Amazon Aurora?
• 오픈소스 호환 관계형 데이터베이스
• MySQL, PostgreSQL
• 상용 데이터베이스의 성능과 가용성 제공
• 오픈소스 데이터베이스의 비용 효율성과 간단함
5.
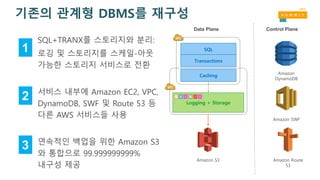
기존의 관계형 DBMS를재구성
SQL+TRANX를 스토리지와 분리:
로깅 및 스토리지를 스케일-아웃
가능한 스토리지 서비스로 전환
서비스 내부에 Amazon EC2, VPC,
DynamoDB, SWF 및 Route 53 등
다른 AWS 서비스들 사용
연속적인 백업을 위한 Amazon S3
와 통합으로 99.999999999%
내구성 제공
Control PlaneData Plane
Amazon
DynamoDB
Amazon SWF
Amazon Route
53
Logging + Storage
SQL
Transactions
Caching
Amazon S3
1
2
3
6.
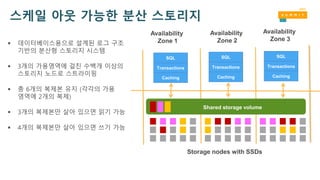
스케일 아웃 가능한분산 스토리지
Master Replica Replica Replica
Availability
Zone 1
Shared storage volume
Availability
Zone 2
Availability
Zone 3
Storage nodes with SSDs
데이터베이스용으로 설계된 로그 구조
기반의 분산형 스토리지 시스템
3개의 가용영역에 걸친 수백개 이상의
스토리지 노드로 스트라이핑
총 6개의 복제본 유지 (각각의 가용
영역에 2개의 복제)
3개의 복제본만 살아 있으면 읽기 가능
4개의 복제본만 살아 있으면 쓰기 가능
SQL
Transactions
Caching
SQL
Transactions
Caching
SQL
Transactions
Caching
7.
Aurora is usedby:
2/3 of top 100 AWS customers
8 of top 10 gaming customers
Aurora 사용 고객
AWS 역사상 가장 빠르게 성장하는 서비스
8.
누가 왜 Aurora로옮겨오는가?
기존의 상용 DBMS 사용 고객
기존의 MySQL 사용 고객
최대 5배 빠른 성능
최대 60%의 비용 절감
애플리케이션 변경 없이 쉽게 마이그레이션
라이선스 비용 없이 1/10의 운용 비용
클라우드와 유기적인 결합
고성능과 가용성
마이그레이션 도구와 서비스 지원
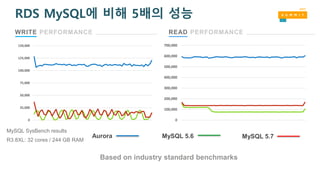
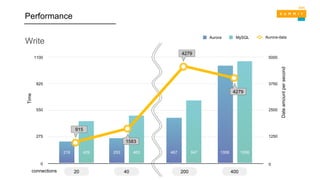
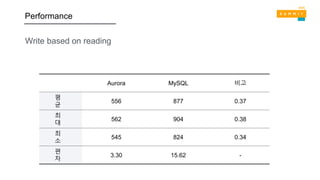
WRITE PERFORMANCE READPERFORMANCE
MySQL SysBench results
R3.8XL: 32 cores / 244 GB RAM
RDS MySQL에 비해 5배의 성능
Based on industry standard benchmarks
0
25,000
50,000
75,000
100,000
125,000
150,000
0
100,000
200,000
300,000
400,000
500,000
600,000
700,000
Aurora MySQL 5.6 MySQL 5.7
11.
