Downloaded 15 times


![““ The average interaction worker spends
[...] nearly 20 percent (of the workweek)
looking for internal information.”
-MGI Report, 2012.
4
Half (54%) of global information workers said, "My work
gets interrupted because I can't find or get access to
information I need to complete my tasks" a few times a
month or more often. -Forrester Data Global Business
Technographics Devices And Security Workforce Survey, 2016.](https://image.slidesharecdn.com/bbuzznaturallanguagesearch-190619080523/75/Building-an-enterprise-Natural-Language-Search-Engine-with-ElasticSearch-and-Facebook-s-DrQA-4-2048.jpg)




![PMI INFORMATION SERVICES 2016
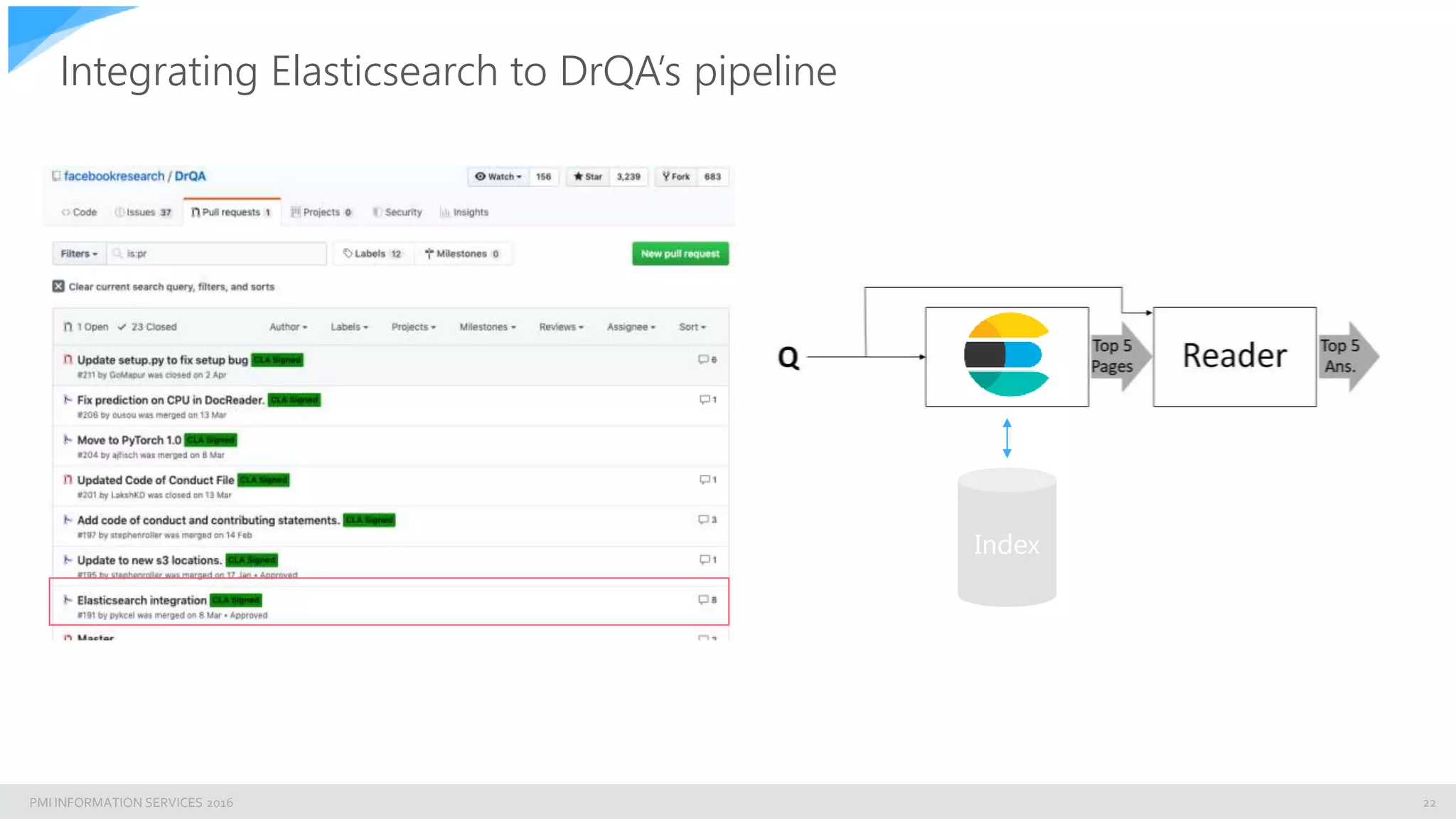
Integrating Elasticsearch to DrQA’s pipeline
23
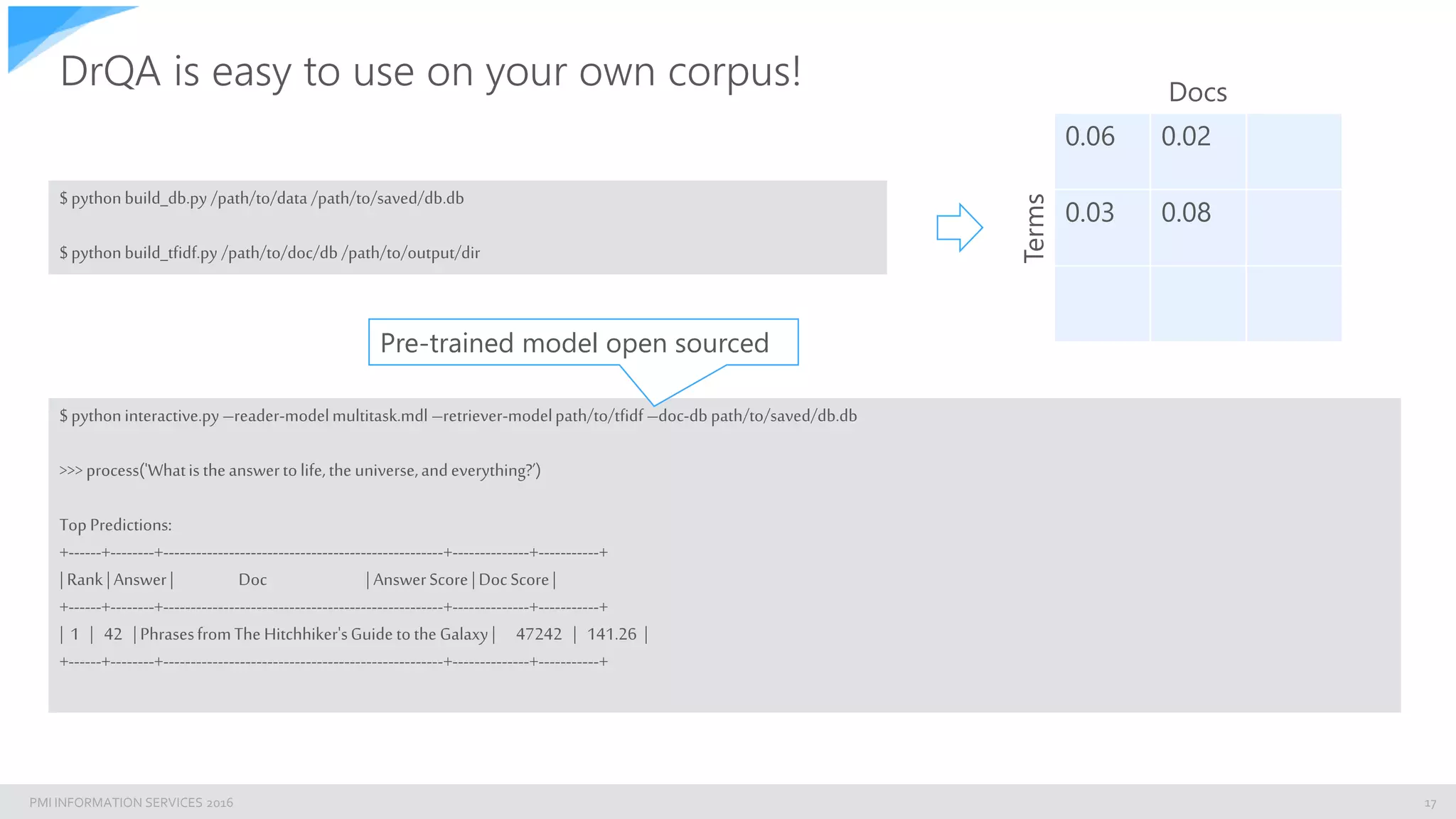
>>>fromdrqa.pipeline importDrQA
>>>fromdrqa.retrieverimportElasticDocRanker
>>>model= DrQA(reader_model=‘reader_model.mdl’,
ranker_config={'class':ElasticDocRanker,
'options':{'elastic_url':'127.0.0.1:9200’,
'elastic_index':'mini’, 'elastic_fields':'content’,
'elastic_field_doc_name':['file','filename’],
'elastic_field_content': 'content’}})
>>>model.process(’Howthe tensioningoftheV-belts shouldbe done?’)
