Download to read offline


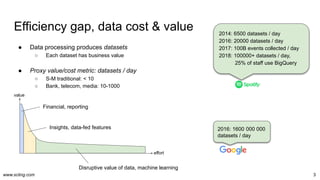
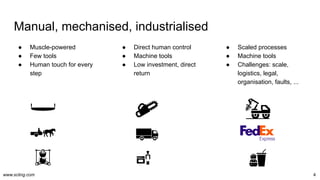

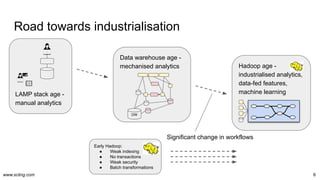
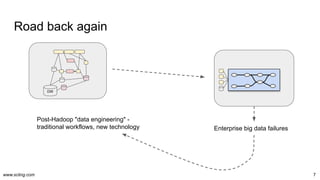
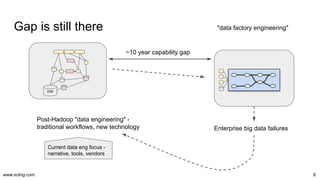
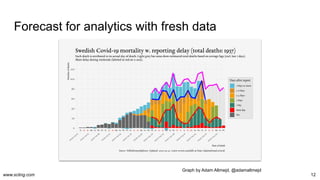
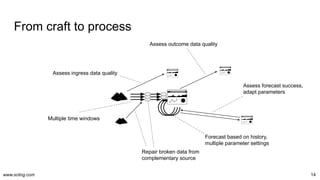
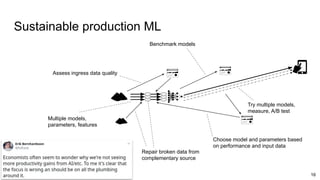
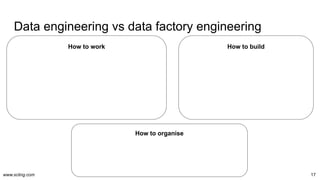
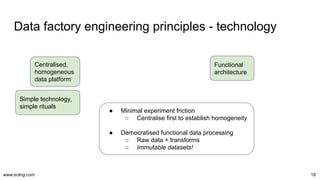
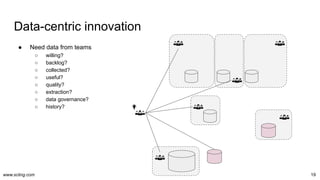
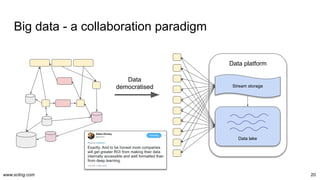
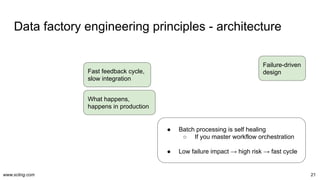
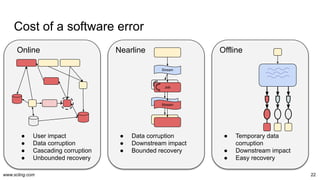
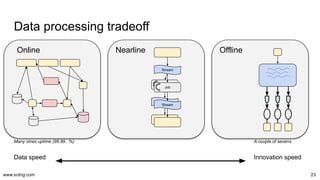
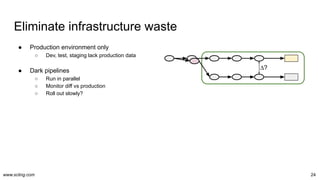
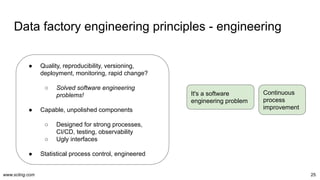

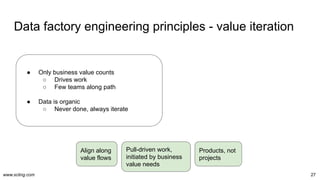
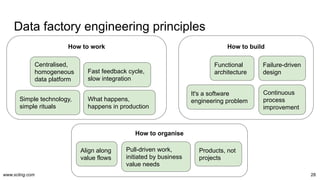
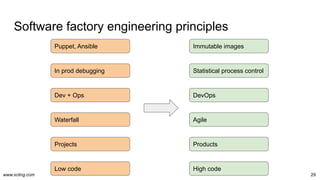

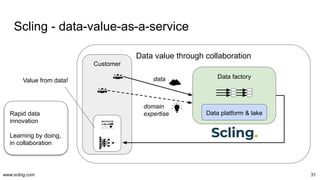

The document discusses the evolution and challenges in data processing capabilities, highlighting the disparity in efficiency and the transition from manual to automated processes. It emphasizes the importance of data factory engineering, advocating for centralized, homogenous platforms and continuous improvement to enhance data quality and value. Additionally, it recommends that companies pursue in-house development strategies or collaborate with vendors to better leverage data innovation.




























































![[DSC Europe 25] Ekaterina Bubenko - Behind the Curtain: How Data Roles Collab...](https://cdn.slidesharecdn.com/ss_thumbnails/anmv6x8dstqbbzchoklr-ekaterina-bubenko-behind-the-curtain-how-data-roles-collaborate-in-the-ai-era-a-260123083019-4b252ec7-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Predrag Maletic - Scaling AI in Banking – Our Strategic Journ...](https://cdn.slidesharecdn.com/ss_thumbnails/qu2onv0aruwlvqtygmxx-predrag-maletic-scaling-ai-in-banking-260123083019-6cf1da1d-thumbnail.jpg?width=640&height=640&fit=bounds)