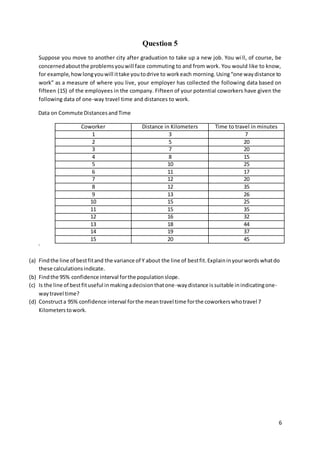
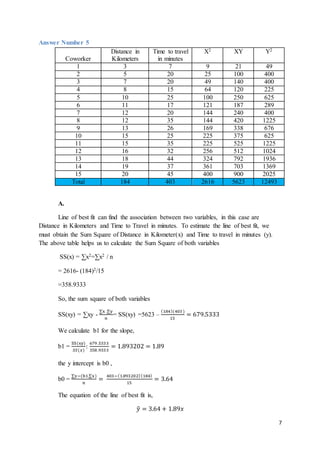
This document contains 5 questions and their answers. Question 1 analyzes survey data to determine if more than 61% of people sleep 7 or more hours per night on weekends. Question 2 calculates a p-value for a hypothesis test comparing the means of two employment tests. Question 3 performs a hypothesis test to examine if a sample's mean score differs from the expected population mean. Question 4 uses a chi-squared test to determine if there is a preference for certain class times. Question 5 provides commute data and asks to calculate the line of best fit, confidence intervals, and determine if distance can indicate travel time.