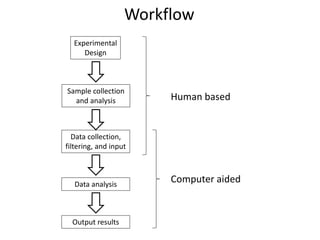
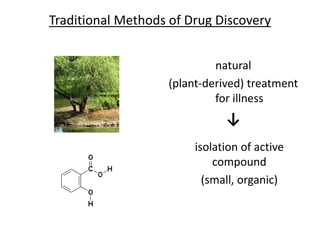
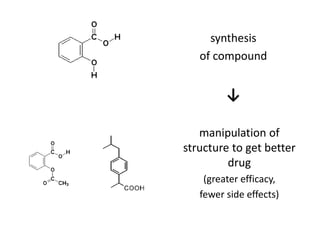
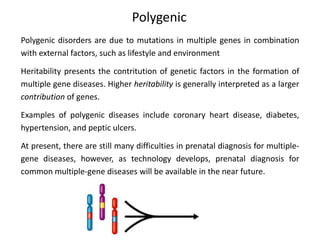
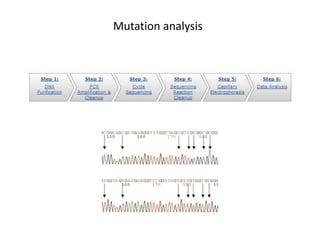
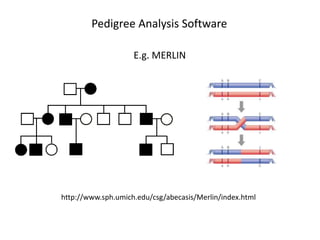
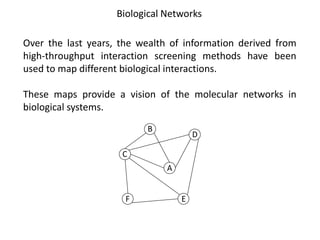
This document discusses various approaches to identifying genes associated with inherited diseases. It begins by describing different types of genetic disorders including monogenic, polygenic, chromosomal, and mitochondrial disorders. It then outlines traditional methods for identifying candidate genes which involve linkage analysis, segregation analysis, and fine mapping studies. Modern approaches utilizing large genetic databases and bioinformatics tools are also discussed. The document provides examples of software and databases used in gene identification and summarizes the multi-step process of establishing inheritance patterns, localizing genes, and elucidating causal DNA sequences.