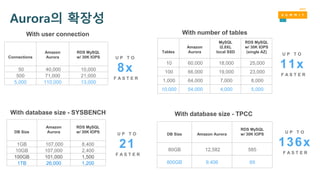
Aurora의 확장성
With userconnection With number of tables
With database size - SYSBENCH With database size - TPCC
Connections
Amazon
Aurora
RDS MySQL
w/ 30K IOPS
50 40,000 10,000
500 71,000 21,000
5,000 110,000 13,000
Tables
Amazon
Aurora
MySQL
I2.8XL
local SSD
RDS MySQL
w/ 30K IOPS
(single AZ)
10 60,000 18,000 25,000
100 66,000 19,000 23,000
1,000 64,000 7,000 8,000
10,000 54,000 4,000 5,000
8x
U P T O
F A S T E R
11x
U P T O
F A S T E R
DB Size
Amazon
Aurora
RDS MySQL
w/ 30K IOPS
1GB 107,000 8,400
10GB 107,000 2,400
100GB 101,000 1,500
1TB 26,000 1,200
DB Size Amazon Aurora
RDS MySQL
w/ 30K IOPS
80GB 12,582 585
800GB 9,406 69
21
U P T O
F A S T E R
136x
U P T O
F A S T E R
12.
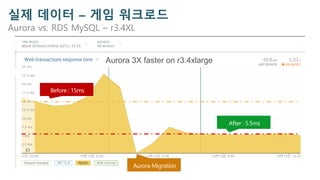
실제 데이터 –게임 워크로드
Aurora vs. RDS MySQL – r3.4XL
Aurora 3X faster on r3.4xlarge
13.
BINLOG DATA DOUBLE-WRITELOGFRM FILES
T Y P E O F W R IT E
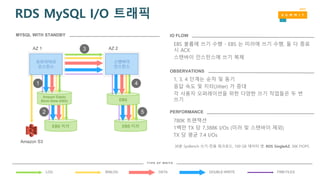
MYSQL WITH STANDBY
EBS 볼륨에 쓰기 수행 - EBS 는 미러에 쓰기 수행, 둘 다 종료
시 ACK
스탠바이 인스턴스에 쓰기 복제
IO FLOW
1, 3, 4 단계는 순차 및 동기
응답 속도 및 지터(Jitter) 가 증대
각 사용자 오퍼레이션을 위한 다양한 쓰기 작업들은 두 번
쓰기
OBSERVATIONS
780K 트랜잭션
1백만 TX 당 7,388K I/Os (미러 및 스탠바이 제외)
TX 당 평균 7.4 I/Os
PERFORMANCE
30분 SysBench 쓰기-전용 워크로드, 100 GB 데이터 셋, RDS SingleAZ, 30K PIOPS
EBS 미러EBS 미러
AZ 1 AZ 2
Amazon S3
EBS
Amazon Elastic
Block Store (EBS)
프라이머리
인스턴스
스탠바이
인스턴스
1
2
3
4
5
RDS MySQL I/O 트래픽
14.
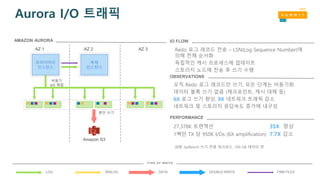
AZ 1 AZ3
프라이머리
인스턴스
Amazon S3
AZ 2
복제
인스턴스
AMAZON AURORA
비동기
4/6 쿼럼
분산 쓰기
BINLOG DATA DOUBLE-WRITELOG FRM FILES
T Y P E O F W R IT E
30분 SysBench 쓰기-전용 워크로드, 100 GB 데이터 셋
IO FLOW
오직 Redo 로그 레코드만 쓰기, 모든 단계는 비동기화
데이터 블록 쓰기 없음 (체크포인트, 캐시 대체 등)
6X 로그 쓰기 향상, 9X 네트워크 트래픽 감소
네트워크 및 스토리지 응답속도 증가에 내구성
OBSERVATIONS
27,378K 트랜잭션 35X 향상
1백만 TX 당 950K I/Os (6X amplification) 7.7X 감소
PERFORMANCE
Redo 로그 레코드 전송 – LSN(Log Sequence Number)에
의해 전체 순서화
독립적인 캐시 프로세스에 업데이트
스토리지 노드에 전송 후 쓰기 수행
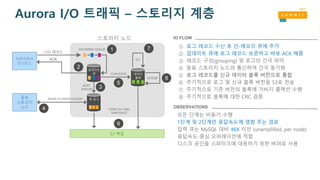
Aurora I/O 트래픽
15.
