
















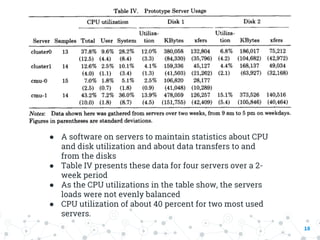




































The document summarizes the Andrew File System (AFS), a distributed file system developed at Carnegie Mellon University. It describes the initial prototype of AFS implemented in the 1980s, which used client-server architecture with Venus processes on client workstations caching files from Vice servers. The prototype showed performance bottlenecks due to high server CPU usage from frequent cache validation checks and pathname traversals. Subsequent versions improved performance by reducing cache checks, having clients perform name resolution, using a single server process with lightweight threads, and identifying files by unique IDs instead of pathnames.












































































