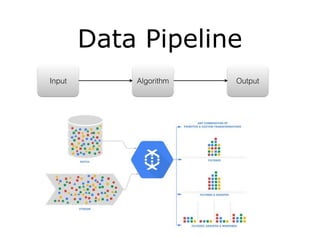
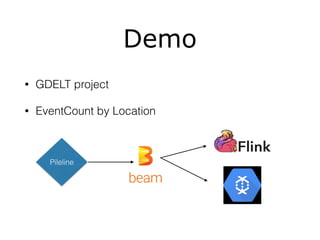
The document discusses Apache Beam as a data pipeline solution, highlighting its ability to handle both batch and streaming jobs through various runners like Google Cloud Dataflow and Apache Flink. It emphasizes the abstraction layer provided by Beam for simplified data processing and outlines key components such as pipelines, transforms, and I/O operations. Further, it encourages the use of Beam or Flink APIs for stream data processing and notes recent developments in related tools like BigQuery and DataStudio.






















































































![20260201 [FOSDEM] gomodjail - library sandboxing for Go modules.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/20260201fosdemgomodjail-librarysandboxingforgomodules-260201225659-76609ec4-thumbnail.jpg?width=640&height=640&fit=bounds)



![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)













