Downloaded 29 times














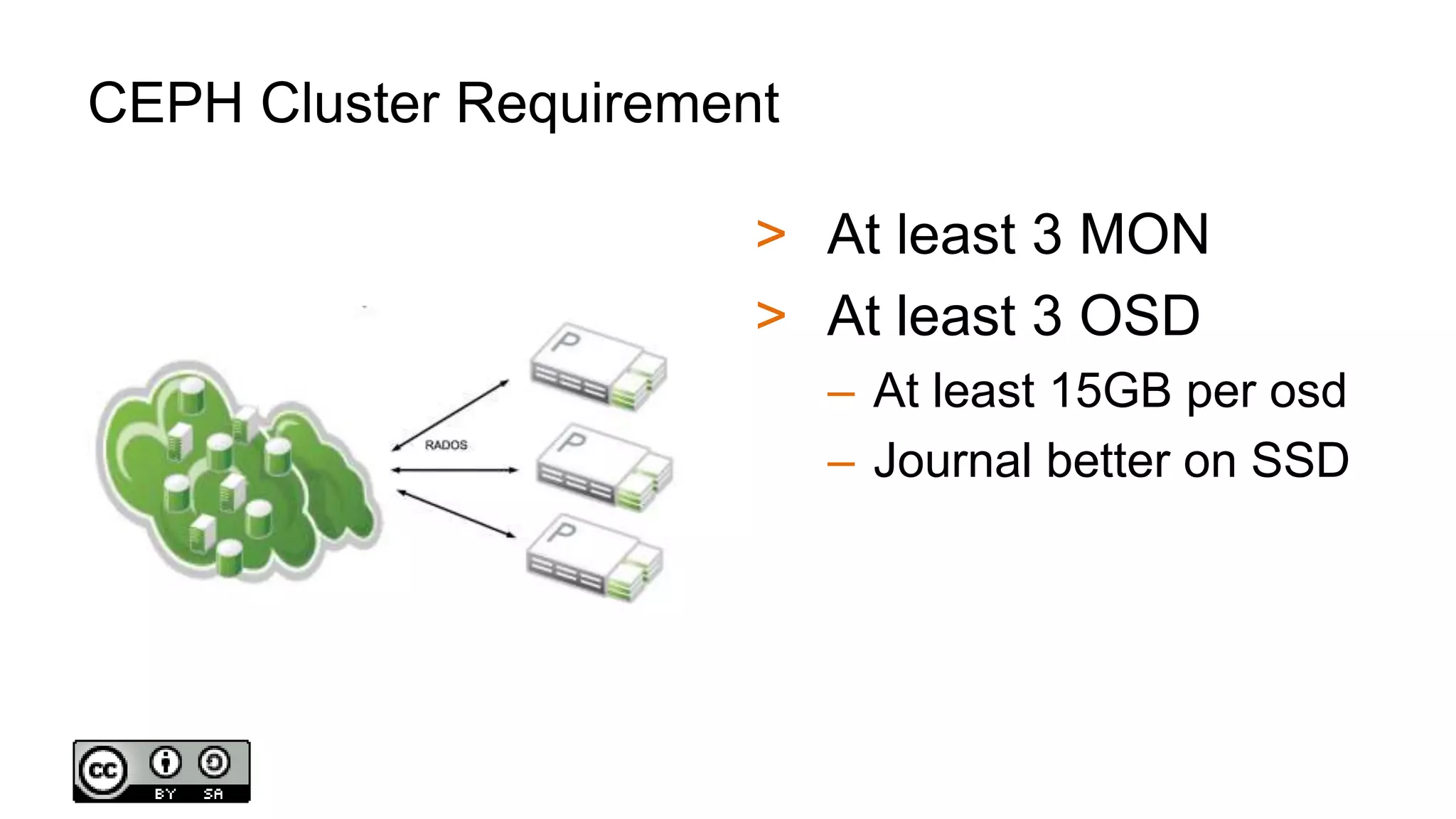















The document discusses building affordable cloud storage solutions with a focus on software-defined storage architecture, outlining its advantages such as high extensibility, availability, and flexibility. It describes cluster setup requirements for technologies like Ceph and presents use cases, cost comparisons, and management commands for effective administration. The document also provides technical specifications for storage devices and configurations, emphasizing the practicality and benefits for businesses.










![[OpenStack Days Korea 2016] Track1 - All flash CEPH 구성 및 최적화](https://cdn.slidesharecdn.com/ss_thumbnails/12skt-160226171513-thumbnail.jpg?width=640&height=640&fit=bounds)









































































