Download as PDF, PPTX





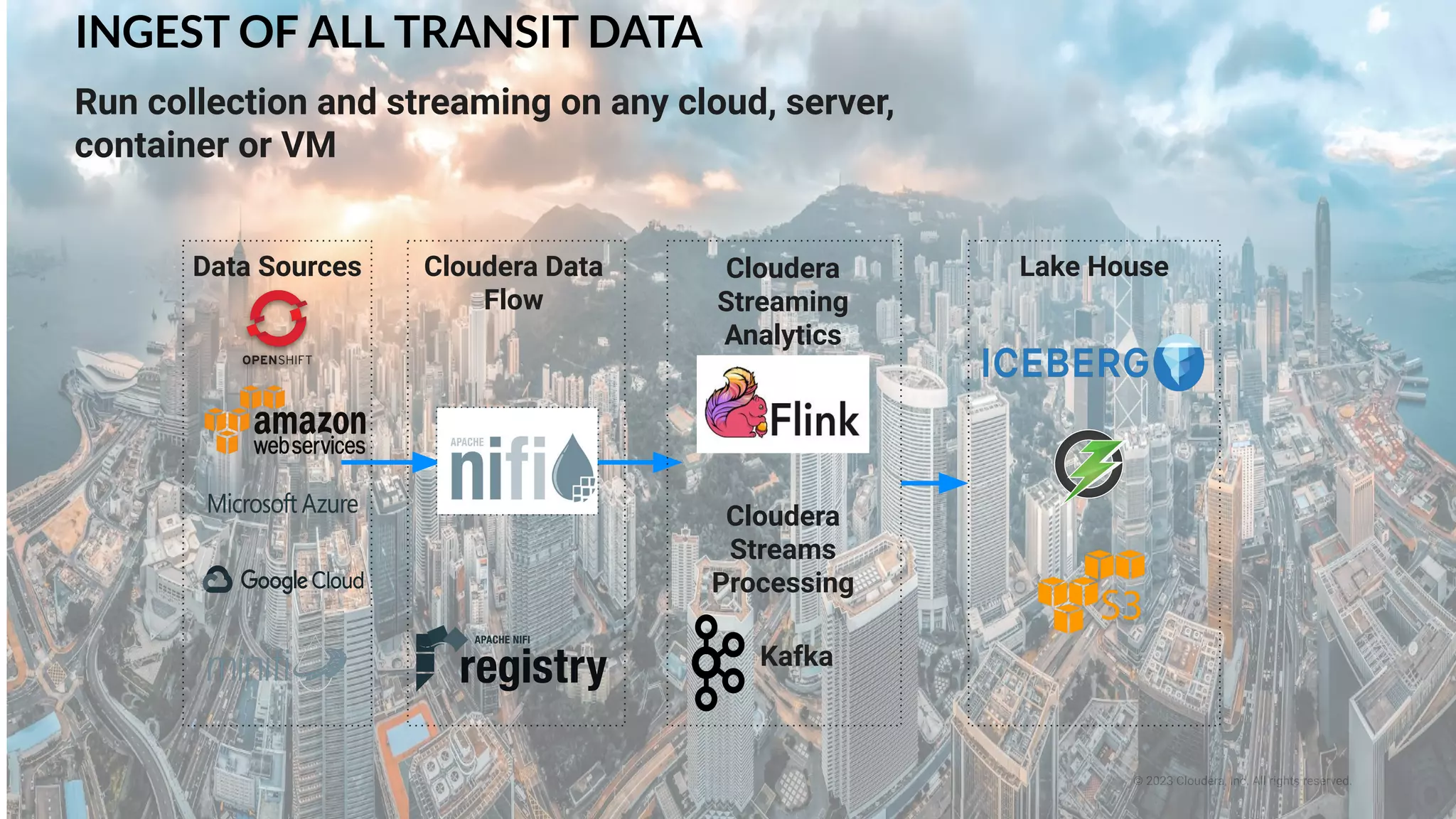
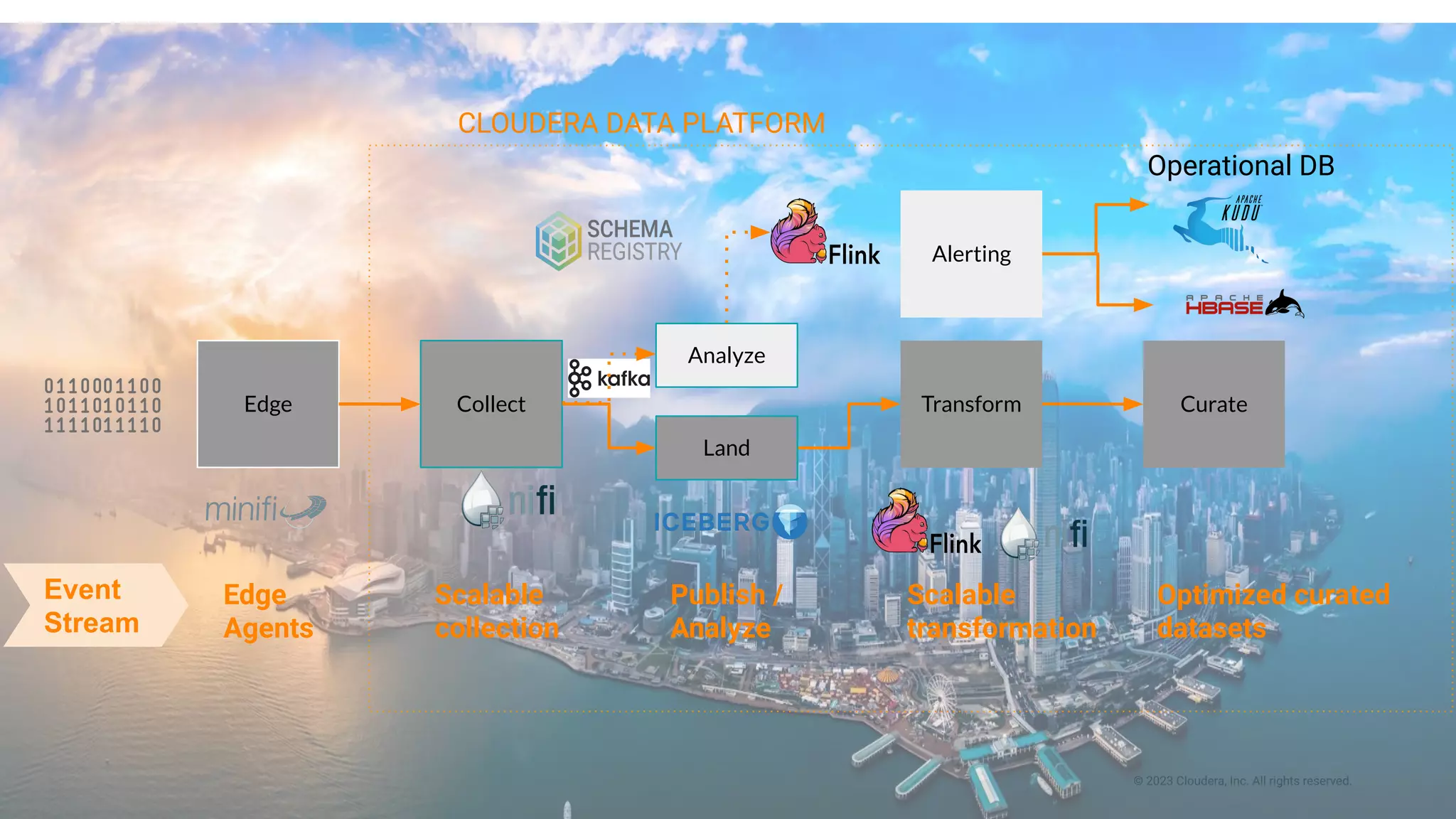

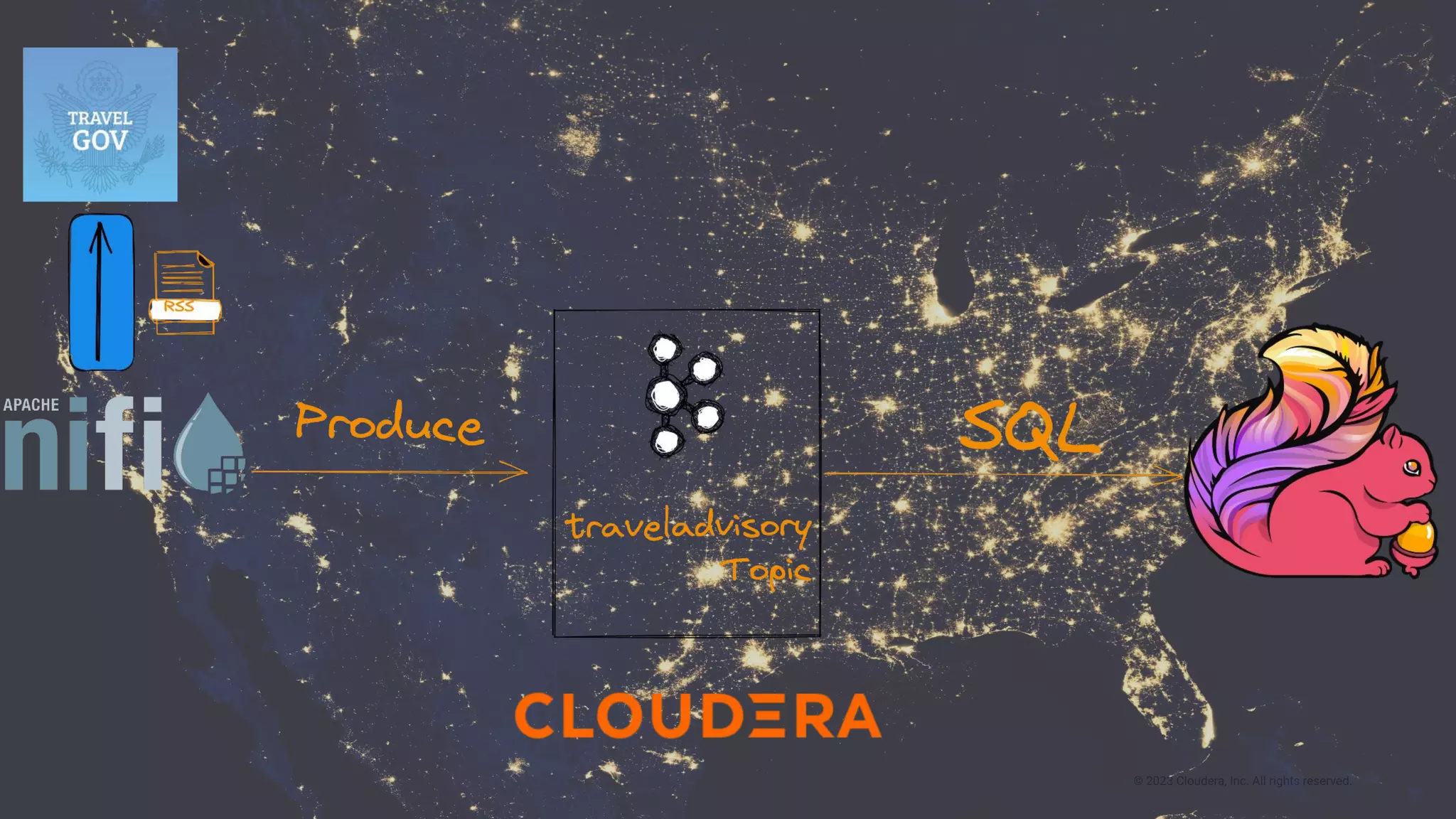

