Download as PDF, PPTX





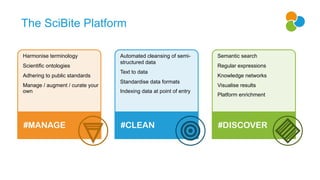
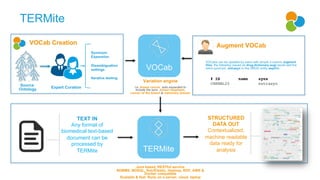
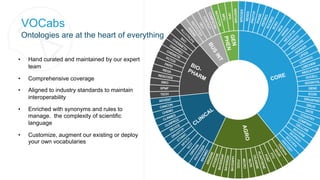





![The Problem
• Poor keyword search results
• Inability to search across a specific concept e.g. [GENE]
• Unable to manage synonymy/ambiguity
The Solution
• SciBite Vocabularies cover >80 different Scientific concepts
• Rule-based system to translate language of science
• Flexible architecture to integrate seamlessly with partner systems
The Outcome
• Powerful, enterprise search transformed into scientifically aware system
Enterprise Search](https://image.slidesharecdn.com/scibiteintroupdate-190416115951/85/SciBite-13-320.jpg)
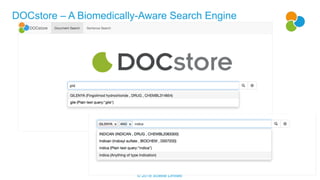
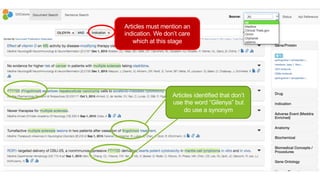









The document outlines the challenges associated with unstructured scientific data, such as poor search results and information overload, while introducing the SciBite platform as a solution to enhance data accessibility and analysis. It highlights how the platform utilizes ontologies and semantic search to transform unstructured text into machine-readable data, facilitating better scientific insights and innovation. Key features include automated data cleansing, customizable vocabularies, and a user-friendly interface that supports multiple scientific use cases.



































































