Download as PDF, PPTX































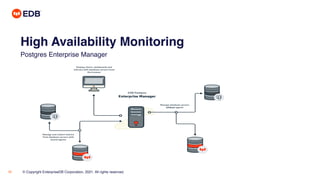










The document is a presentation on high availability (HA) for PostgreSQL, detailing its key concepts, calculations for availability, and the importance of Recovery Point Objective (RPO) and Recovery Time Objective (RTO). It discusses methods for achieving HA in PostgreSQL through techniques such as streaming and logical replication, alongside tools for management and monitoring. The presentation also highlights strategies for software updates and maintenance windows to ensure near zero downtime in operational environments.























































