LOG 레코드
프라이머리
인스턴스
INCOMING QUEUE
스토리지노드
S3 백업
1
2
3
4
5
6
7
8
업데이트
큐
ACK
핫 로그
데이터
블록
POINT IN TIME
SNAPSHOT
GC
SCRUB
COALESCE
SORT
GROUP
PEER-TO-PEER GOSSIP동료
스토리지
노드
모든 단계는 비동기 수행
1단계 및 2단계만 응답속도에 영향 주는 경로
입력 큐는 MySQL 대비 46X 미만 (unamplified, per node)
응답속도-중심 오퍼레이션에 적합
디스크 공간을 스파이크에 대응하기 위한 버퍼로 사용
OBSERVATIONS
IO FLOW
① 로그 레코드 수신 후 인-메모리 큐에 추가
② 업데이트 큐에 로그 레코드 보존하고 바로 ACK 해줌
③ 레코드 구성(grouping) 및 로그의 간극 파악
④ 동료 스토리지 노드와 통신하여 간극 동기화
⑤ 로그 레코드를 신규 데이터 블록 버전으로 통합
⑥ 주기적으로 로그 및 신규 블록 버전을 S3로 전송
⑦ 주기적으로 기존 버전의 블록에 가비지 콜렉션 수행
⑧ 주기적으로 블록에 대한 CRC 검증
Aurora I/O 트래픽 – 스토리지 계층
16.
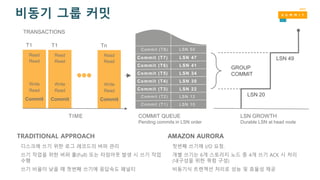
비동기 그룹 커밋
Read
Write
Commit
Read
Read
T1
Commit(T1)
Commit (T2)
Commit (T3)
LSN 10
LSN 12
LSN 22
LSN 50
LSN 30
LSN 34
LSN 41
LSN 47
LSN 20
LSN 49
Commit (T4)
Commit (T5)
Commit (T6)
Commit (T7)
Commit (T8)
LSN GROWTH
Durable LSN at head node
COMMIT QUEUE
Pending commits in LSN order
TIME
GROUP
COMMIT
TRANSACTIONS
Read
Write
Commit
Read
Read
T1
Read
Write
Commit
Read
Read
Tn
TRADITIONAL APPROACH AMAZON AURORA
디스크에 쓰기 위한 로그 레코드의 버퍼 관리
쓰기 작업을 위한 버퍼 풀(Full) 또는 타임아웃 발생 시 쓰기 작업
수행
쓰기 비율이 낮을 때 첫번째 쓰기에 응답속도 페널티
첫번째 쓰기에 I/O 요청.
개별 쓰기는 6개 스토리지 노드 중 4개 쓰기 ACK 시 처리
(내구성을 위한 쿼럼 구성)
비동기식 트랜잭션 처리로 성능 및 효율성 제공
17.
Aurora I/O 트래픽– 읽기 복제
페이지 캐시
업데이트
Aurora 마스터
30% 읽기
70% 쓰기
Aurora 복제
100% 신규 읽기
공유 Multi-AZ 스토리지
MySQL 마스터
30% 읽기
70% 쓰기
MySQL 복제
30% 신규 읽기
70% 쓰기
싱글-스레드
BINLOG 전송
데이터 볼륨 데이터 볼륨
Logical: SQL 문을 복제에 적용
쓰기 부하는 양쪽 노드에서 유사
별도 스토리지
마스터 및 복제 사이에 데이터 차이 존재
Physical: 마스터에서 복제로 redo를 전송
복제는 스토리지를 공유
쓰기 수행 없음
캐시된 페이지는 Redo 적용
MYSQL READ SCALING AMAZON AURORA READ SCALING
18.
