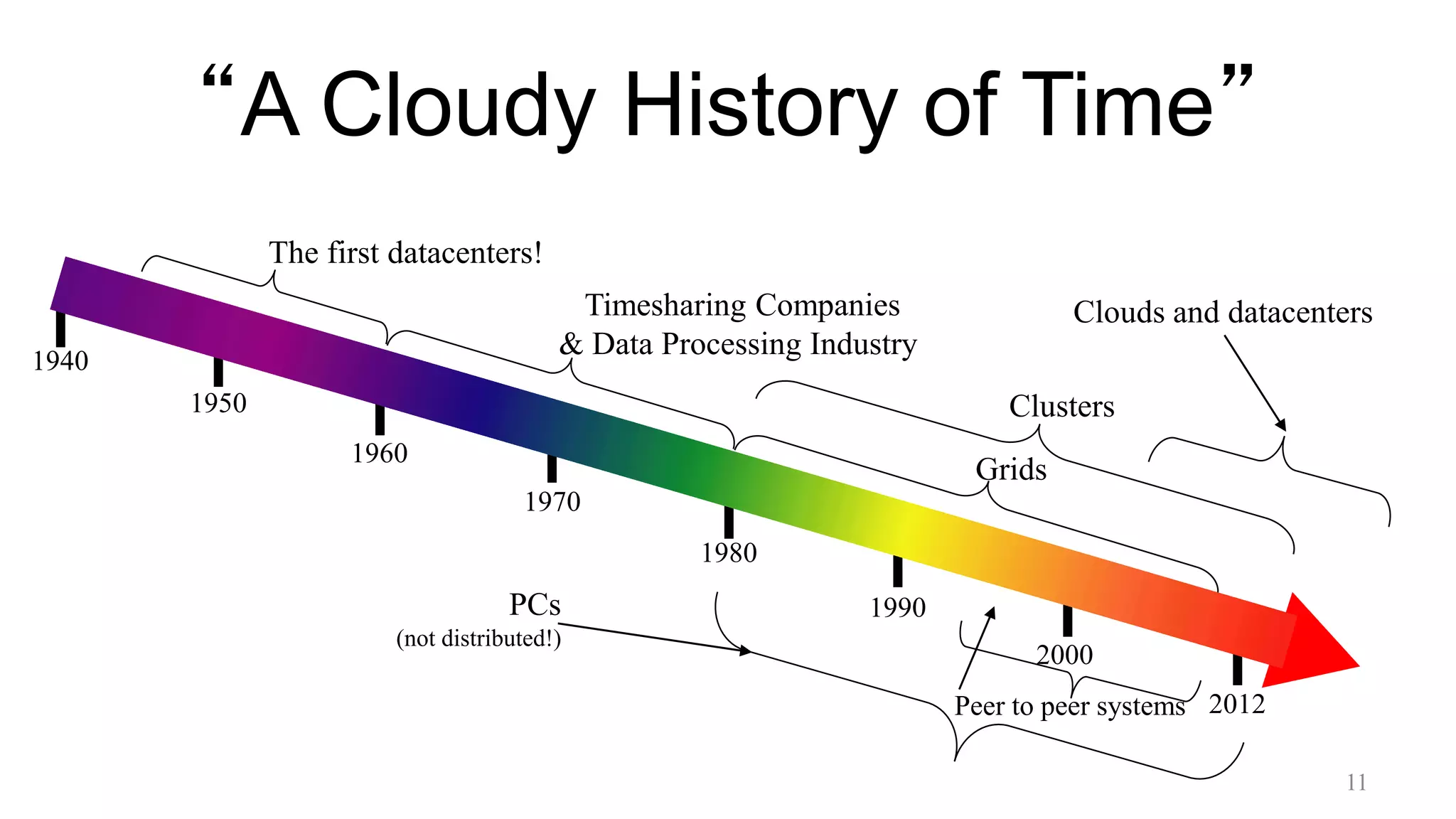
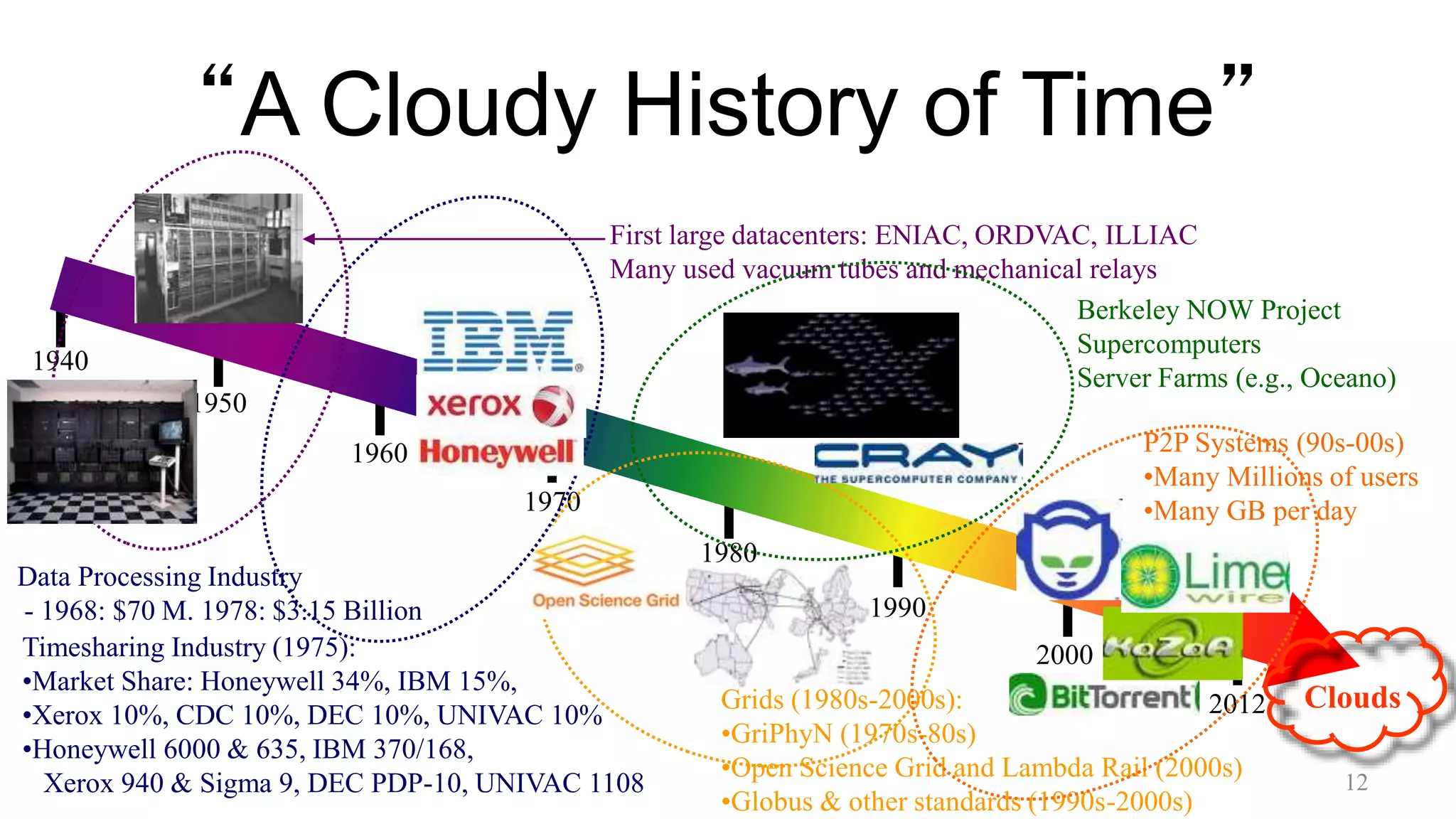
This document discusses the key aspects of cloud computing. It begins by outlining the massive scale of today's clouds, with companies like Facebook, Microsoft, and Amazon operating clouds with tens or hundreds of thousands of servers. It then discusses the main characteristics of cloud computing, including on-demand access in a pay-as-you-go model, the data-intensive nature of workloads involving terabytes and petabytes of data, and new programming paradigms like MapReduce. The document also covers the differences between public, private, and academic clouds, and factors to consider in choosing between outsourcing to a public cloud or operating your own private cloud.














