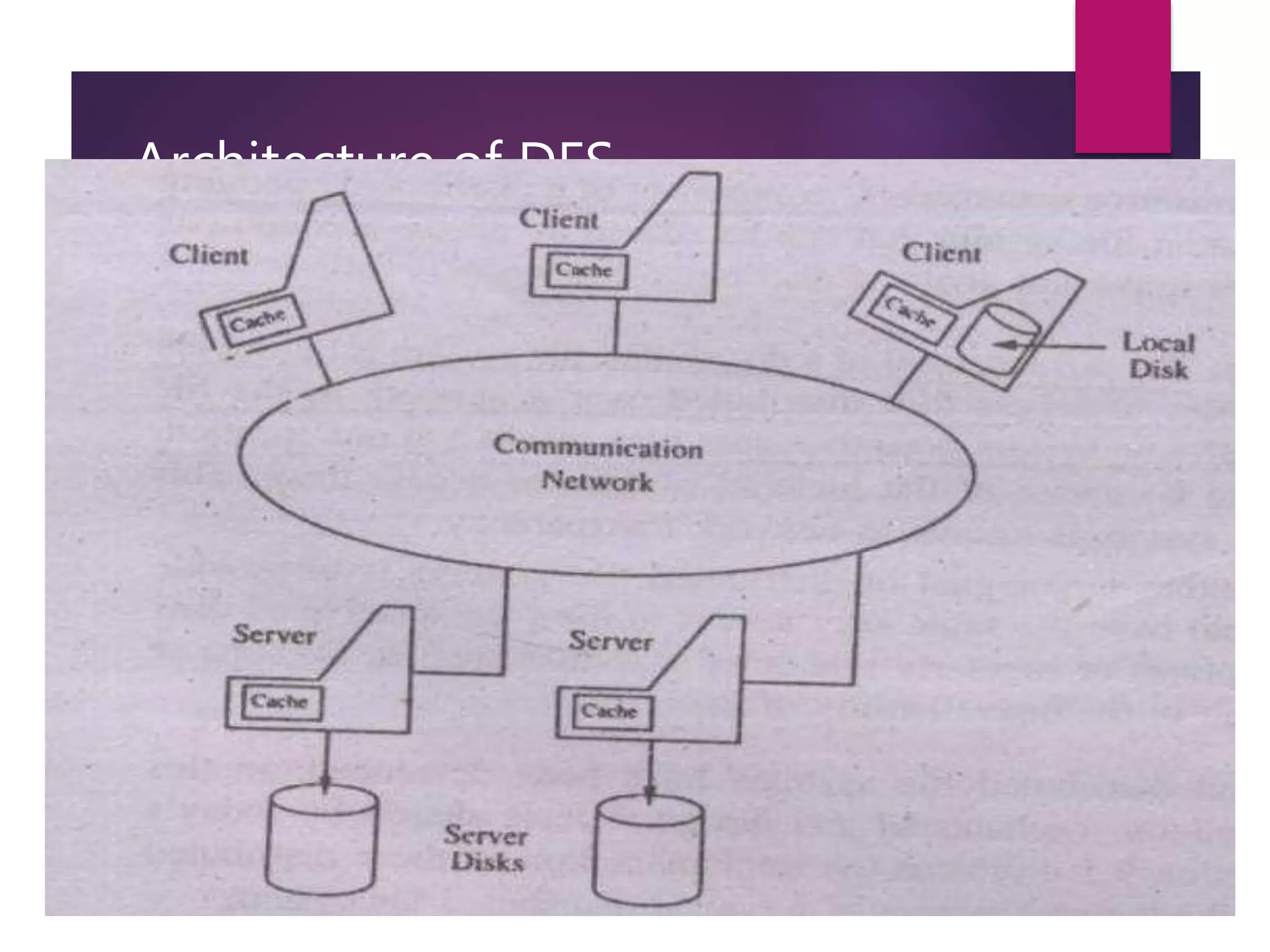
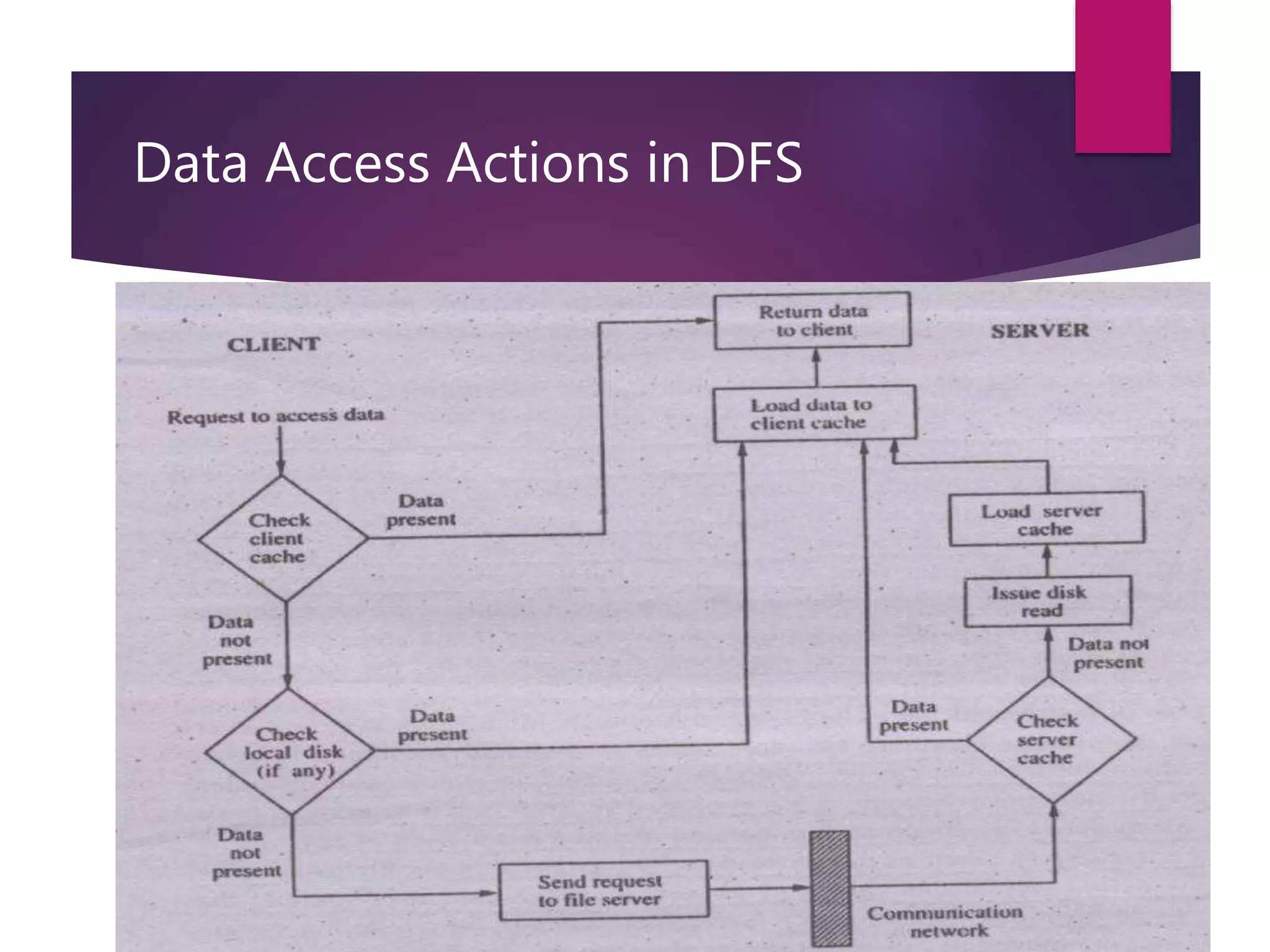
Distributed file systems allow files to be accessed across a network in a transparent manner. They achieve high availability by allowing users easy access to files irrespective of physical location. A DFS uses name servers to map file names to storage locations and cache managers to copy remote files to clients for faster access. Key components include caching, replication for availability, and consistency protocols to ensure clients see up-to-date file data. Design goals involve scalability to large numbers of clients and servers as well as maintaining strong file semantics even in distributed systems.