Download to read offline


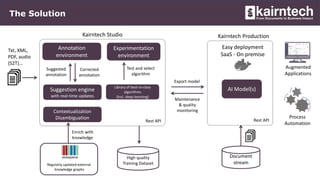

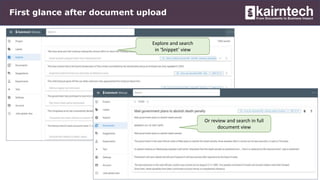




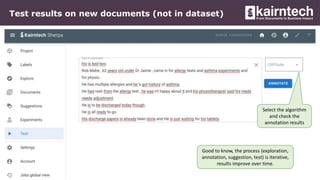
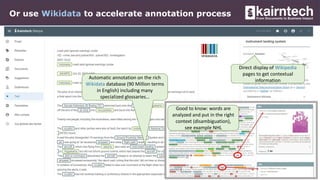




Kairntech offers an AI-powered SaaS platform designed for efficient document analysis, making it accessible to domain experts without requiring sophisticated AI skills. The platform facilitates annotation, categorization, and entity extraction from unstructured documents, streamlining business processes and improving data quality. With features like real-time suggestions, easy deployment, and support for multiple languages, Kairntech enables rapid dataset creation and enhances document processing significantly.














































