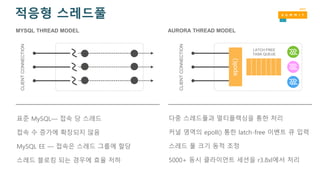
다중 스레드풀과 멀티플렉싱을통한 처리
커널 영역의 epoll() 통한 latch-free 이벤트 큐 입력
스레드 풀 크기 동적 조정
5000+ 동시 클라이언트 세션을 r3.8xl에서 처리
표준 MySQL— 접속 당 스레드
접속 수 증가에 확장되지 않음
MySQL EE — 접속은 스레드 그룹에 할당
스레드 블로킹 되는 경우에 효율 저하
CLIENTCONNECTION
CLIENTCONNECTION
LATCH FREE
TASK QUEUE
epoll()
MYSQL THREAD MODEL AURORA THREAD MODEL
적응형 스레드풀
19.
Scan
Delete
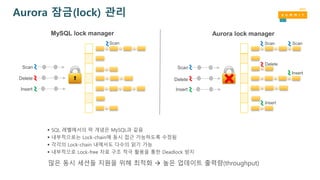
Aurora 잠금(lock) 관리
Scan
Delete
Insert
ScanScan
Insert
Delete
Scan
Insert
Insert
MySQL lock manager Aurora lock manager
SQL 레벨에서의 락 개념은 MySQL과 같음
내부적으로는 Lock-chain에 동시 접근 가능하도록 수정됨
각각의 Lock-chain 내에서도 다수의 읽기 가능
내부적으로 Lock-free 자료 구조 적극 활용을 통한 Deadlock 방지
많은 동시 세션들 지원을 위해 최적화 높은 업데이트 출력량(throughput)
20.
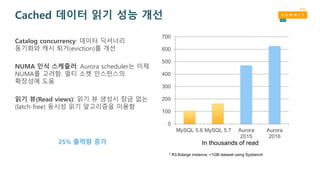
Cached 데이터 읽기성능 개선
Catalog concurrency: 데이터 딕셔너리
동기화와 캐시 퇴거(eviction)를 개선
NUMA 인식 스케줄러: Aurora scheduler는 이제
NUMA를 고려함. 멀티 소켓 인스턴스의
확장성에 도움
읽기 뷰(Read views): 읽기 뷰 생성시 잠금 없는
(latch-free) 동시성 읽기 알고리즘을 이용함
0
100
200
300
400
500
600
700
MySQL 5.6 MySQL 5.7 Aurora
2015
Aurora
2016
In thousands of read
* R3.8xlarge instance, <1GB dataset using Sysbench
25% 출력량 증가
21.
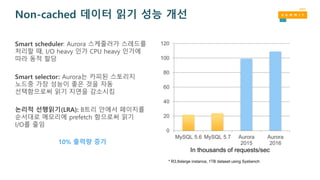
Smart scheduler: Aurora스케줄러가 스레드를
처리할 때, I/O heavy 인가 CPU heavy 인가에
따라 동적 할당
Smart selector: Aurora는 카피된 스토리지
노드중 가장 성능이 좋은 것을 자동
선택함으로써 읽기 지연을 감소시킴
논리적 선행읽기(LRA): B트리 안에서 페이지를
순서대로 메모리에 prefetch 함으로써 읽기
I/O를 줄임
Non-cached 데이터 읽기 성능 개선
0
20
40
60
80
100
120
MySQL 5.6 MySQL 5.7 Aurora
2015
Aurora
2016
In thousands of requests/sec
* R3.8xlarge instance, 1TB dataset using Sysbench
10% 출력량 증가
22.
