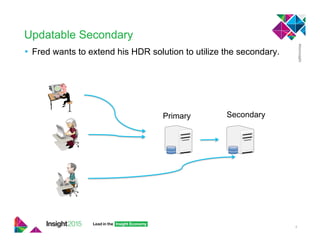
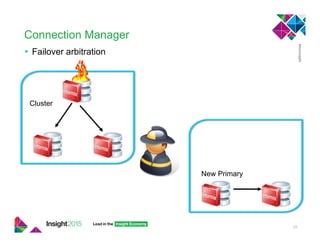
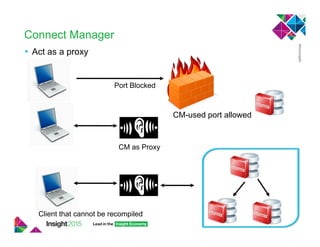
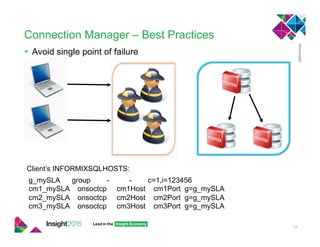
This document provides best practices for implementing high availability and disaster recovery solutions for Informix databases using HDR, RSS, SDS, and connection manager technologies. It discusses configuration parameters and strategies for minimizing data loss and downtime in the event of failures. Key recommendations include using unbuffered logging, tuning bufferpool and I/O settings, and coordinating transactions across nodes for applications.