![I. Massive Scale
• Facebook [GigaOm, 2012]
– 30K in 2009 -> 60K in 2010 -> 180K in 2012
• Microsoft [NYTimes, 2008]
– 150K machines
– Growth rate of 10K per month
– 80K total running Bing
– In 2013, Microsoft Cosmos had 110K machines (4 sites)
• Yahoo! [2009]:
– 100K
– Split into clusters of 4000
• AWS EC2 [Randy Bias, 2009]
– 40K machines
– 8 cores/machine
• eBay [2012]: 50K machines
• HP [2012]: 380K in 180 DCs
• Google [2011, Data Center Knowledge] : 900K
17](https://image.slidesharecdn.com/l2-3-230112101108-477df8d6/75/L2-3-FA19-ppt-17-2048.jpg)

























![UNIT I -Introduction to CLOUD COMPUTING [Autosaved].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/uniti-introductiontocloudcomputingautosaved-250128091123-f66abd14-thumbnail.jpg?width=640&height=640&fit=bounds)

















![[DSC Europe 25] Bassam Maharmeh - Artificial Intelligence: Opportunities and ...](https://cdn.slidesharecdn.com/ss_thumbnails/thhfmr2fqpawzj7hsjpg-5-251211083048-2c23204f-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Uros Pesic - The Reality of AI in Marketing.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/rtkodnmtycovsllvzsyn-9-251215095918-b0c6bfe3-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Tatevik Maytesyan - How to actually use AI in marketing: gett...](https://cdn.slidesharecdn.com/ss_thumbnails/tjo626lsqdgfntbgl2mw-4-251216103155-e36cd239-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Danica Soc - The Science Behind Marketing: Experimentation me...](https://cdn.slidesharecdn.com/ss_thumbnails/c0nofsggs9gw5ucmallr-3-251216103155-56bd64d1-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Miodrag Pesovic & Vladislav Radonjic - Federated Data Archite...](https://cdn.slidesharecdn.com/ss_thumbnails/gsbe3y5it5uhndi4e08e-1-251212103249-f1008e0c-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Jovan Bogicevic - Legacy to AI-Driven Defense: Transforming D...](https://cdn.slidesharecdn.com/ss_thumbnails/rsarluadt563hntyfc8q-3-251211083849-3e7bc4c0-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Hans Kleinsman - The Compliance Gearbox: How Tax Tech Mediate...](https://cdn.slidesharecdn.com/ss_thumbnails/dxdytie1toel0hr90bjs-2-251212103250-174fdbe7-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Katherine Forrest - AI NOW: Understanding the Velocity of Cha...](https://cdn.slidesharecdn.com/ss_thumbnails/wvvbruqfrci0sfq9xwgb-4-251212104007-e5ad1987-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Dusan Nesic - Securing Tomorrow’s Infrastructure: Why Cyber-P...](https://cdn.slidesharecdn.com/ss_thumbnails/qikbszfftyowjm2q6duw-1-251211083848-8f2ead6b-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Kaja Kandare - LLM as a judge.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/arxyccaxsdsd1ba99wjw-7-251212104007-2b4e3f64-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Behzad Hosseini - AI Agents in the Wild: Deploying Models tha...](https://cdn.slidesharecdn.com/ss_thumbnails/3qtejajvsjqrzwfept2c-10-251212103250-7f2b1068-thumbnail.jpg?width=640&height=640&fit=bounds)
