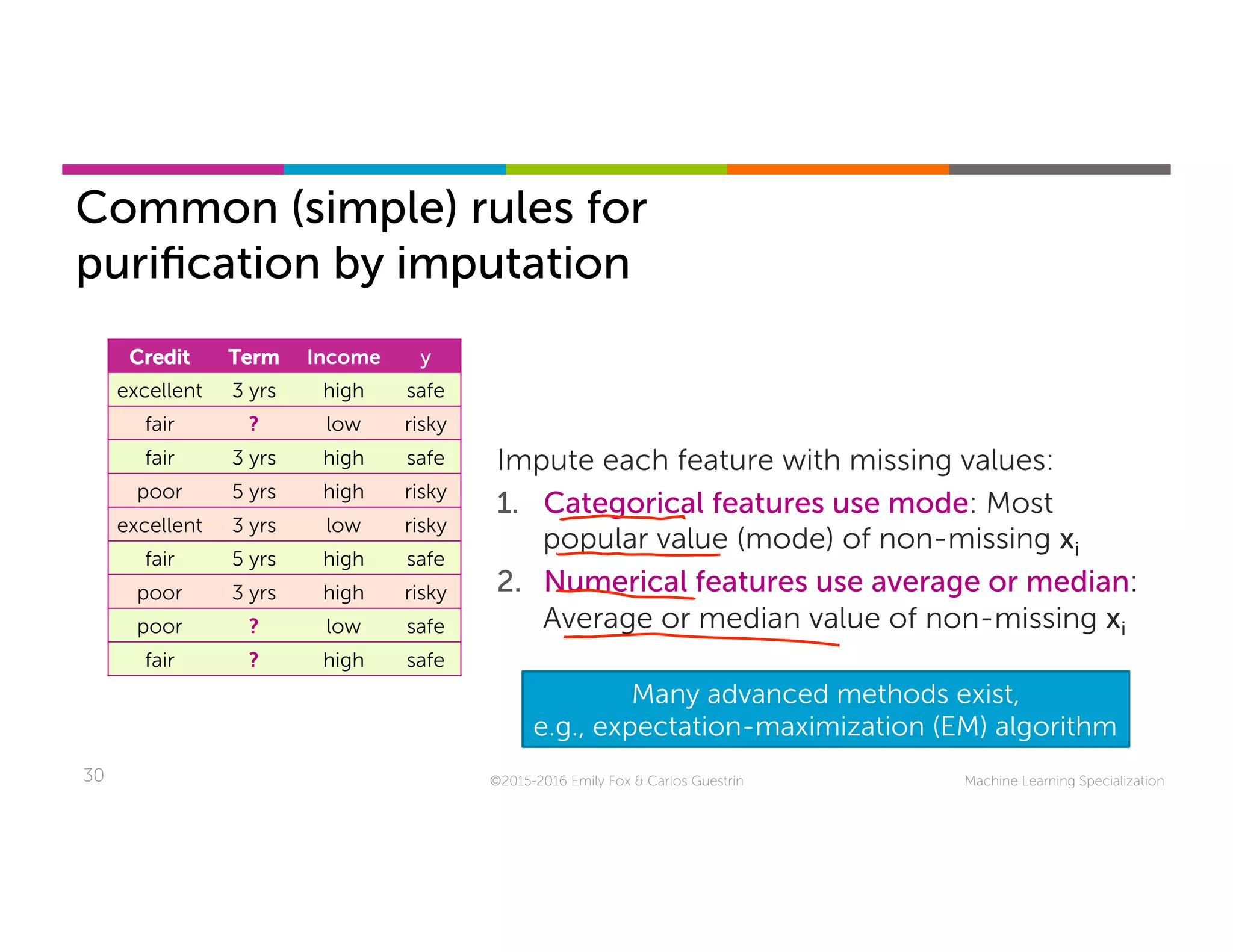
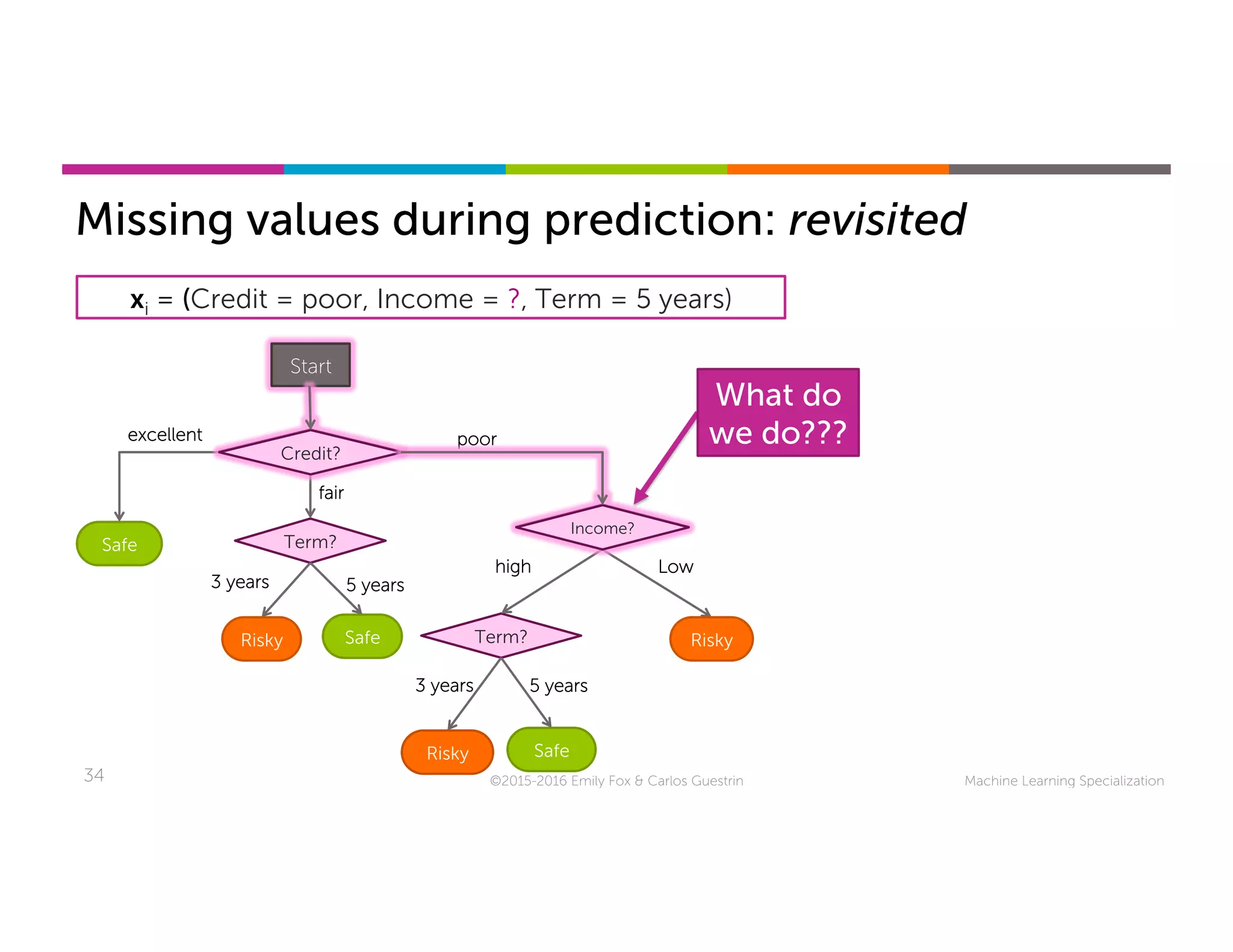
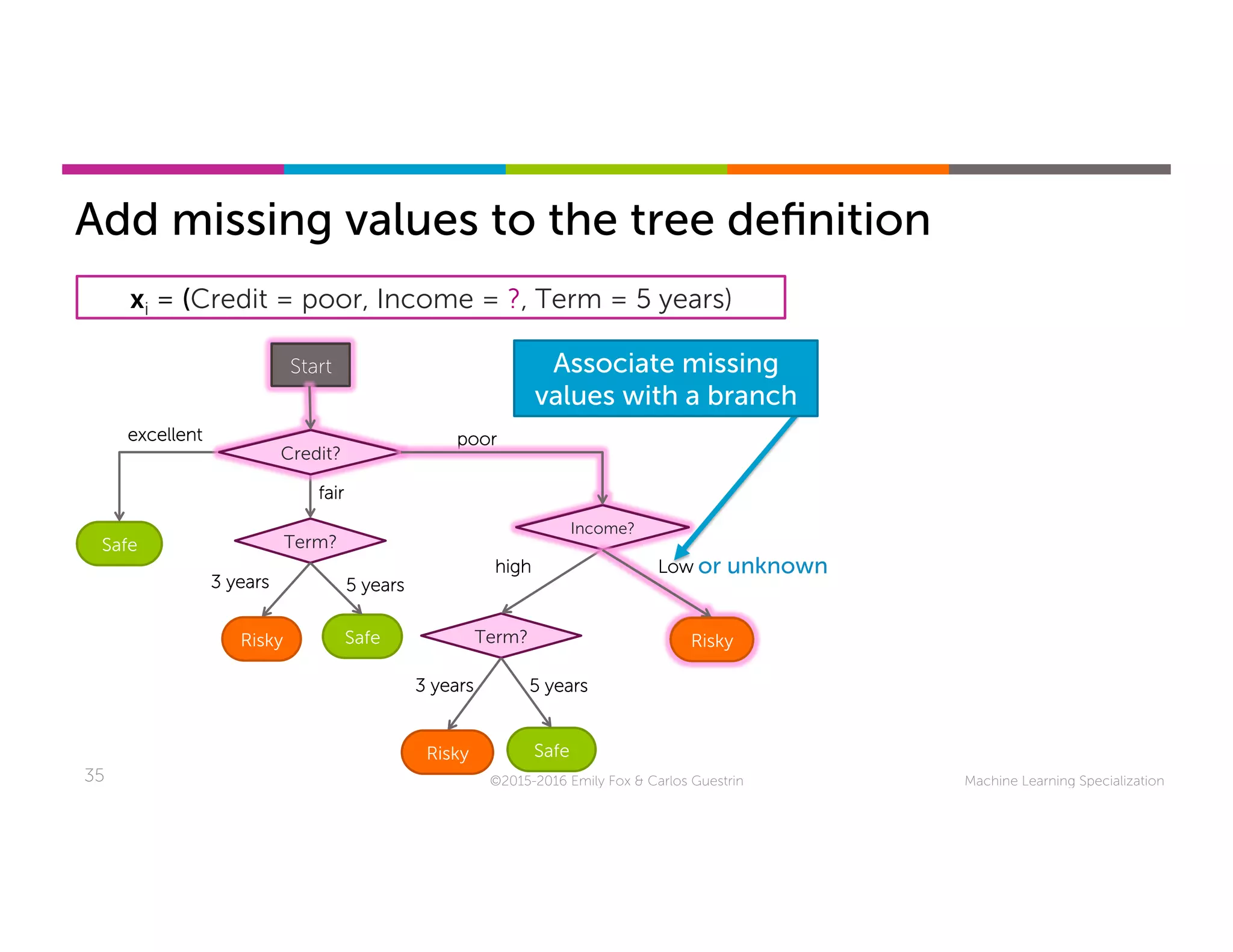