Directly point to your server hosting Elastic Enable to search in any fields, e.g. uni-grams, bi-
grams, title, metadata, etc…](https://image.slidesharecdn.com/bbuzznaturallanguagesearch-190619080523/75/Building-an-enterprise-Natural-Language-Search-Engine-with-ElasticSearch-and-Facebook-s-DrQA-20-2048.jpg)
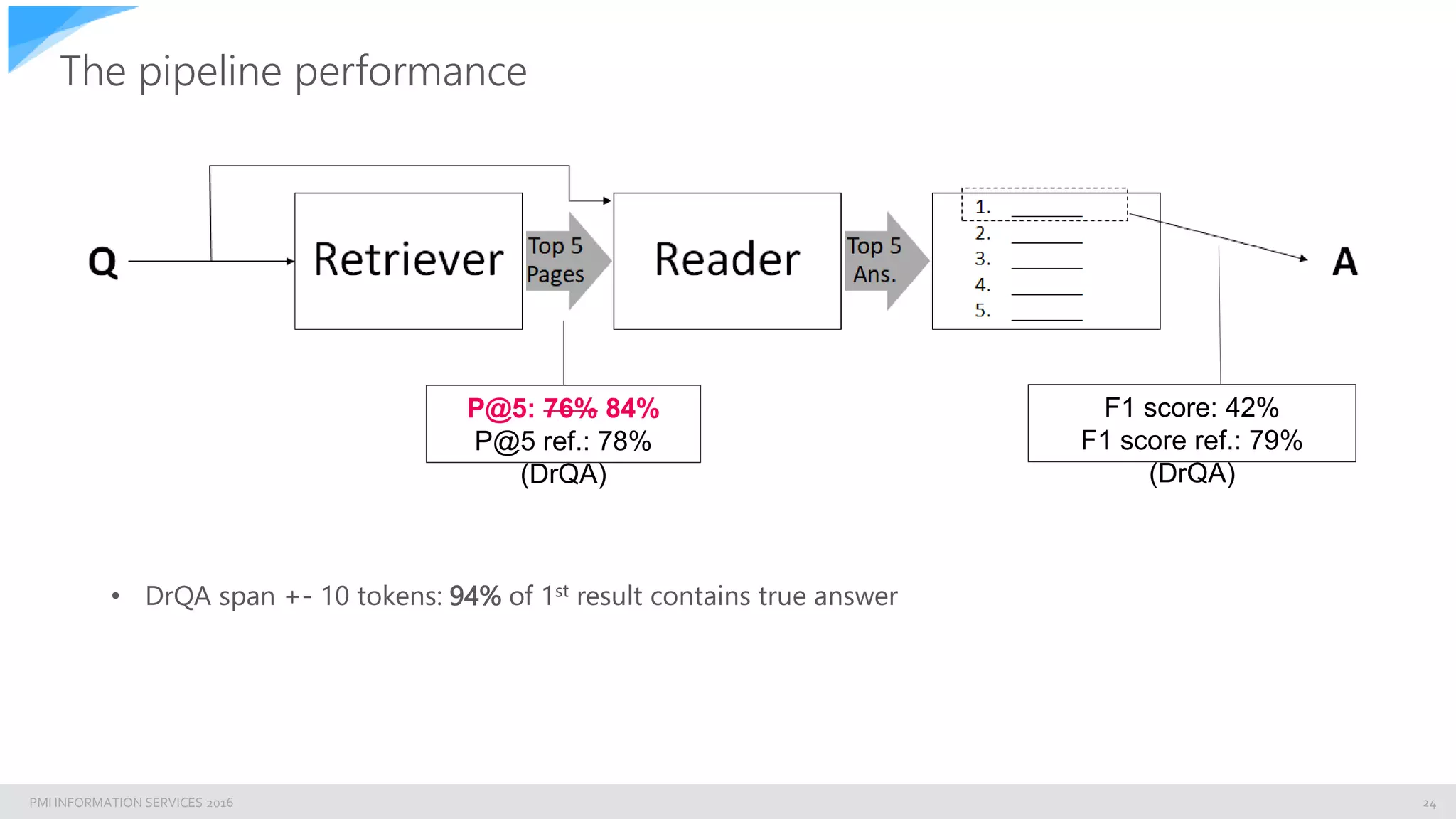
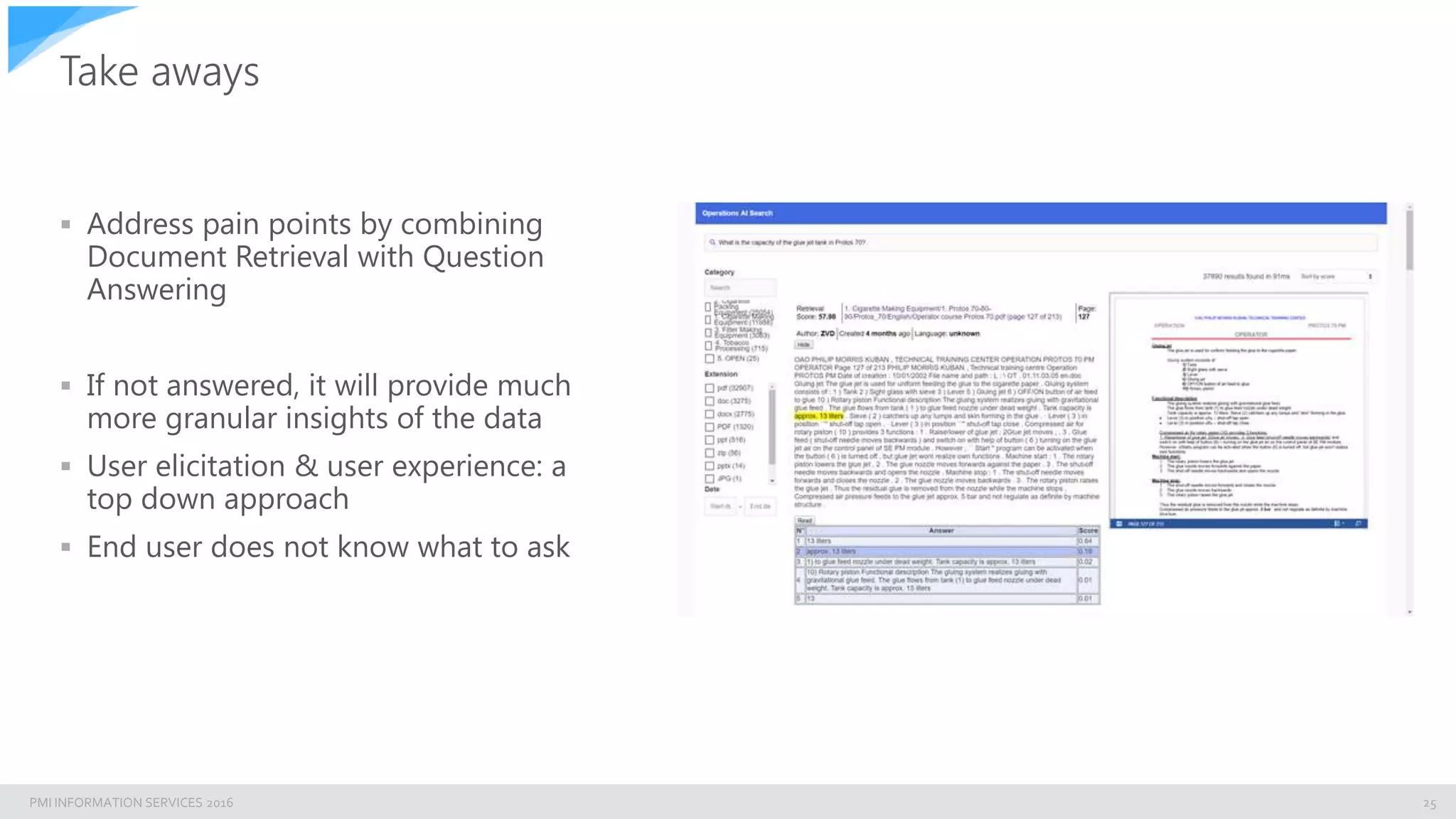
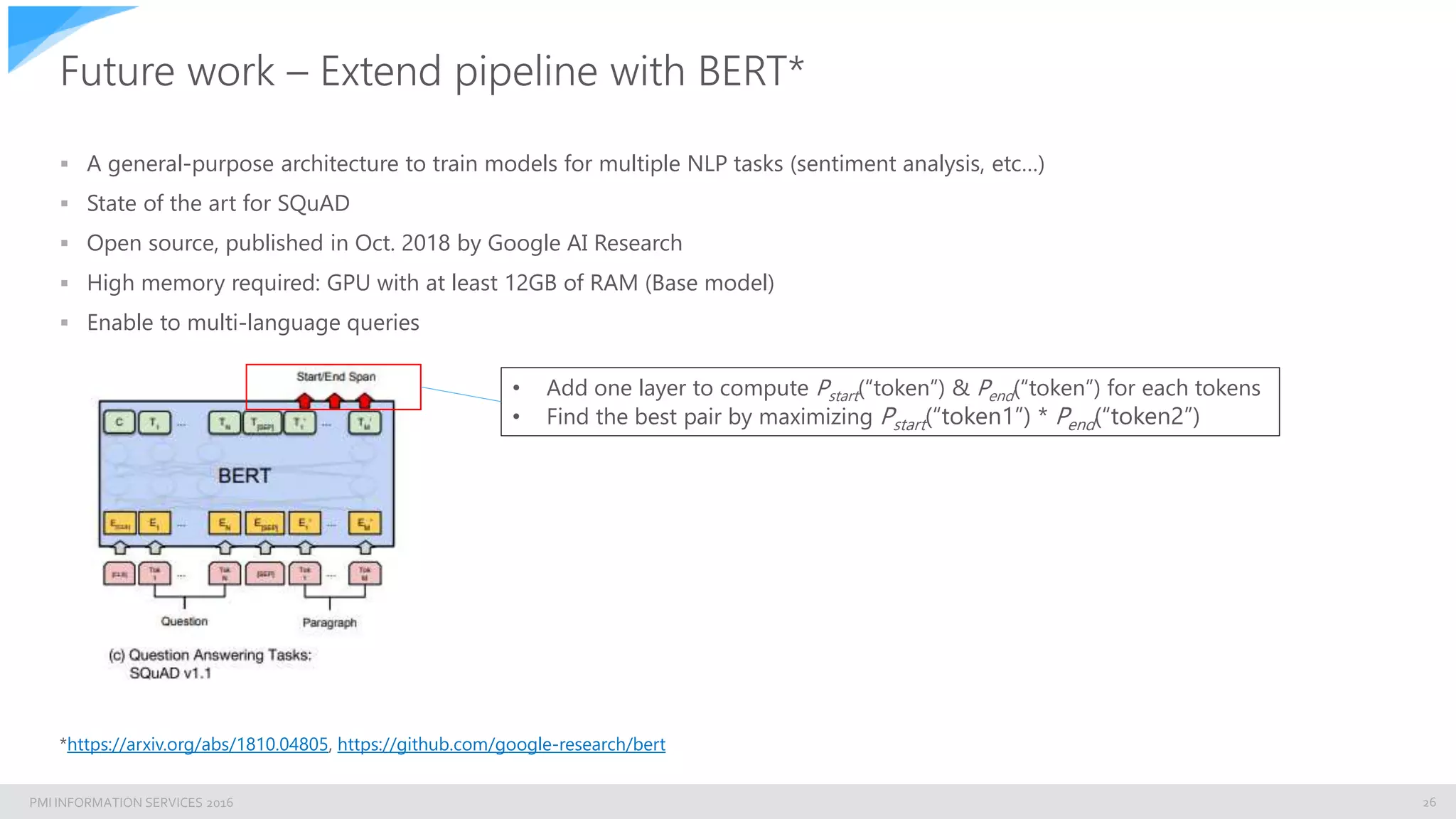


The document discusses building an enterprise natural language search engine using Elasticsearch and Facebook's DRQA. It highlights the limitations of traditional search methods and the significance of integrating AI technologies for improved information retrieval, particularly in enterprise contexts. The document also outlines the architecture, performance, and future enhancements of the search system, including potential integrations with other models like BERT.











![The Evolution of Metadata: LinkedIn's Story [Strata NYC 2019]](https://cdn.slidesharecdn.com/ss_thumbnails/metadatajourneylinkedinstratapublic-190930045839-thumbnail.jpg?width=640&height=640&fit=bounds)




















![[QCon.ai 2019] People You May Know: Fast Recommendations Over Massive Data](https://cdn.slidesharecdn.com/ss_thumbnails/qconaisf2019-pymk-190424130904-thumbnail.jpg?width=640&height=640&fit=bounds)



















































