Downloaded 35 times


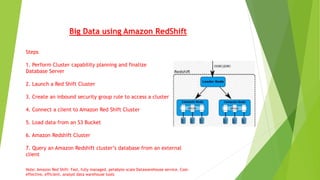







This document provides steps for performing big data analytics using Amazon Redshift, EC2, and S3. It outlines how to 1) plan and launch a Redshift cluster, 2) connect a client and load data from S3, and 3) query the Redshift database from an external client. Key points are that Redshift is a fast, managed data warehouse service, optimized for processing large datasets ranging from GB to PB for low cost compared to other solutions. It also takes on administrative tasks so users can focus on analytics.













![[Aurora事例祭り]Amazon Aurora を使いこなすためのベストプラクティス](https://cdn.slidesharecdn.com/ss_thumbnails/amazonauroratips-170307140000-thumbnail.jpg?width=640&height=640&fit=bounds)














![[よくわかるAmazon Redshift]Amazon Redshift最新情報と導入事例のご紹介](https://cdn.slidesharecdn.com/ss_thumbnails/20140219redshiftupdatesv1tokyo-140224010117-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[よくわかるAmazon Redshift in 大阪]Amazon Redshift最新情報と導入事例のご紹介](https://cdn.slidesharecdn.com/ss_thumbnails/20140221redshiftupdatesv2osaka-140224010309-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
