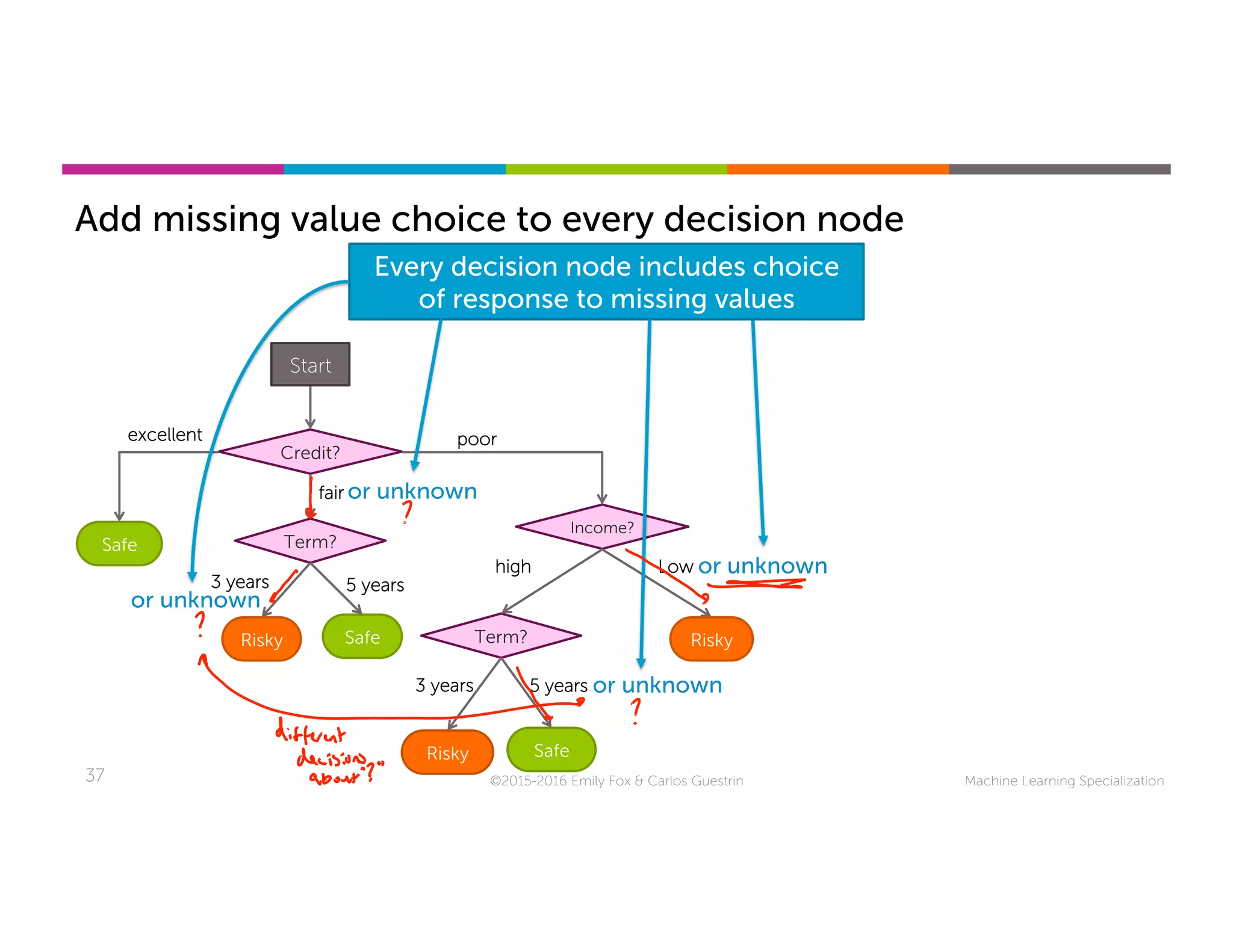
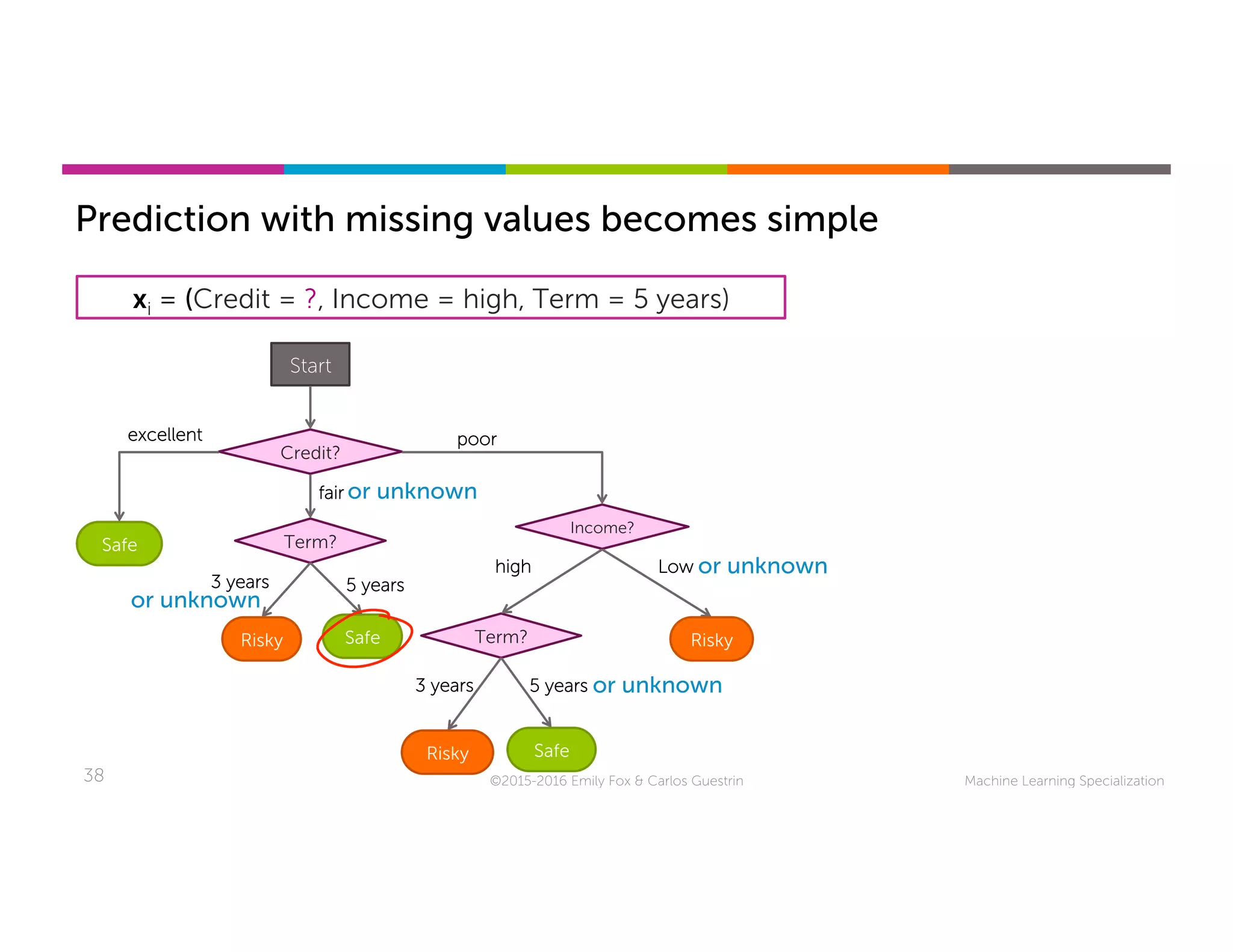
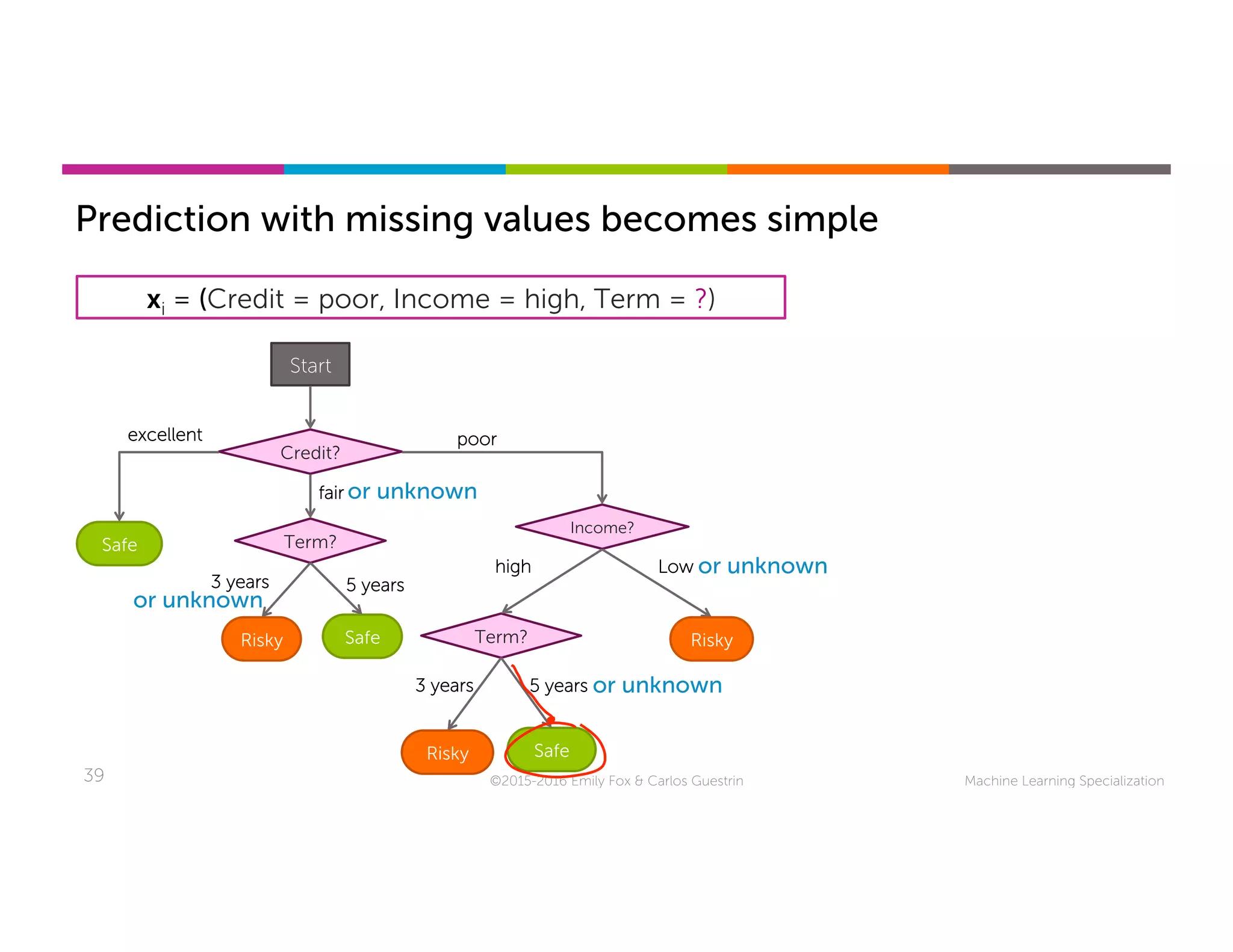
