Download to read offline


















![@Kognitio @mphnyc #MPP_R
create external script LM_PRODUCT_FORECAST environment rsint
receives ( SALEDATE DATE, DOW INTEGER, ROW_ID INTEGER, PRODNO INTEGER, DAILYSALES
partition by PRODNO order by PRODNO, ROW_ID
sends ( R_OUTPUT varchar )
isolate partitions
script S'endofr( # Simple R script to run a linear fit on daily sales
prod1<-read.csv(file=file("stdin"), header=FALSE,row.names
colnames(prod1)<-c("DOW","ID","PRODNO","DAILYSALES")
dim1<-dim(prod1)
daily1<-aggregate(prod1$DAILYSALES, list(DOW = prod1$DOW),
daily1[,2]<-daily1[,2]/sum(daily1[,2])
basesales<-array(0,c(dim1[1],2))
basesales[,1]<-prod1$ID
basesales[,2]<-(prod1$DAILYSALES/daily1[prod1$DOW+1,2])
colnames(basesales)<-c("ID","BASESALES")
fit1=lm(BASESALES ~ ID,as.data.frame(basesales))
select Trans_Year, Num_Trans,
count(distinct Account_ID) Num_Accts,
sum(count( distinct Account_ID)) over (partition by Trans_Year
cast(sum(total_spend)/1000 as int) Total_Spend,
cast(sum(total_spend)/1000 as int) / count(distinct Account_ID
rank() over (partition by Trans_Year order by count(distinct A
rank() over (partition by Trans_Year order by sum(total_spend)
from( select Account_ID,
Extract(Year from Effective_Date) Trans_Year,
count(Transaction_ID) Num_Trans,
select dept, sum(sales)
from sales_fact
Where period between date ‘01-05-2006’ and date ‘31-05-2006’
group by dept
having sum(sales) > 50000;
select sum(sales)
from sales_history
where year = 2006 and month = 5 and region=1;
select total_sales
from summary
where year = 2006 and month = 5 and region=1;
Behind the
numbers](https://image.slidesharecdn.com/bigdata-bi-mature8-130618083222-phpapp02/85/Big-data-bi-mature-oanyc-summit-24-320.jpg)



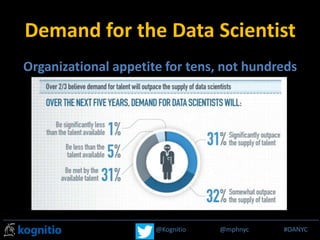
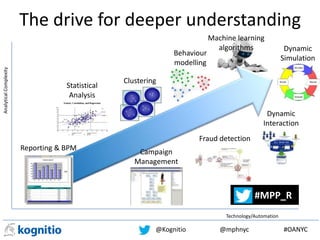
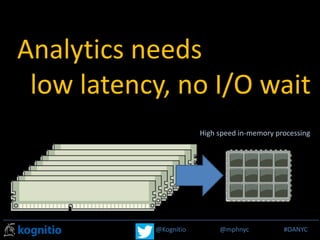
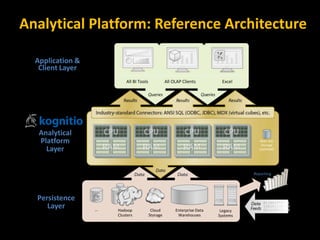
The document discusses the challenges data scientists face in operationalizing big data projects and making the results accessible for broader organizational use. It argues that within the next 18 months, big data will become integrated into standard reporting and analysis used by all employees, not just data scientists. However, current tools like Hadoop are too slow for interactive work. New technologies are needed that provide massively parallel processing and tightly integrate with Hadoop, but also allow for use of existing reporting tools. This will require analytical platforms with in-memory processing capabilities and low latency.






















































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)
