Downloaded 78 times






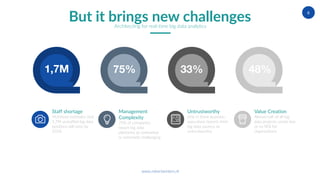
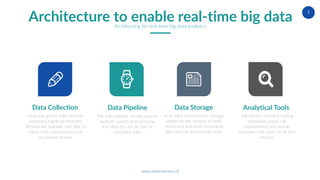






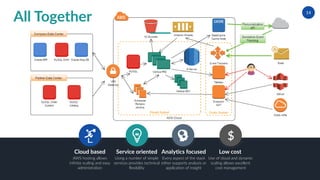



The document discusses the intricacies of architecting real-time big data analytics, highlighting challenges like data volume, velocity, and veracity that companies face today. It emphasizes the importance of real-time capabilities for improving customer experiences and optimizing business processes, along with a strategic architecture that supports both real-time and batch data processing. The author, Robert Winters, also notes the potential for new revenue streams and operational insights that can be unlocked through effective big data analytics.

















































