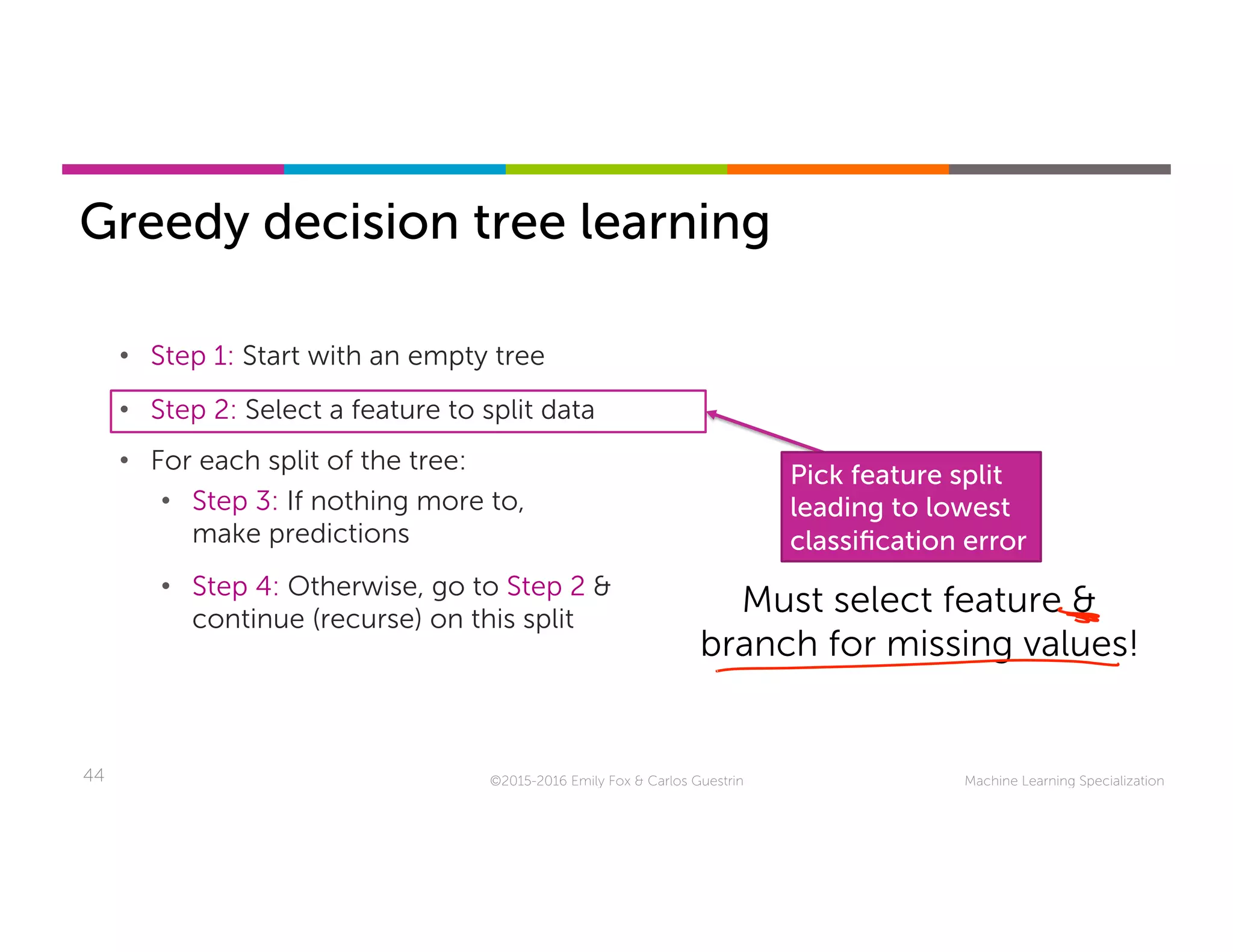
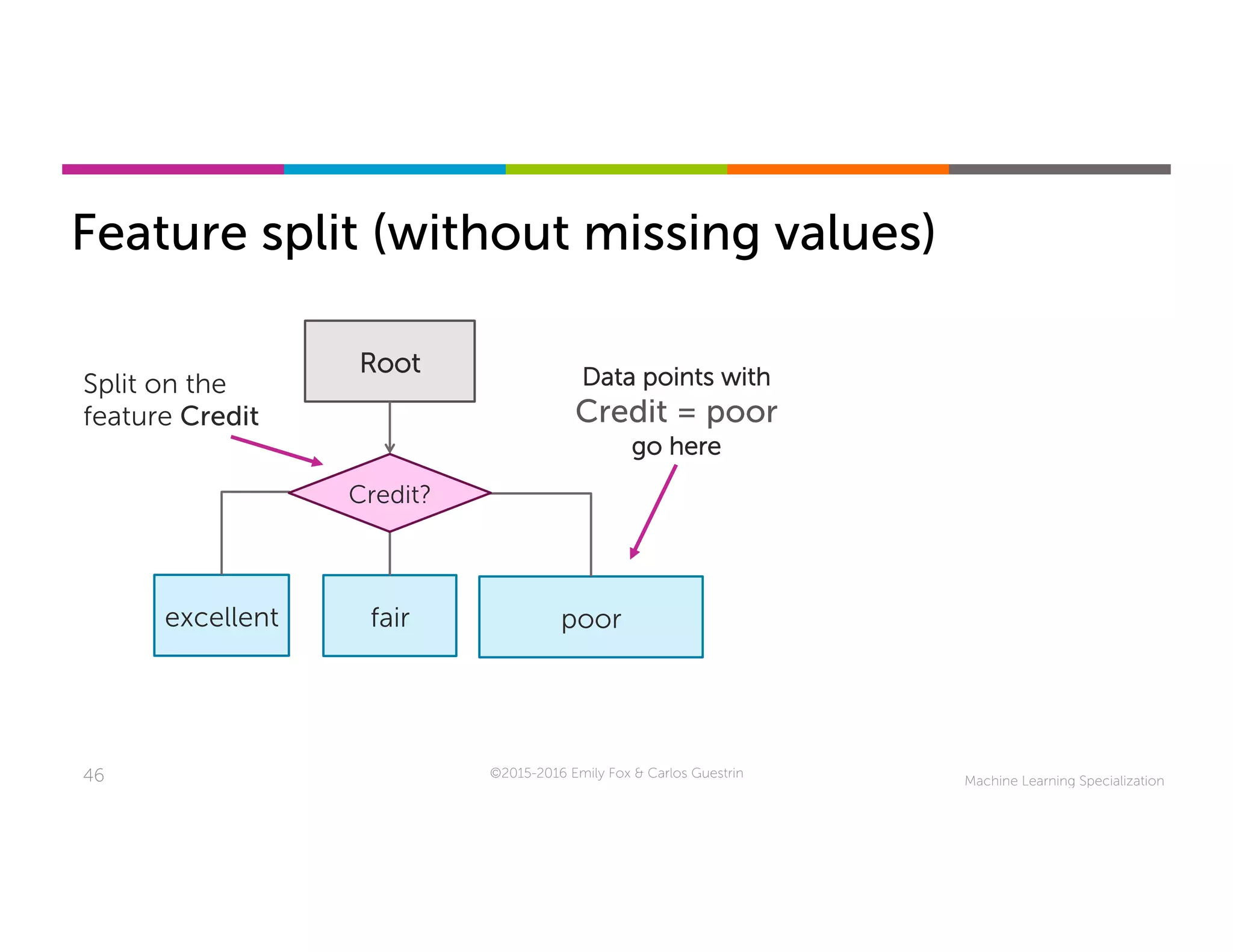
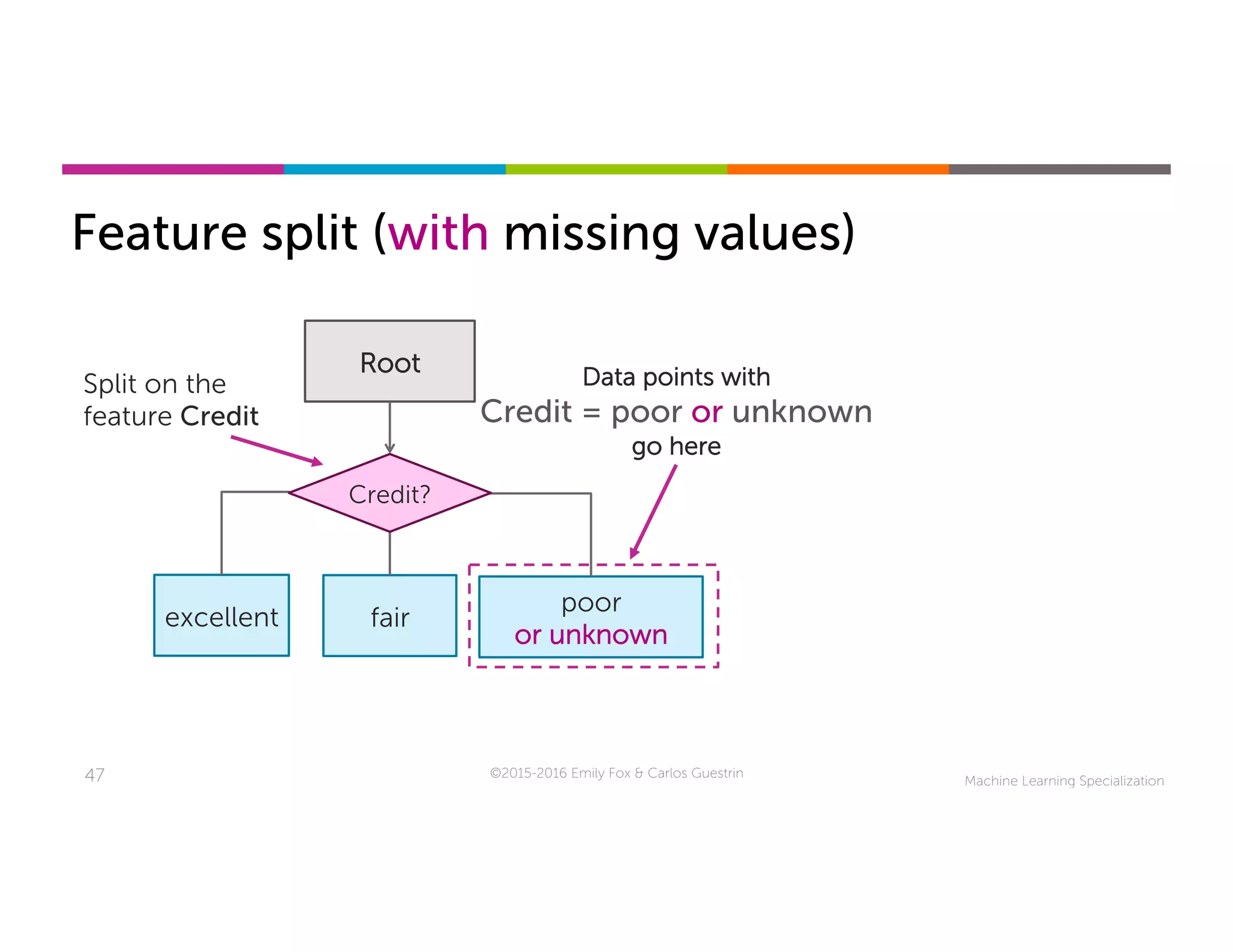