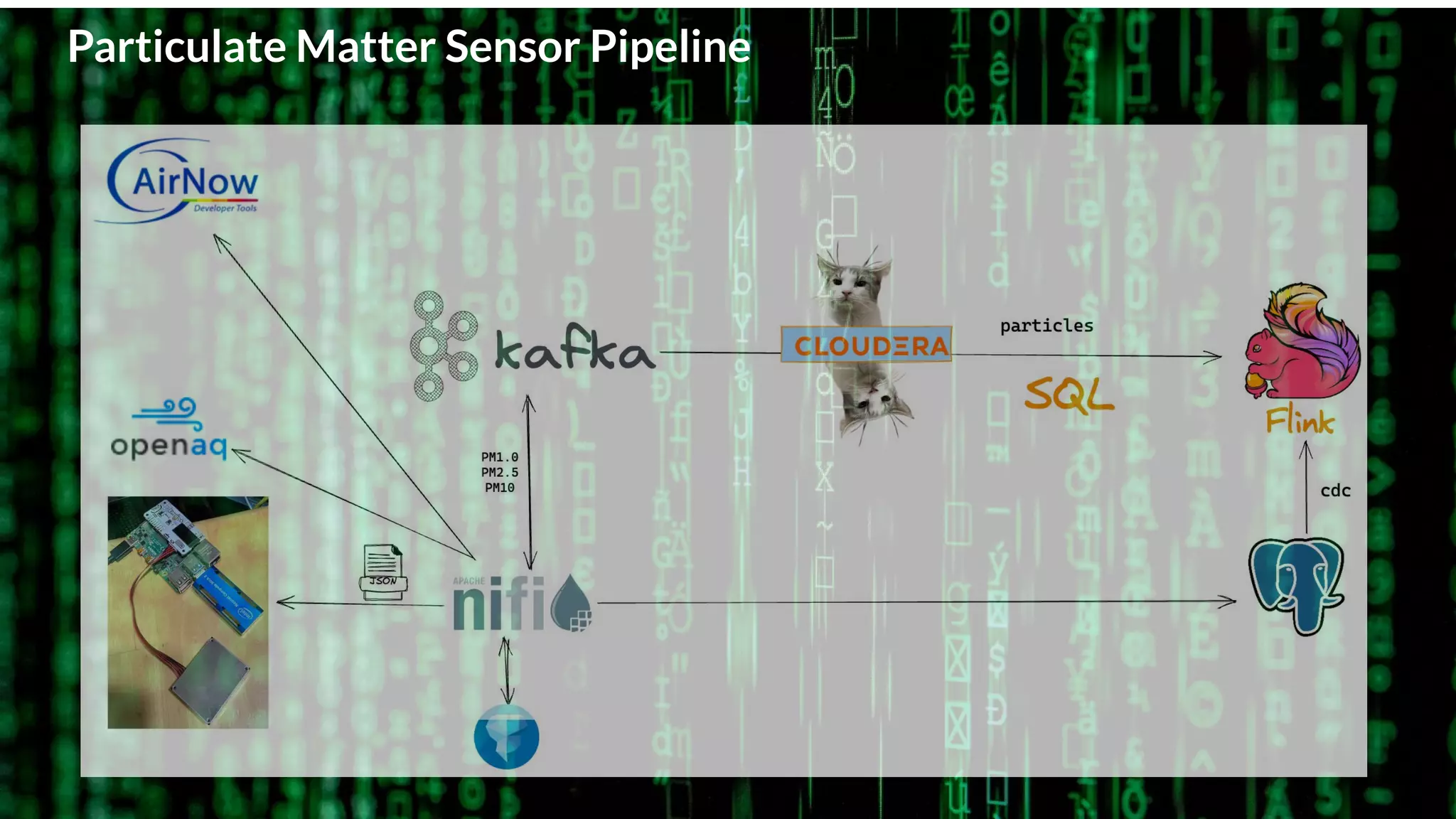

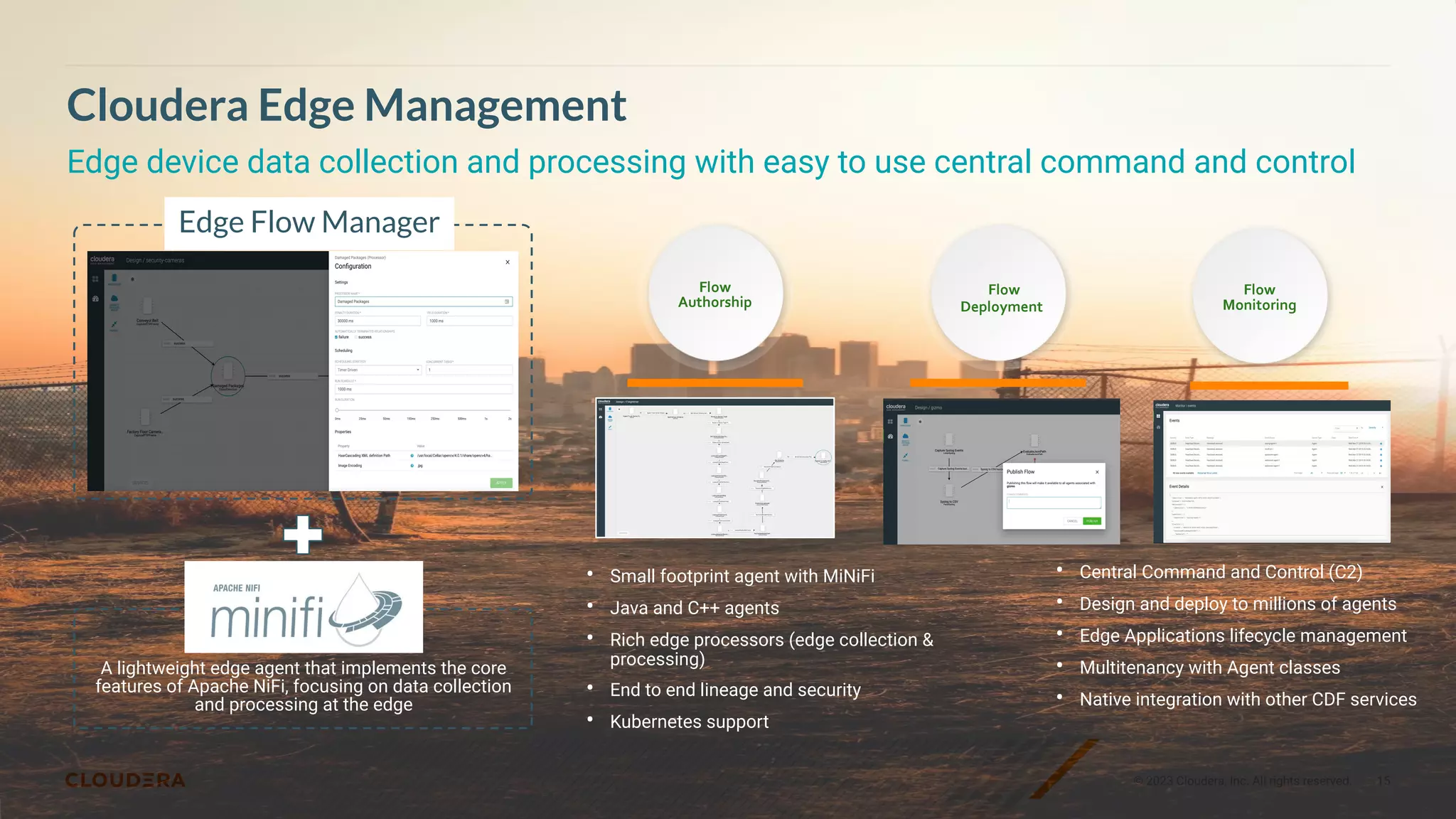

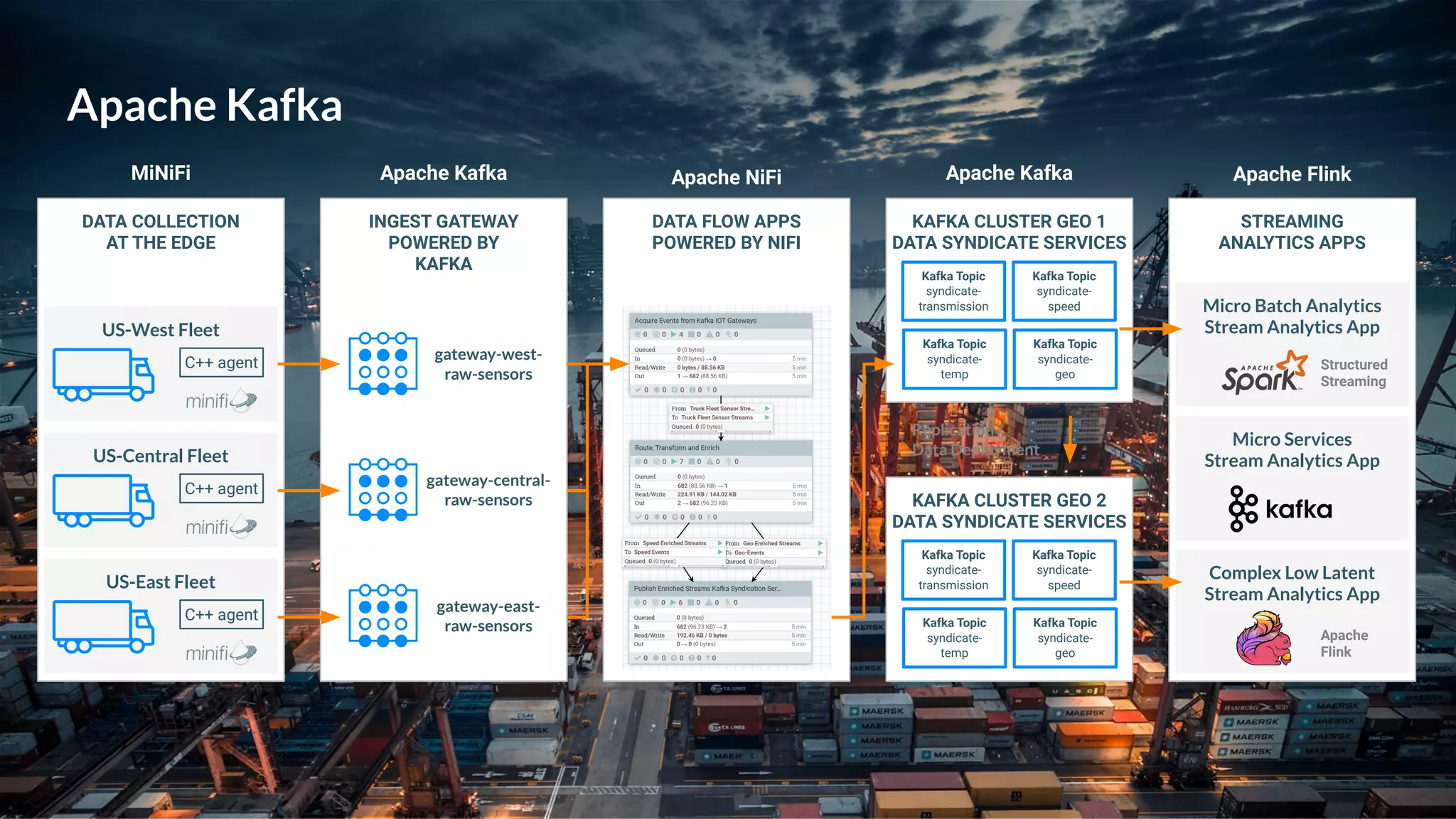

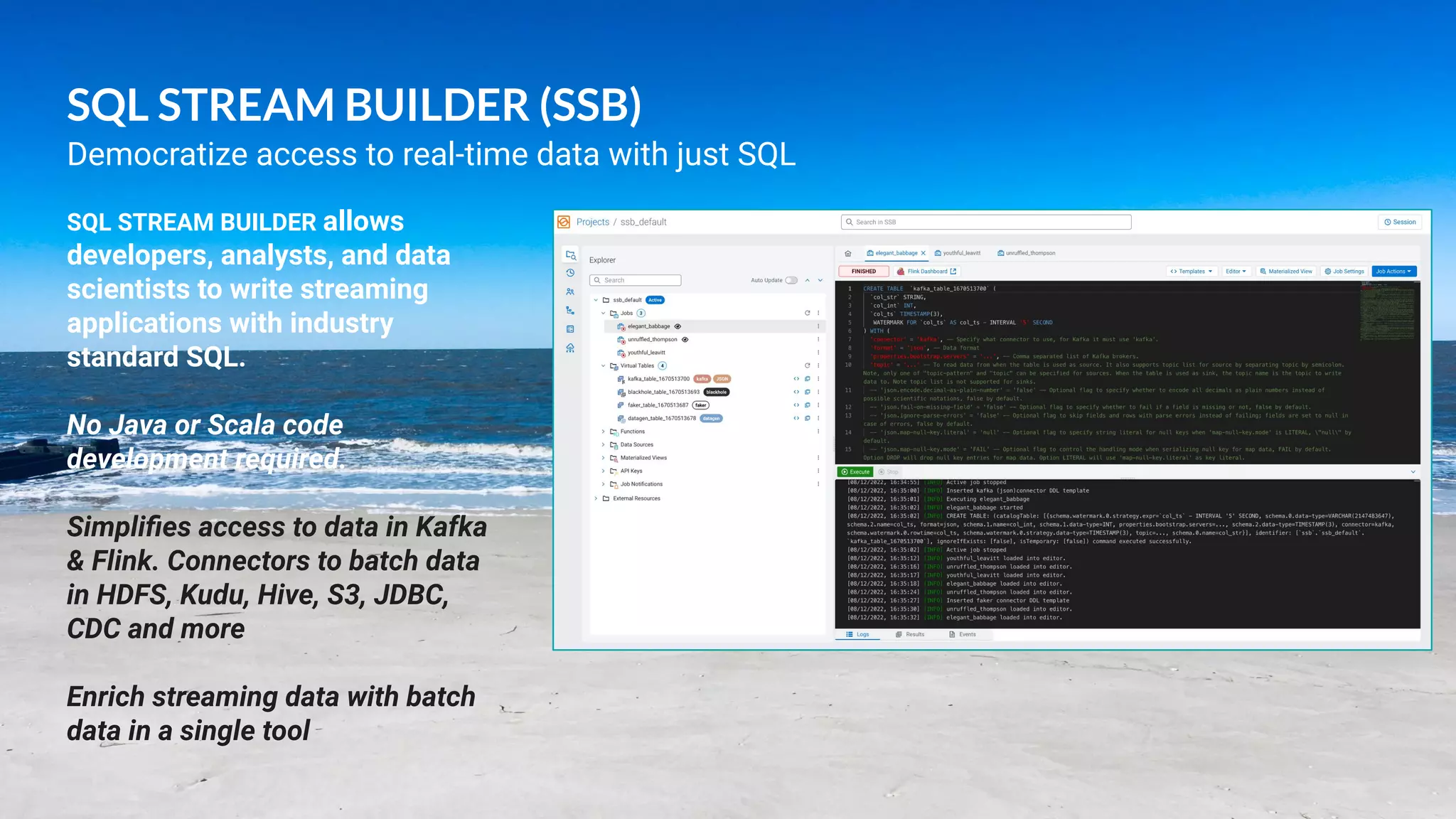
