Download as PDF, PPTX
































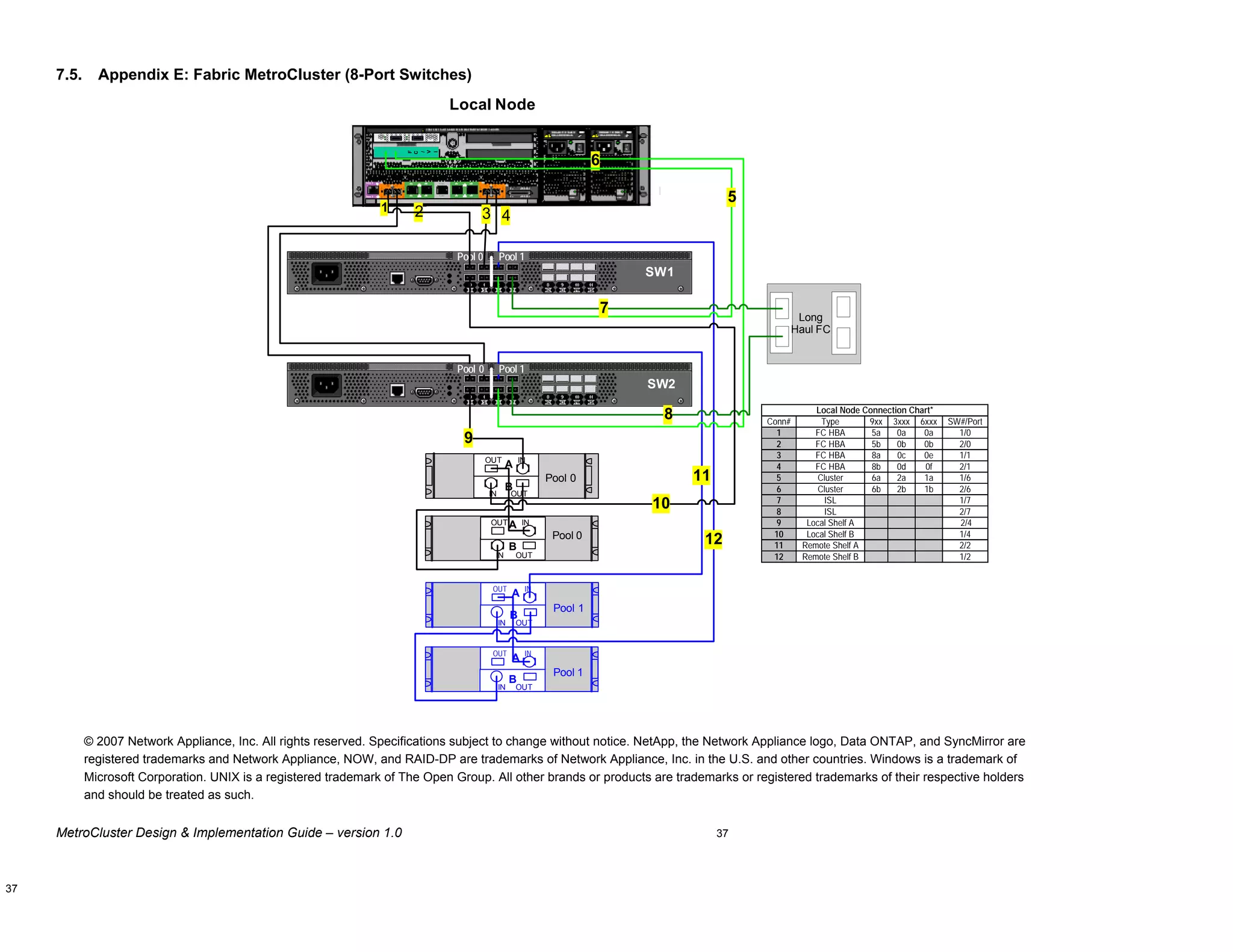
This document provides guidance on architecting and deploying MetroCluster configurations, including an overview of MetroCluster, planning considerations, installation steps, and best practices. It covers stretched, switched, and fabric MetroCluster topologies using NetApp storage and includes configuration examples for 16-port and 8-port Brocade switches. The intended audience is field personnel responsible for MetroCluster implementations.






















































































