Download to read offline



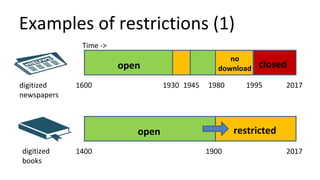
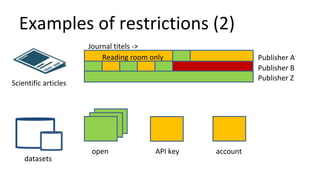


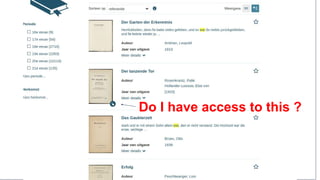











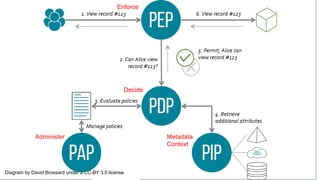

















The document discusses the challenges of providing open access to digital content while navigating copyright and contract restrictions. It emphasizes the need for a centralized system to automate rights decisions based on contextual factors such as user type, location, and publication date, thereby improving user experience and compliance. The proposed solution includes implementing policies as code to manage access dynamically and enhance metadata management.





































![ANIMAL_CELL_,_TISSUE_AND_ORGAN_CULTURE[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/animalcelltissueandorganculture1-260204172026-4462b440-thumbnail.jpg?width=640&height=640&fit=bounds)
