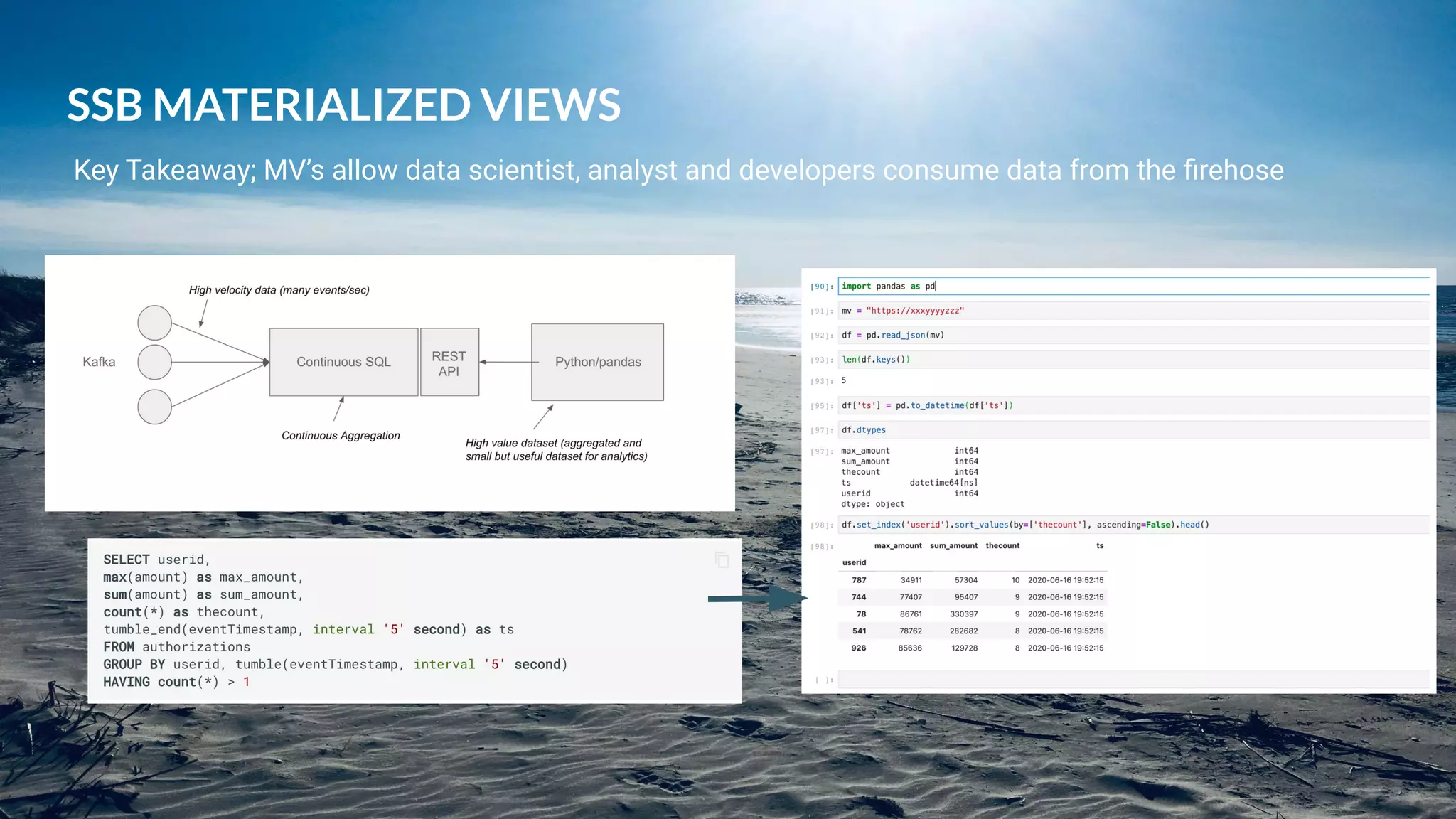
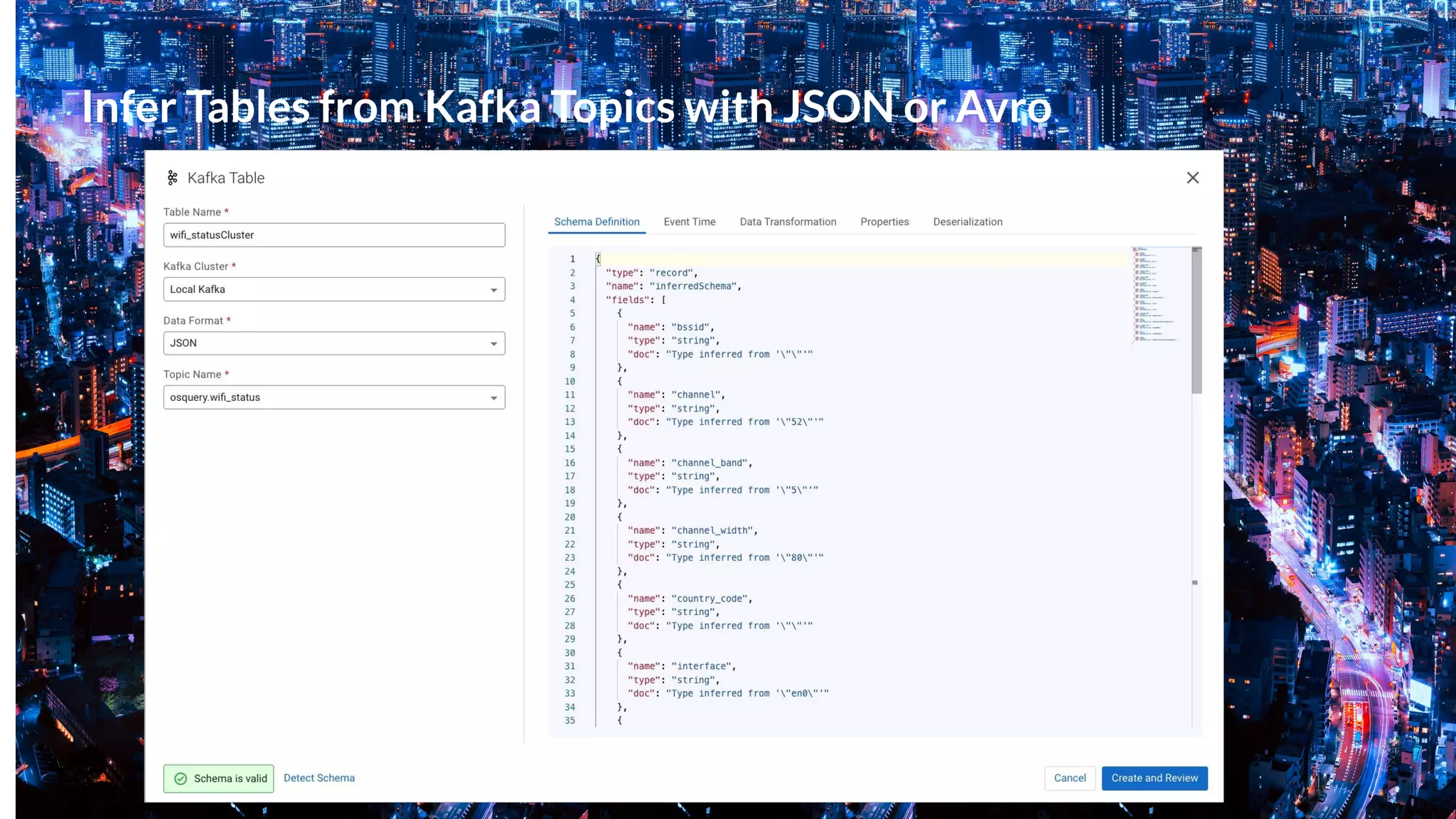

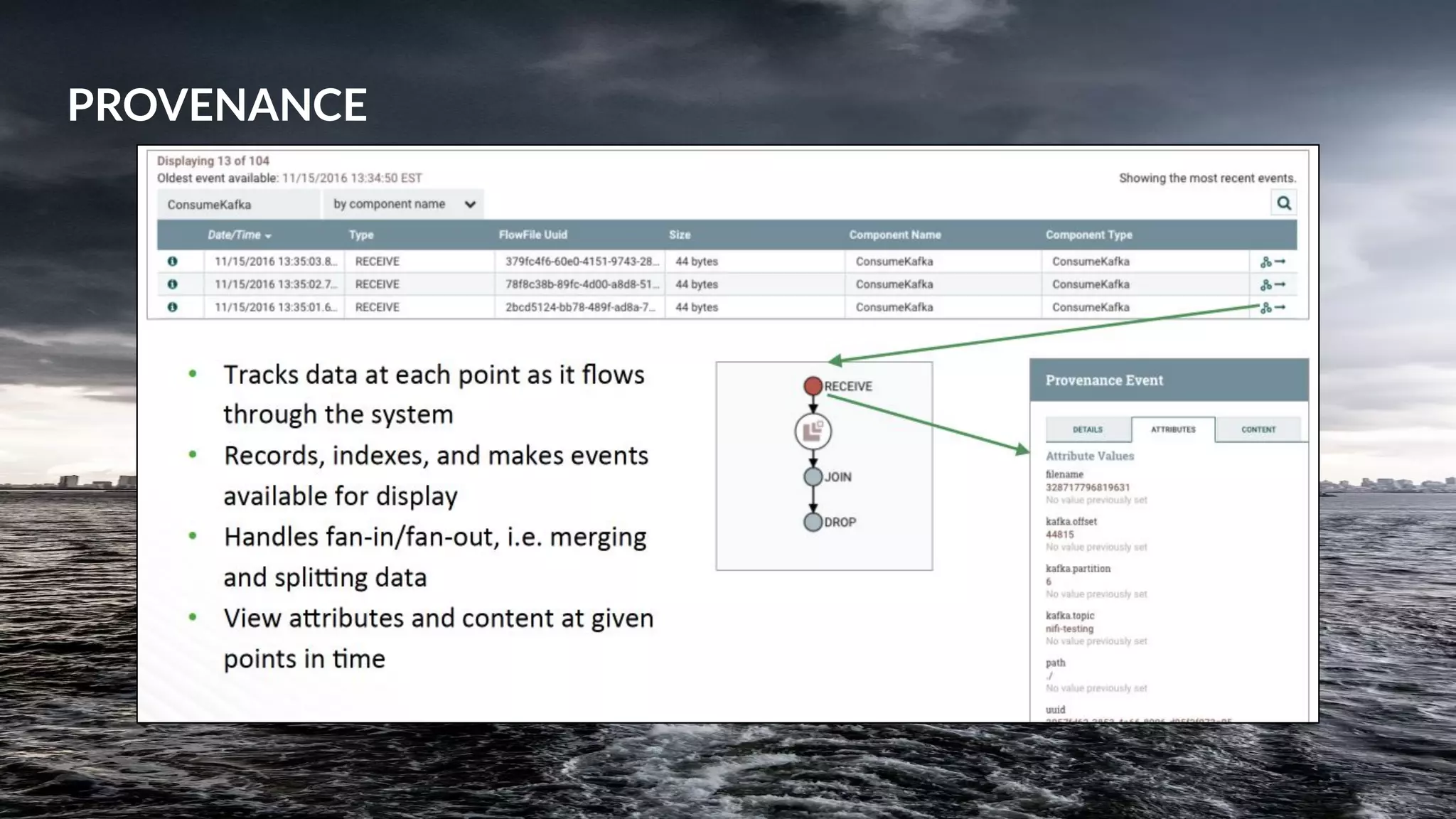