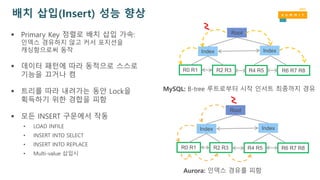
Primary Key정렬로 배치 삽입 가속:
인덱스 경유하지 않고 커서 포지션을
캐싱함으로써 동작
데이터 패턴에 따라 동적으로 스스로
기능을 끄거나 켬
트리를 따라 내려가는 동안 Lock을
획득하기 위한 경합을 피함
모든 INSERT 구문에서 작동
• LOAD INFILE
• INSERT INTO SELECT
• INSERT INTO REPLACE
• Multi-value 삽입시
배치 삽입(Insert) 성능 향상
Index
R4 R5R2 R3R0 R1 R6 R7 R8
Index
Root
Index
R4 R5R2 R3R0 R1 R6 R7 R8
Index
Root
MySQL: B-tree 루트로부터 시작 인서트 최종까지 경유
Aurora: 인덱스 경유를 피함
23.
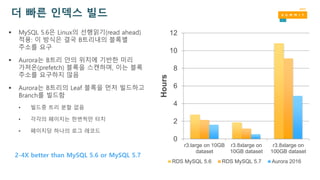
더 빠른 인덱스빌드
MySQL 5.6은 Linux의 선행읽기(read ahead)
적용: 이 방식은 결국 B트리내의 블록별
주소를 요구
Aurora는 B트리 안의 위치에 기반한 미리
가져온(prefetch) 블록을 스캔하며, 이는 블록
주소를 요구하지 않음
Aurora는 B트리의 Leaf 블록을 먼저 빌드하고
Branch를 빌드함
• 빌드중 트리 분할 없음
• 각각의 페이지는 한번씩만 터치
• 페이지당 하나의 로그 레코드
2-4X better than MySQL 5.6 or MySQL 5.7
0
2
4
6
8
10
12
r3.large on 10GB
dataset
r3.8xlarge on
10GB dataset
r3.8xlarge on
100GB dataset
Hours RDS MySQL 5.6 RDS MySQL 5.7 Aurora 2016
24.
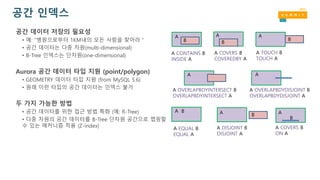
공간 인덱스
공간 데이터저장의 필요성
• 예: “병원으로부터 1KM내의 모든 사람을 찾아라"
• 공간 데이터는 다중 차원(multi-dimensional)
• B-Tree 인덱스는 단차원(one-dimensional)
Aurora 공간 데이터 타입 지원 (point/polygon)
• GEOMETRY 데이터 타입 지원 (from MySQL 5.6)
• 원래 이런 타입의 공간 데이터는 인덱스 불가
두 가지 가능한 방법
• 공간 데이터를 위한 접근 방법 특화 (예: R-Tree)
• 다중 차원의 공간 데이터를 B-Tree 단차원 공간으로 맵핑할
수 있는 메커니즘 적용 (Z-index)
A
B
A A
A A
A A A
B
B
B
B
B
A COVERS B
COVEREDBY A
A CONTAINS B
INSIDE A
A TOUCH B
TOUCH A
A OVERLAPBDYINTERSECT B
OVERLAPBDYINTERSECT A
A OVERLAPBDYDISJOINT B
OVERLAPBDYDISJOINT A
A EQUAL B
EQUAL A
A DISJOINT B
DISJOINT A
A COVERS B
ON A
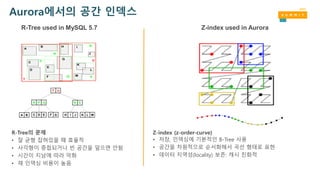
25.
Aurora에서의 공간 인덱스
Z-indexused in Aurora
R-Tree의 문제
• 잘 균형 잡혀있을 때 효율적
• 사각형이 중첩되거나 빈 공간을 덮으면 안됨
• 시간이 지남에 따라 악화
• 재 인덱싱 비용이 높음
R-Tree used in MySQL 5.7
Z-index (z-order-curve)
• 저장, 인덱싱에 기본적인 B-Tree 사용
• 공간을 차원적으로 순서화해서 곡선 형태로 표현
• 데이터 지역성(locality) 보존: 캐시 친화적
Oracle과 가장호환성이 높은 오픈 소스 데이터베이스
20 년간 활발히 개발 중
혁신 친화적인 오픈소스 라이센스
회사가 아니라 재단에 의해 소유됨
높은 성능
객체 지향과 ANSI-SQL:2008 호환
오픈 소스중에서 가장 뛰어난 공간정보 기능 보유
12가지 언어로 스토어드 프로시저 지원
Java, Perl, Python, Ruby, Tcl, C/C++, PL/pgSQL 등
AWS Schema Conversion Tool을 사용해서 Oracle로 부터
PostgreSQL 전환에 있어서 가장 높은 자동 전환률
PostgreSQL 개요
Open Source Initiative
29.
