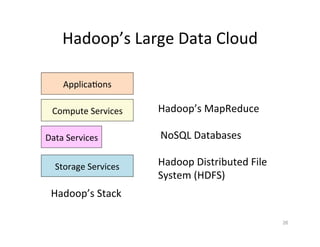
This document provides an introduction to data intensive computing. It discusses how data and computing are growing exponentially due to improvements in instruments and technologies. This is creating new paradigms of data intensive science and computing. The document then discusses how cloud computing models like utility clouds (e.g. Amazon) and data clouds are facilitating data intensive computing by providing scalable resources and platforms for storing, managing and processing large amounts of data. Key concepts covered include virtualization, infrastructure as a service (IaaS), and MapReduce as a programming model for distributed computing on big data.










![The
Term
‘In
the
Cloud’
is
Annoying
• “Personally,
I
find
the
term
‘in
the
cloud’
preten+ous
and
annoying.
…
the
world’s
marketers
and
P.R.
people
seem
to
think
that
‘the
cloud’
just
means
‘online.’
”
David
Pogue,
NYT
June
16,
2011.
• More
specifically
he
notes
that
you
can
think
of
the
cloud
as
“data
and
applica+on
sopware
stored
on
remote
servers
[and
accessed
via
the
Internet]”](https://image.slidesharecdn.com/01-introduction-big-data-science-clouds-11-v5-170904211843/85/An-Introduction-to-Data-Intensive-Computing-11-320.jpg)