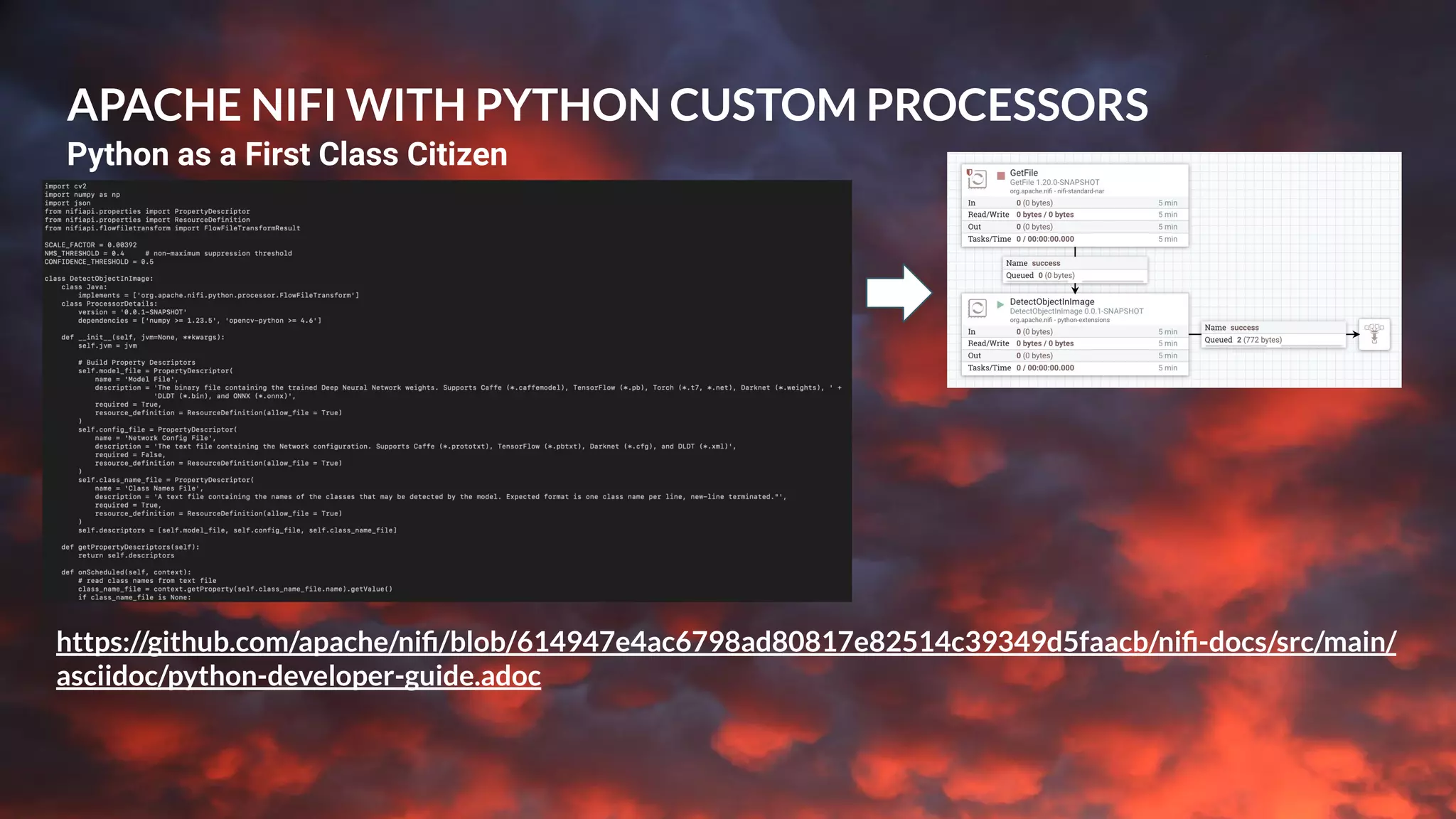
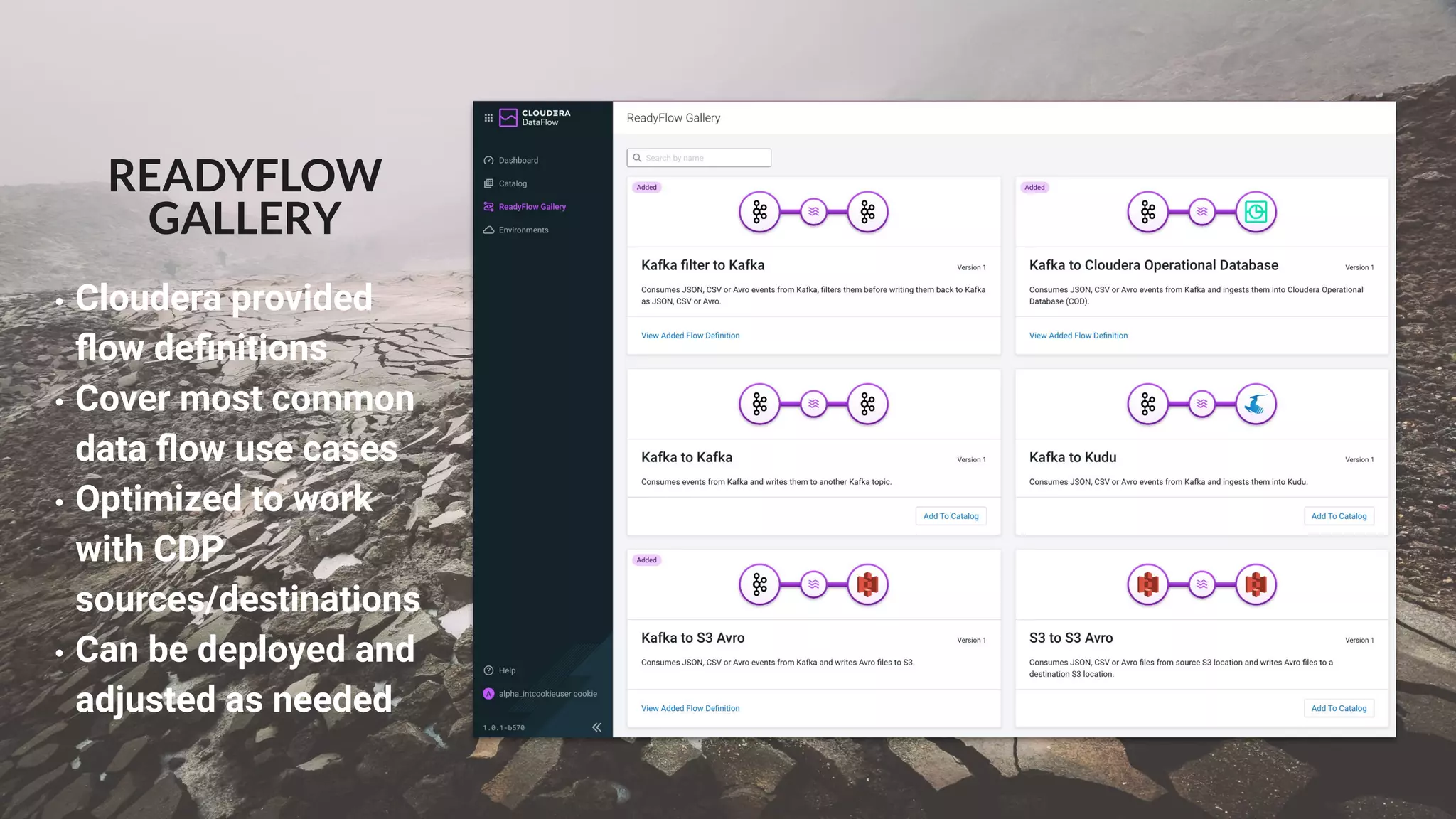
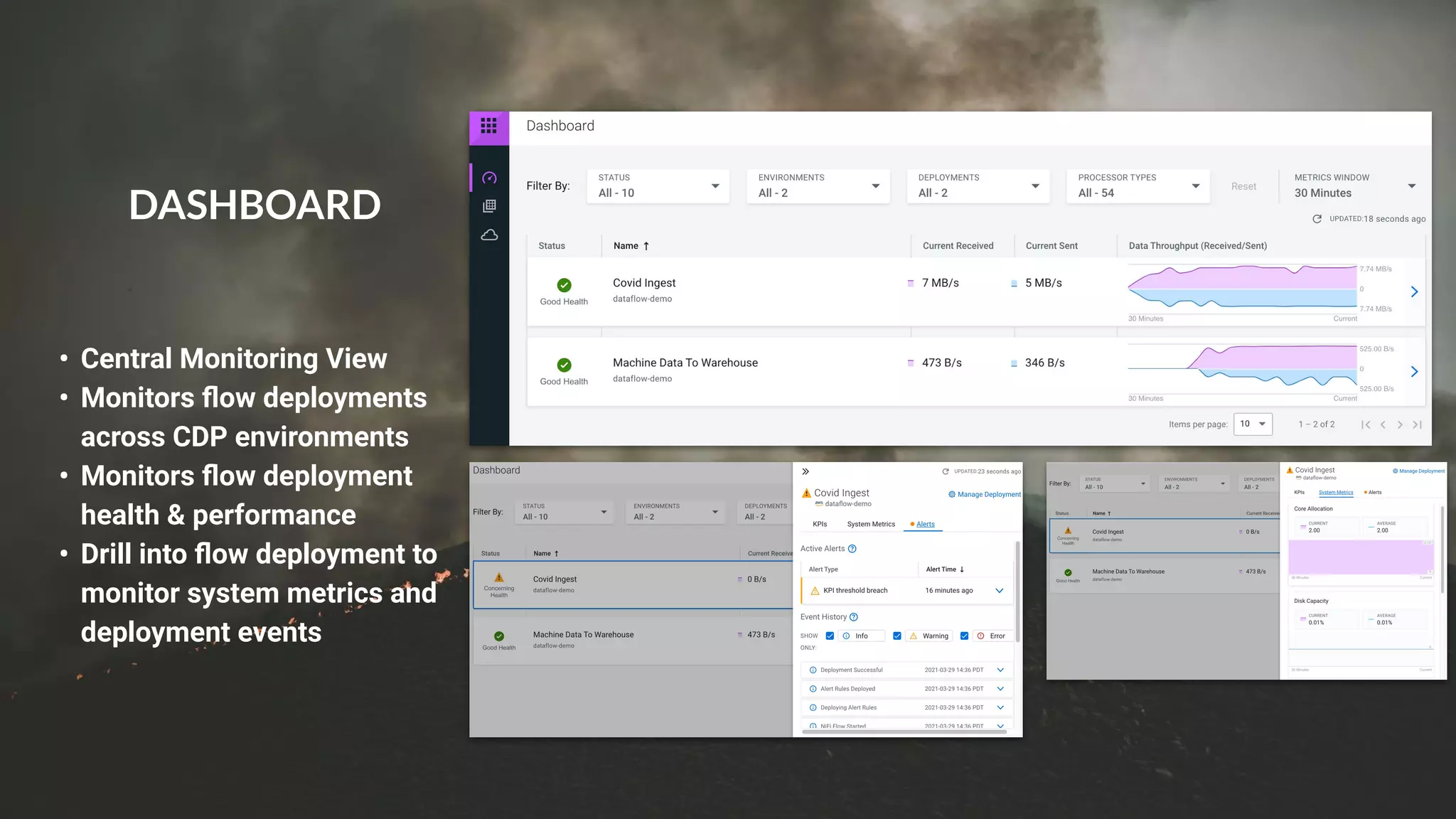










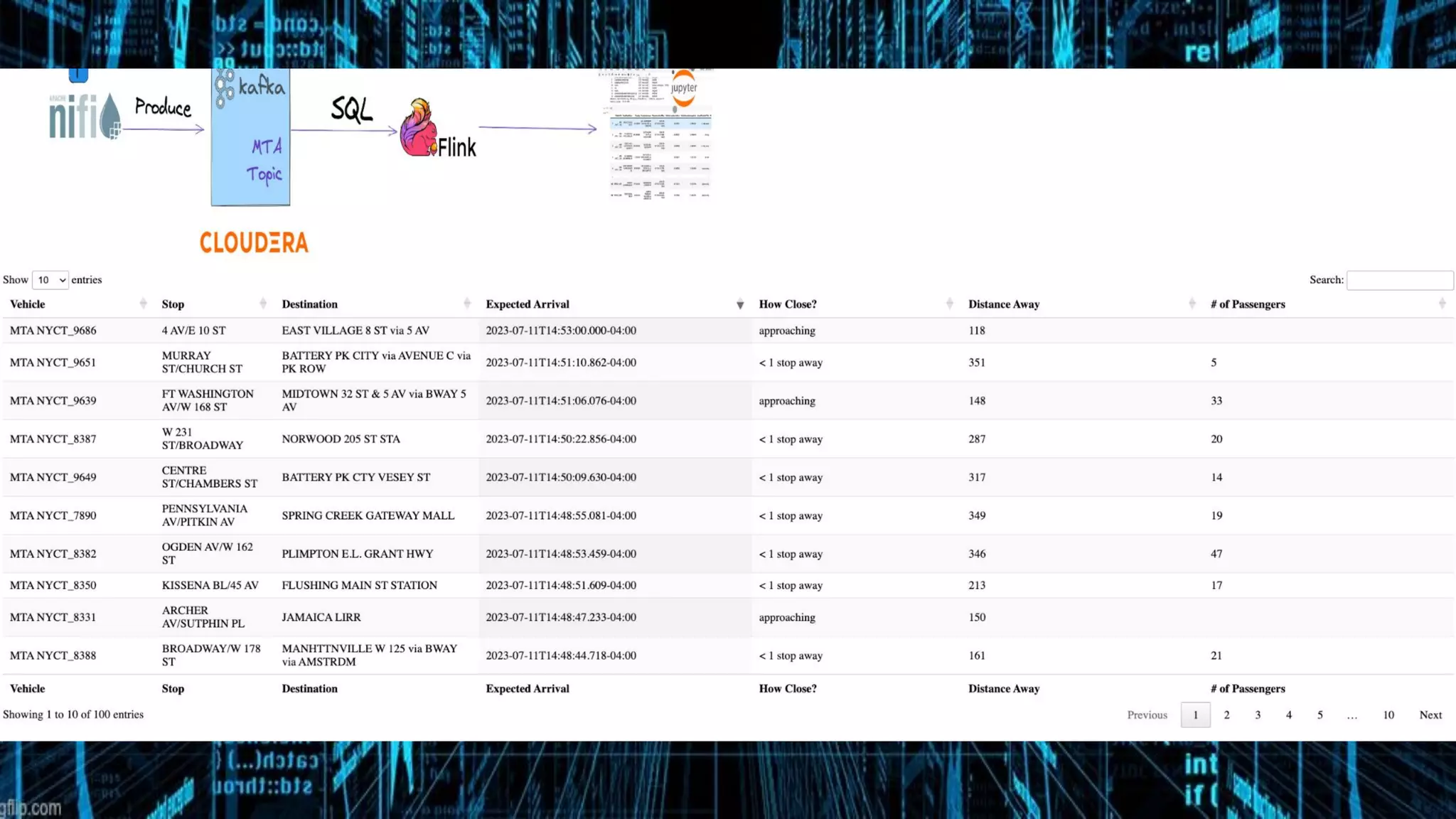


This document presents a case study on using Apache Flink, Apache NiFi, and Apache Kafka to build real-time data processing pipelines, specifically focusing on the Flank-MTA project that processes data from the New York City Metropolitan Transportation Authority. It outlines best practices for collecting, transforming, and analyzing high-volume data streams, emphasizing scalable and fault-tolerant solutions. Additional insights include integration techniques and potential business impacts of real-time data processing.























































