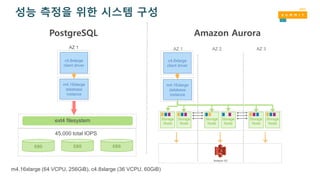
PostgreSQL
성능 측정을 위한시스템 구성
Amazon Aurora
AZ 1
EBS EBS EBS
45,000 total IOPS
AZ 1 AZ 2 AZ 3
Amazon S3
m4.16xlarge
database
instance
Storage
Node
Storage
Node
Storage
Node
Storage
Node
Storage
Node
Storage
Node
c4.8xlarge
client driver
m4.16xlarge
database
instance
c4.8xlarge
client driver
ext4 filesystem
m4.16xlarge (64 VCPU, 256GiB), c4.8xlarge (36 VCPU, 60GiB)
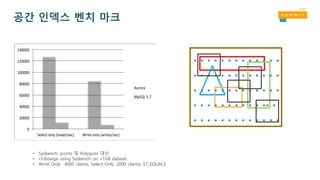
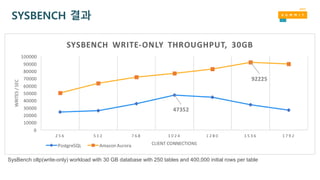
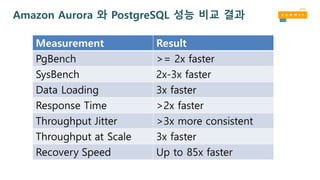
더 빠른 응답시간
SysBench oltp(write-only) 23GiB workload with 250 tables and 300,000 initial rows per table. 10-minute warmup.
34.
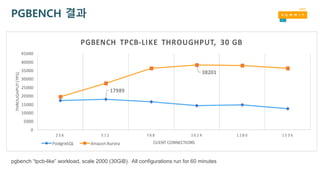
더욱 일관성있는 출력(Throughput)
PgBench“tpcb-like” workload at scale 2000. Amazon Aurora was run with 1280 clients. PostgreSQL was run with
512 clients (the concurrency at which it delivered the best overall throughput)
35.
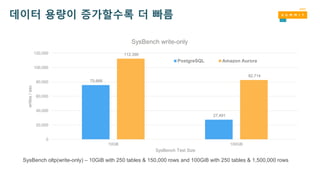
데이터 용량이 증가할수록더 빠름
SysBench oltp(write-only) – 10GiB with 250 tables & 150,000 rows and 100GiB with 250 tables & 1,500,000 rows
75,666
27,491
112,390
82,714
0
20,000
40,000
60,000
80,000
100,000
120,000
10GB 100GB
writes/sec
SysBench Test Size
SysBench write-only
PostgreSQL Amazon Aurora
36.
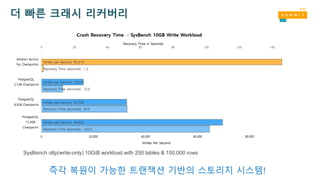
더 빠른 크래시리커버리
SysBench oltp(write-only) 10GiB workload with 250 tables & 150,000 rows
즉각 복원이 가능한 트랜잭션 기반의 스토리지 시스템!
직접 사용해보기
• AmazonAurora for PostgreSQL 업데이트
• https://aws.amazon.com/ko/blogs/korea/amazon-aurora-
update-postgresql-compatibility/
• 테스트를 위한 프리뷰 신청
• https://pages.awscloud.com/amazon-aurora-with-
postgresql-compatibility-preview-form.html
39.