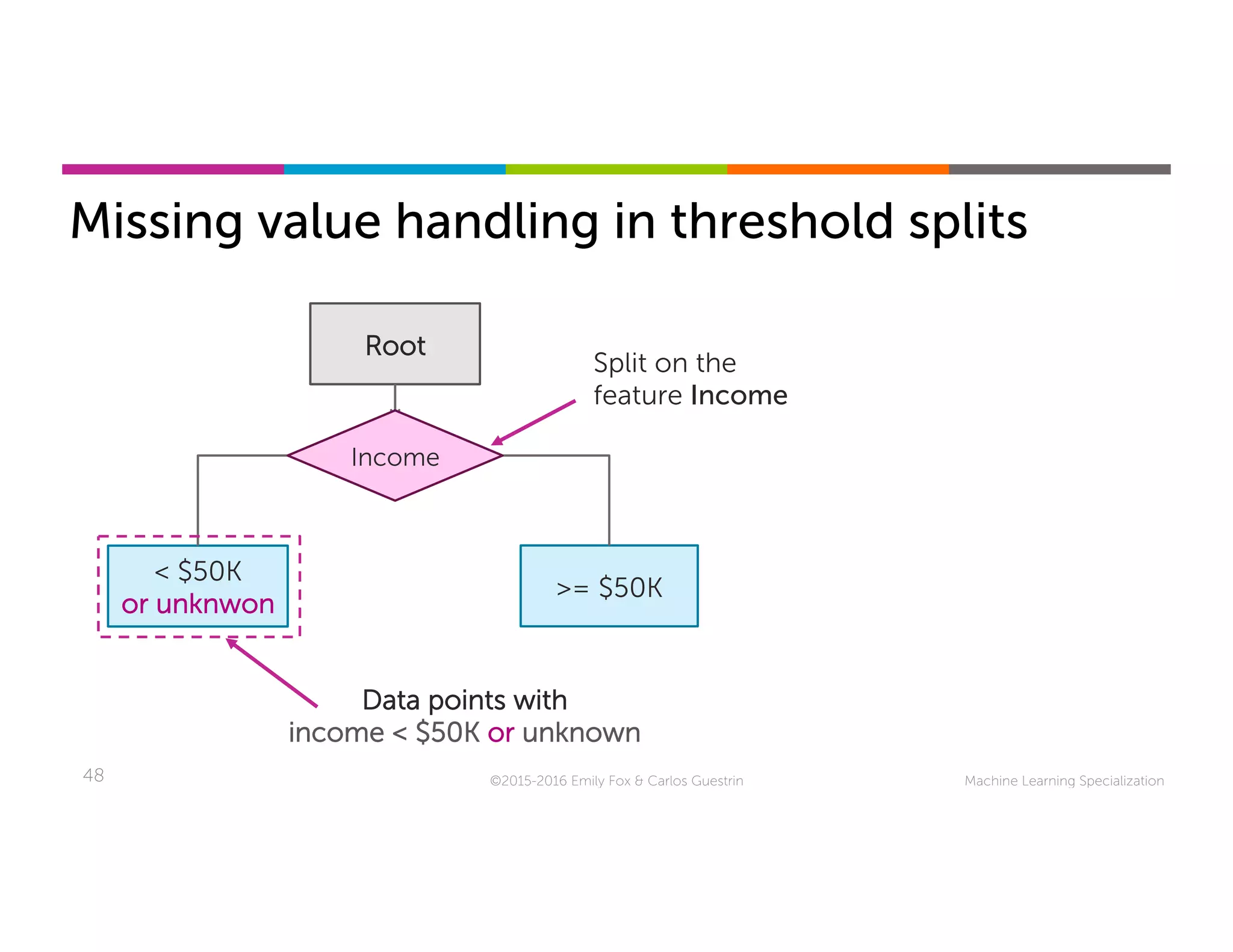
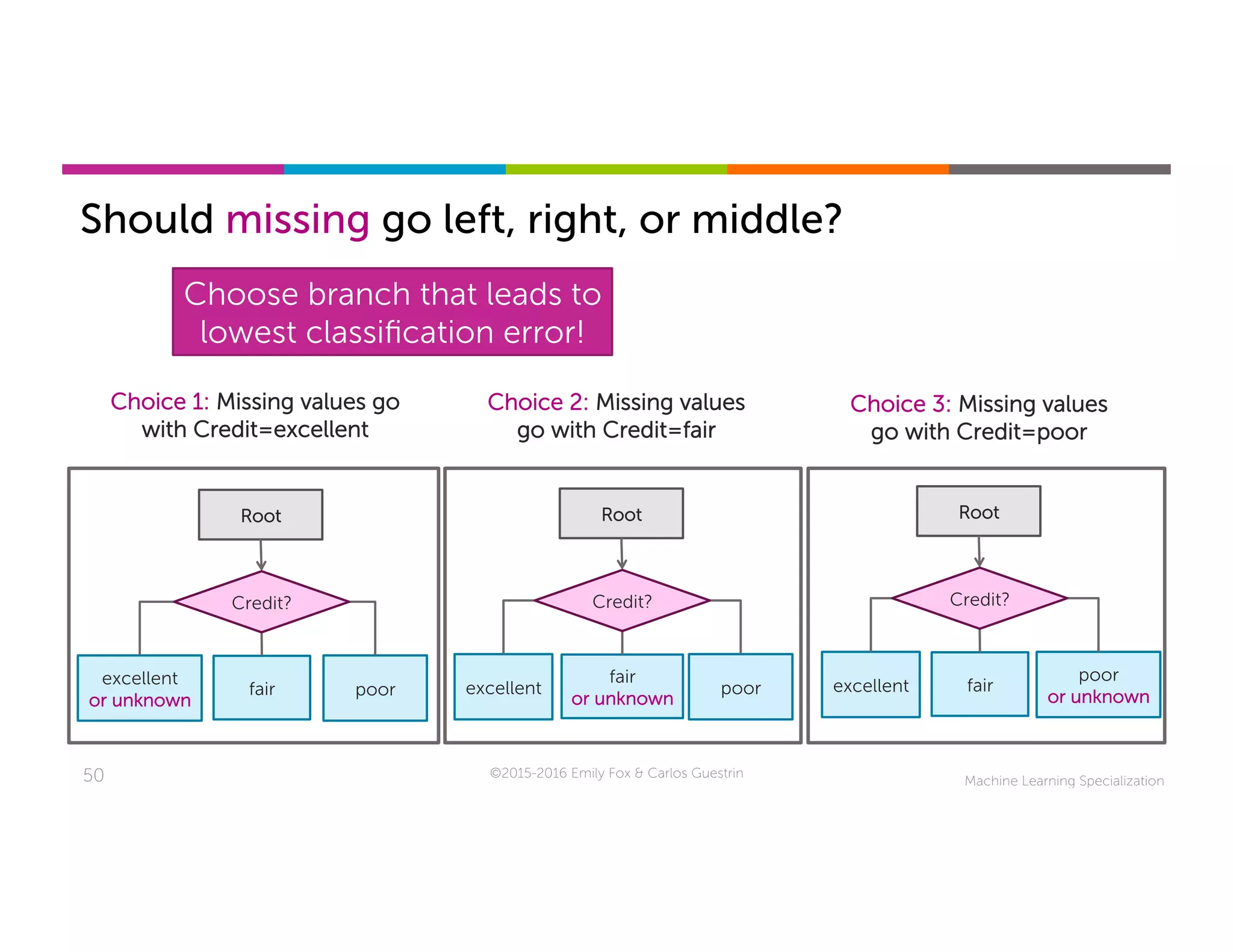
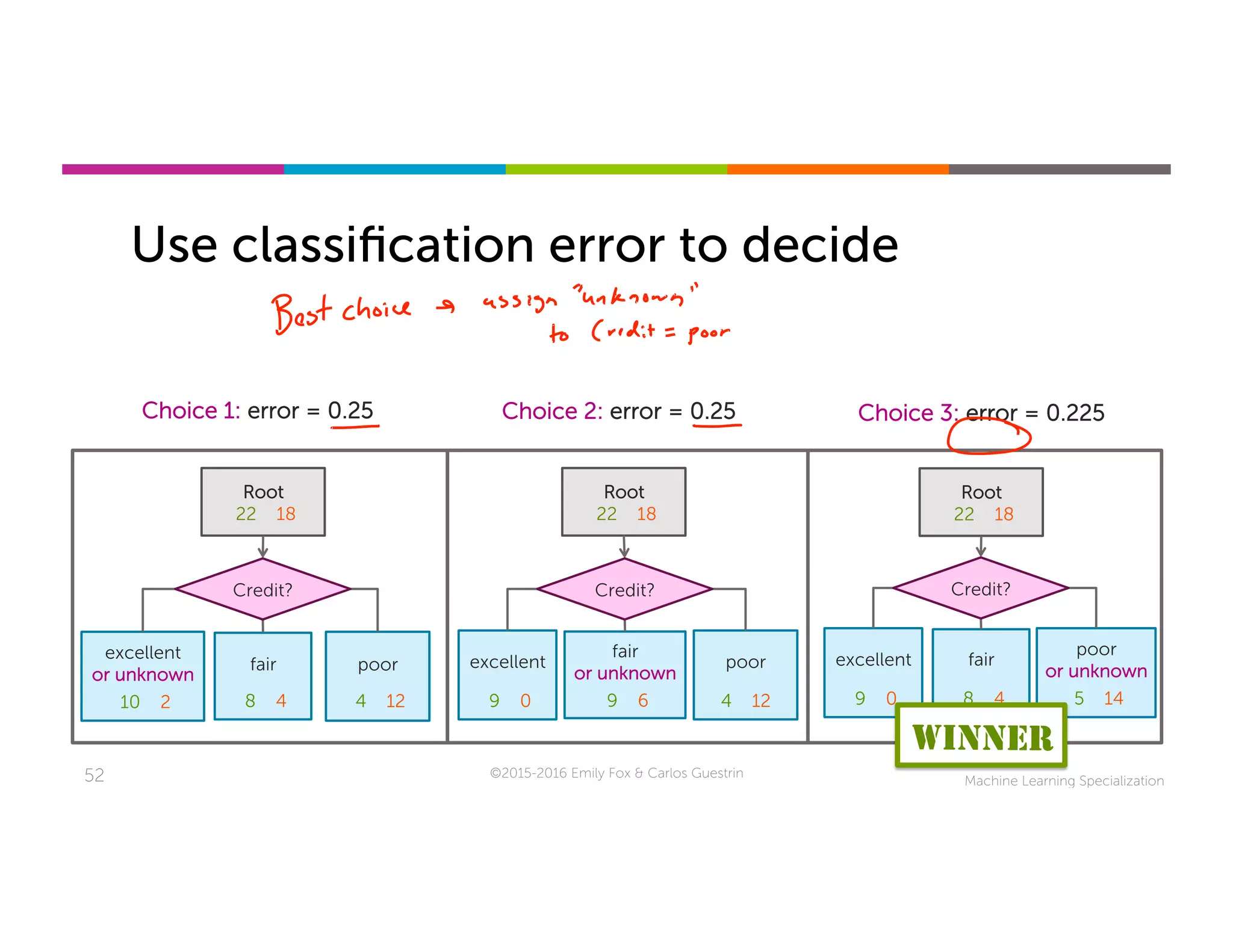
This document discusses handling missing data in machine learning models. It presents three main strategies: 1) purification by skipping, which removes data points or features with missing values; 2) purification by imputing, which replaces missing values using techniques like mean imputation; and 3) adapting the learning algorithm to be robust to missing values, such as modifying decision trees to include branches for handling missing data. The document explores techniques within each strategy and discusses their pros and cons.