Downloaded 23 times



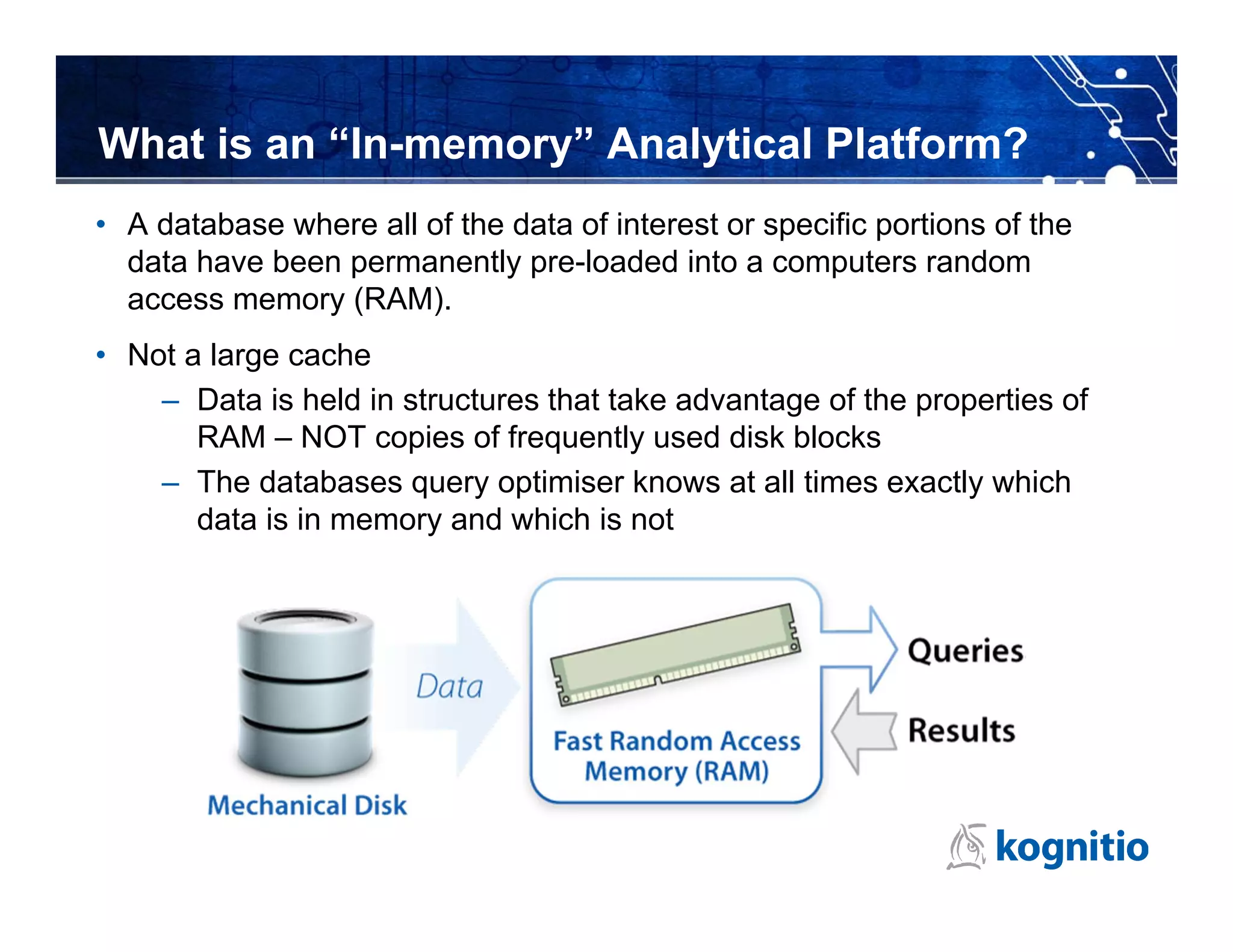

![Not Only SQL: any language in-line
Kognitio External Scripts
– Run third party binaries or scripts embedded within SQL
• Perl, Python, Java, R, SAS, etc.