성능 모범 사례
기존의 SQL레벨의 RDBMS 성능 향상 방식은 여전히 동일
가능한 동시접속 사용을 높임
Aurora 출력량은 커넥션 갯수에 따라 증가
읽기 확장을 적극 활용
리드 복제의 지연이 극히 낮음, 여러 읽기 분산으로 전체 성능 향상
파라미터 튜닝
기존의 모든 MySQL파라미터를 Aurora에 적용할 필요 없음
기본 Aurora 파라미터는 충분히 최적화
퍼포먼스 비교
개별 지표(CPU, IOPS, IO throughput)에 너무 의존하 말 것
어플리케이션 측에서의 실제 성능 확인
기타
CloudWatch 메트릭 참고
• DEF CON5년 연속 진출 경험의 Real Geeks
• 국내 유명 해커그룹 “WOWHACKER”의 핵심 멤버들의 모임
• 미국 San Francisco의 본사와 서울 R&D센터 운영중
• 세계 보안업계 최초 SaaS기반의 모바일 앱 보안 서비스 런칭
최고의 화이트햇 해커들과 보안 전문자들
이 모인 Cyber Security 스타트업
Company
43.
Why mobile appsecurity?
앱 보안없이 시장에 출시할
경우
소스코드 추출 앱 위변조 크랙 버전 제작
불법 결제 광고 제거 메모리 해킹
44.
앱 개발 과정에
충분치않은 시간
보안 투자에는 부족한
재정적 지원
보안 관련 지식의 부재
앱 개발자 및 개발사가 겪는 보안적용의 어려움
Mobile security is difficult?
45.
간편한
업로드 & 다운로드
저렴한비용 보안 걱정 해결
앱 개발자 및 개발사가 겪는 보안적용의 어려움
Mobile security is Not difficult!
46.
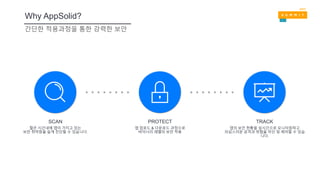
간단한 적용과정을 통한강력한 보안
Why AppSolid?
짧은 시간내에 앱이 가지고 있는
보안 취약점을 쉽게 진단할 수 있습니다.
SCAN
앱 업로드 & 다운로드 과정으로
바이너리 레벨의 보안 적용
PROTECT
앱의 보안 현황을 실시간으로 모니터링하고
의심스러운 공격과 위협을 차단 및 제어할 수 있습
니다.
TRACK
47.
금융 서비스 게임기업 SNS 헬스케어 모바일 상거래 디지털 미디어
AppSolid Protects :
공공/교육기관
48.
Complete approach tomobile sec
AppSolid for iOSAppSolid for Android AppSolid Plugin for Unity 3D
• 앱 보안모니터링 : 1 to N 비즈니스 모델
• 고객앱 사용증가 → 트래픽 기하급수적 증가
• 단일 서비스 포인트 구성으로 인한 불안감 고조
• 글로벌 서비스: 고객의 지리적 위치 다변화
• SLA보장
• 고객 요구사항 증가
• 발빠른 대처 필요
서비스 성장으로 인한 변화
Traffic Load
서비스 응답시간
서비스 배포시간
53.
쉽게 사용할 수있
는
UX / UI
다양한 참고자
료
- 커뮤니티, 백서
,
Issue track, etc
SDK & CLI support
- Java and Python
Migration에 드는
비용 최소화
- Anonymous file upload
with a signed URL 지원
Why AWS?
54.
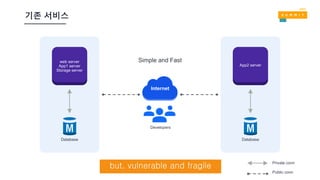
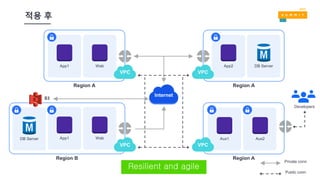
적용 후
App1 Web
VPC
Internet
App1WebDB Server
S3
Private conn
App2 DB Server
VPC
VPC
Aux1
VPC
Aux2
Public conn
Region A Region A
Region ARegion B
Resilient and agile
Developers
Why AWS?Migration
Aurora Instance생성
AWS DMS
(Data Migration Service)
DB Endpoint 변경
• MySQL to Aurora Instance
• CDC(Change Data Capture)
• DB Parameter Group
61.
