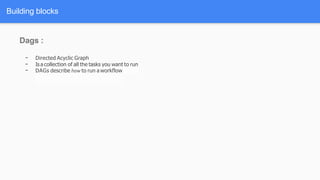
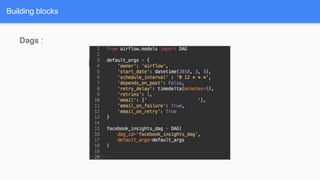
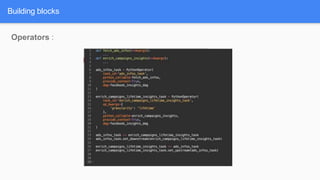
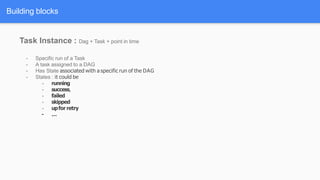
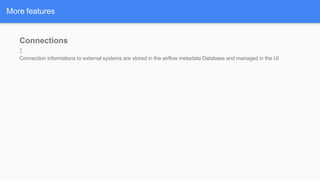
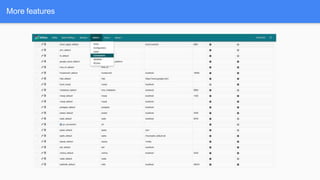
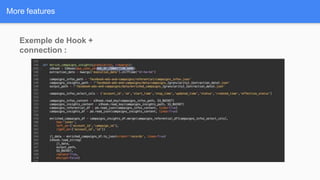
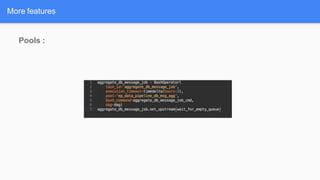
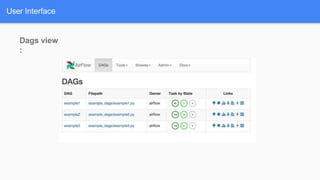
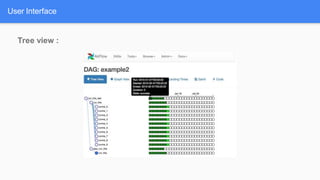
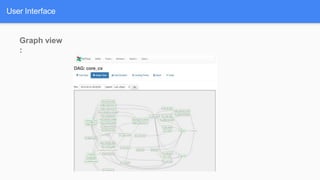
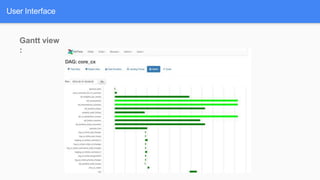
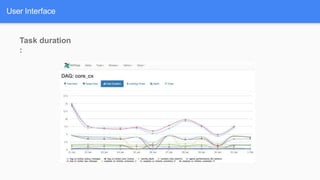
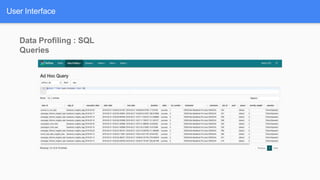
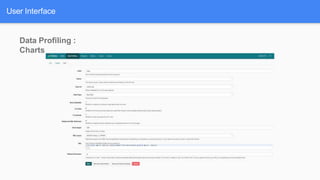
Airflow is a workflow management system for authoring, scheduling and monitoring workflows or pipelines. It has several key components including DAGs which define workflows as directed acyclic graphs of tasks. Operators represent individual tasks or steps while hooks allow connections to external systems. Airflow supports features like variables, cross-communication (XComs), security, CLI, and a user interface for visualizing workflows.

























![CL
I
https://airflow.apache.org/cli.html
airflow variables [-h] [-s KEY VAL] [-g KEY] [-j] [-d VAL] [-i FILEPATH] [-e FILEPATH] [-x
KEY]
airflow connections [-h] [-l] [-a] [-d] [--conn_id CONN_ID]
[--conn_uri CONN_URI] [--conn_extra CONN_EXTRA]
[--conn_type CONN_TYPE] [--conn_host CONN_HOST]
[--conn_login CONN_LOGIN] [--conn_password CONN_PASSWORD]
[--conn_schema CONN_SCHEMA] [--conn_port CONN_PORT]
airflow pause [-h] [-sd SUBDIR] dag_id
airflow test [-h] [-sd SUBDIR] [-dr] [-tp TASK_PARAMS] dag_id task_id execution_date
airflow backfill dag_id task_id -s START_DATE -e END_DATE
airflow clear DAG_ID
airflow resetdb [-h] [-y]
...](https://image.slidesharecdn.com/airflowwebuiandcli-230924165721-0d866a79/85/airflow-web-UI-and-CLI-pptx-46-320.jpg)






























![Bootstrapping a ML platform at Bluevine [Airflow Summit 2020]](https://cdn.slidesharecdn.com/ss_thumbnails/airflowsummit20201-200716055944-thumbnail.jpg?width=640&height=640&fit=bounds)