• One-to-many rows in, zero-to-many rows out, one to one
create interpreter perlinterp
command '/usr/bin/perl' sends 'csv' receives 'csv' ;
select top 1000 words, count(*) This reads long comments
from (external script using environment perlinterp text from customer enquiry
receives (txt varchar(32000))
sends (words varchar(100)) table, in line perl converts
script S'endofperl( long text into output
while(<>)
{ stream of words (one word
chomp(); per row), query selects top
s/[,.!_]//g;
foreach $c (split(/ /)) 1000 words by frequency
{ if($c =~ /^[a-zA-Z]+$/) { print "$cn”} } using standard SQL
}
)endofperl' aggregation
from (select comments from customer_enquiry))dt
group by 1
order by 2 desc;](https://image.slidesharecdn.com/kognitiooverviewjan2013-130121132825-phpapp02/75/Kognitio-overview-jan-2013-11-2048.jpg)




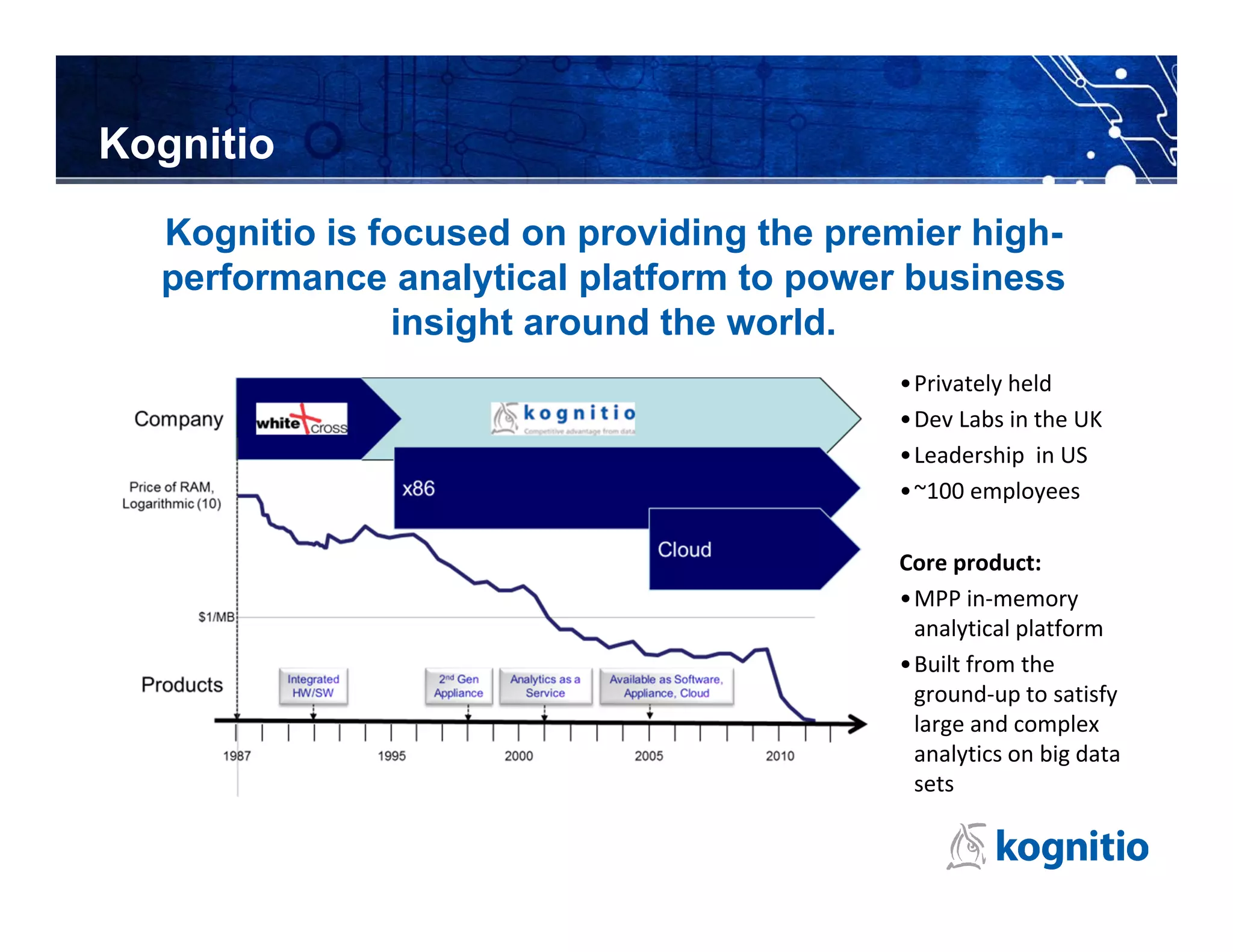
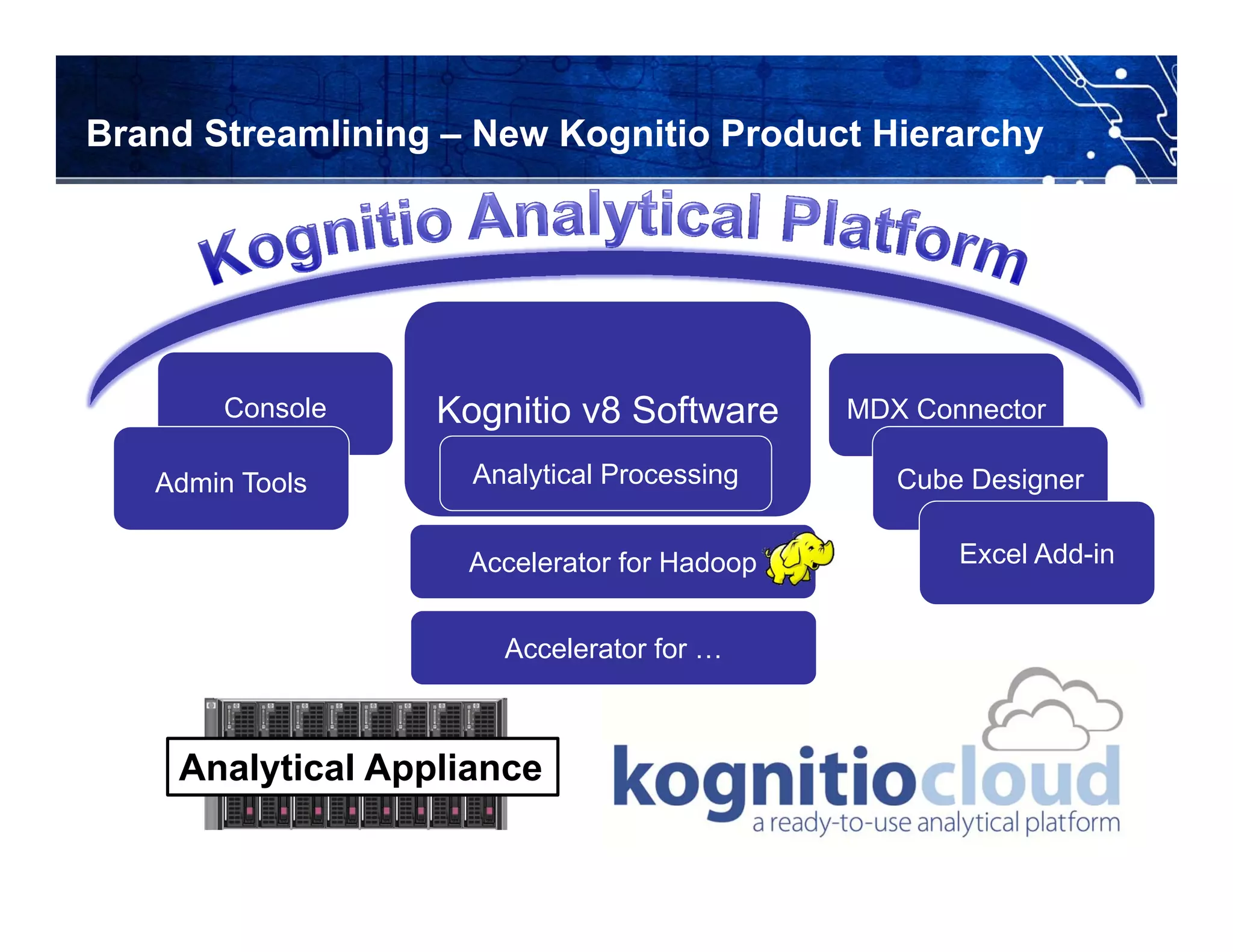
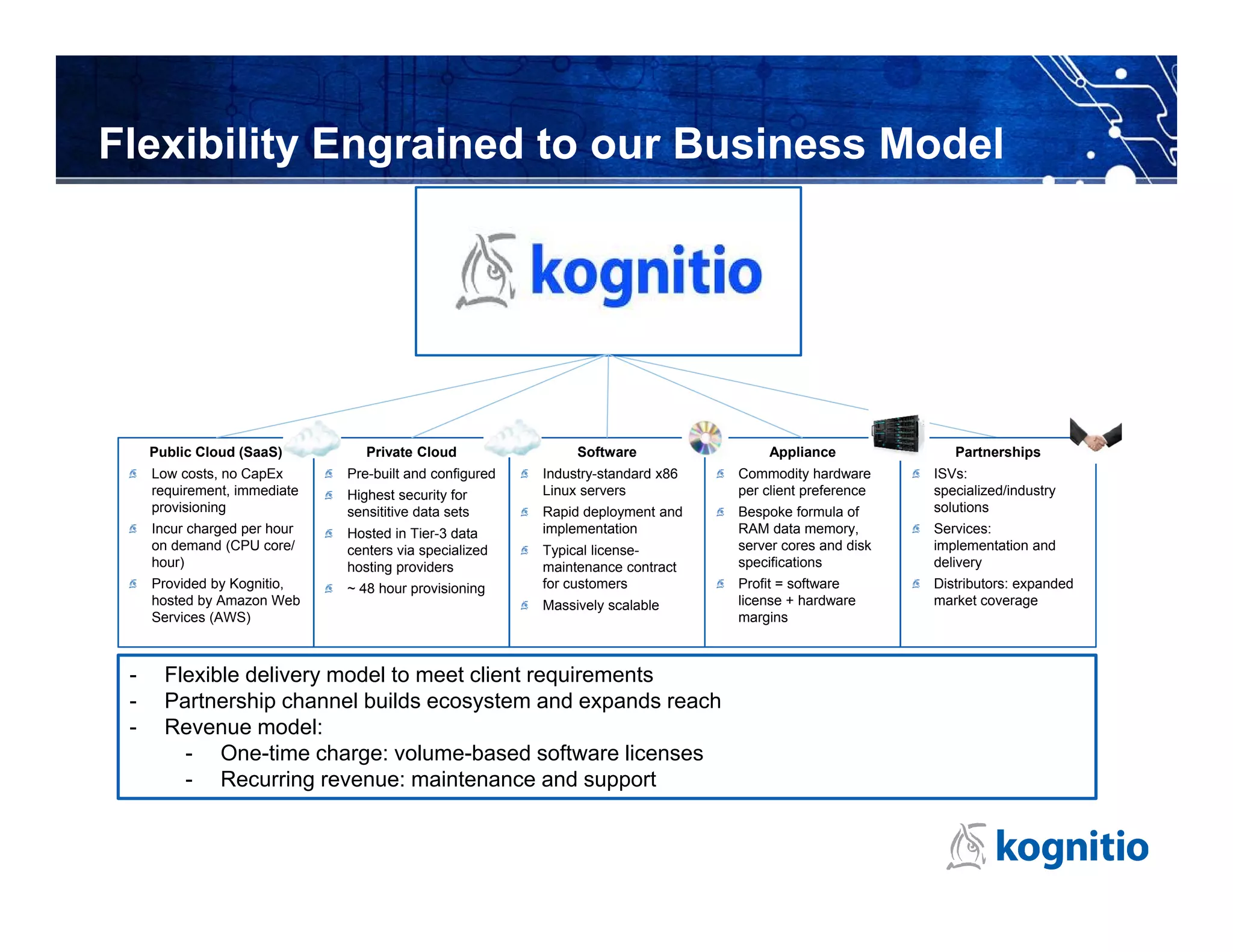
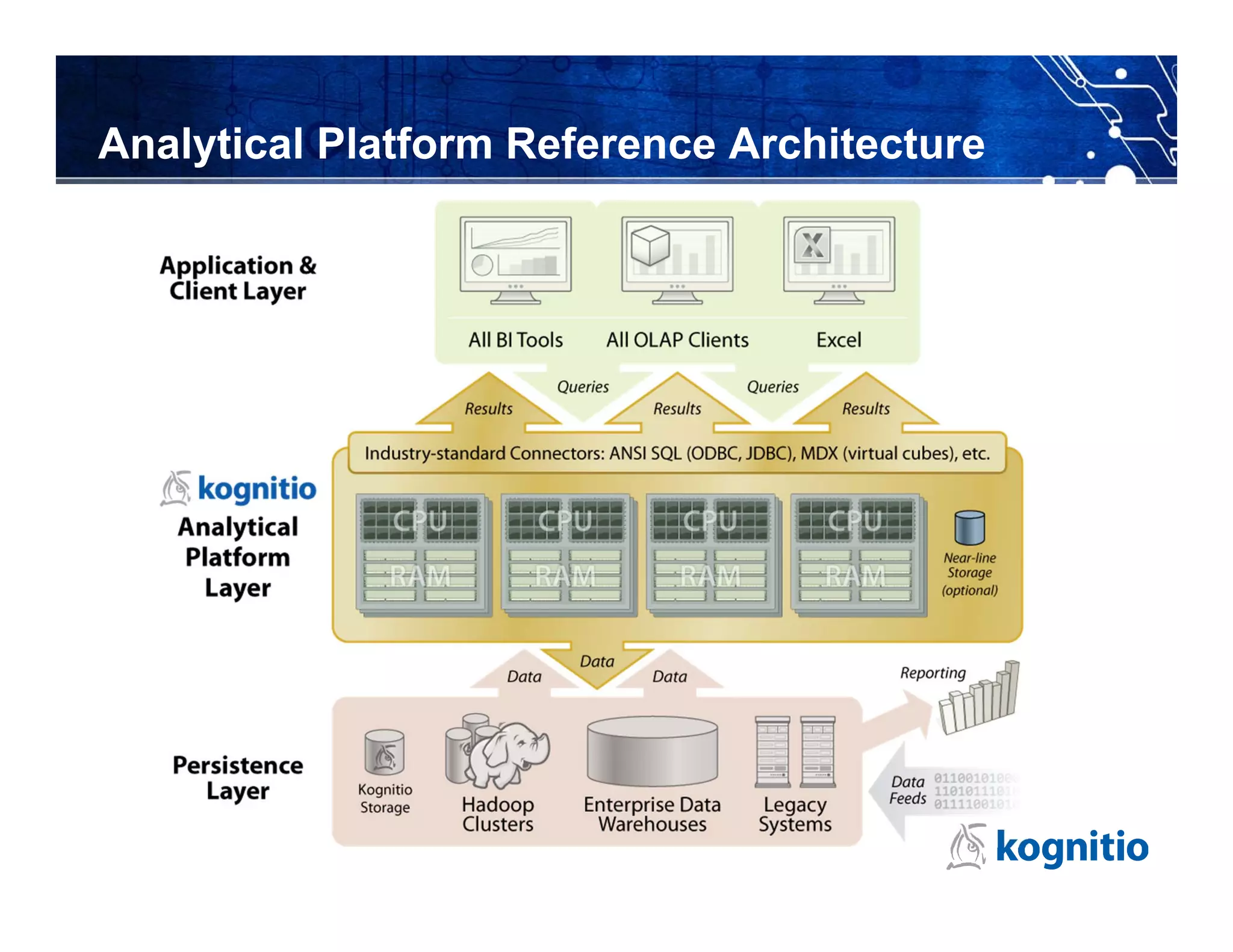
Kognitio provides a high-performance in-memory analytical platform designed for large and complex data analytics, leveraging a flexible model for deployment across public and private clouds. The platform enables rapid data processing through a scalable architecture that utilizes multiple servers and CPU cores to handle significant data volumes in real-time. Their solutions cater to various industries, including media analytics and customer loyalty, demonstrating effective data insights and automated reporting for clients.

































