Benefit
용량 관리 필요없음- 64T까지
속도개선 • Read 분산(clustering)에 의한 writer 부하 경감 (37%)
Fail over에 대한 가용성 향상 - Multi-AZ 클러스터 구성
62.
본 강연이 끝난후
• Amazon Aurora Getting Started
• https://aws.amazon.com/rds/aurora/
• Amazon Aurora Best Practices
• http://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/
Aurora.BestPractices.html
https://www.awssummit.kr
AWS Summit 모바일앱을 통해 지금 세션 평가에
참여하시면, 행사 후 기념품을 드립니다.
#AWSSummit 해시태그로 소셜 미디어에 여러분의
행사 소감을 올려주세요.
발표 자료 및 녹화 동영상은 AWS Korea 공식 소셜
채널로 곧 공유될 예정입니다.
여러분의 피드백을 기다립니다!













































![[236] 카카오의데이터파이프라인 윤도영](https://cdn.slidesharecdn.com/ss_thumbnails/236-161025031702-thumbnail.jpg?width=640&height=640&fit=bounds)











![대용량 데이터레이크 마이그레이션 사례 공유 [카카오게임즈 - 레벨 200] - 조은희, 팀장, 카카오게임즈 ::: Games on AWS ...](https://cdn.slidesharecdn.com/ss_thumbnails/t4s2-221108115925-5b63bf11-thumbnail.jpg?width=640&height=640&fit=bounds)







![[Games on AWS 2019] AWS 사용자를 위한 만랩 달성 트랙 | Aurora로 게임 데이터베이스 레벨 업! - 김병수 AWS ...](https://cdn.slidesharecdn.com/ss_thumbnails/gamesonaws2019levelupyourgamedatabasewithaurora-191015003557-thumbnail.jpg?width=640&height=640&fit=bounds)



![[D3T2S01] Amazon Aurora MySQL 메이저 버전 업그레이드 및 Amazon B/G Deployments 실습](https://cdn.slidesharecdn.com/ss_thumbnails/d3t2s01amazonaurorabluegreendeployment-240702042226-3ae36566-thumbnail.jpg?width=640&height=640&fit=bounds)










![[D3T1S01] Gen AI를 위한 Amazon Aurora 활용 사례 방법](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s01genaiamazonaurora-240702042912-516e67f4-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S06] Neptune Analytics with Vector Similarity Search](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s06neptuneanalyticsvectorsilimliaritysearch-240702042912-94c41309-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S03] Amazon DynamoDB design puzzlers](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s03amazondynamodbdesignpuzzlers-240702042912-ad6df881-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S04] Aurora PostgreSQL performance monitoring and troubleshooting by use...](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s04aurorapostgresqlperformancemonitoringandtroubleshooting-240702042912-5df626e3-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S07] AWS S3 - 클라우드 환경에서 데이터베이스 보호하기](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s07-240702042911-cb134cd6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S05] Aurora 혼합 구성 아키텍처를 사용하여 예상치 못한 트래픽 급증 대응하기](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s05aurora-240702042911-c7f3f22d-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S02] Aurora Limitless Database Introduction](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s02auroralimitlessdatabaseintroduction-240702042911-cb5552b7-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T2S03] Data&AI Roadshow 2024 - Amazon DocumentDB 실습](https://cdn.slidesharecdn.com/ss_thumbnails/d3t2s03documentdbhandson-240702042224-047bbc2c-thumbnail.jpg?width=640&height=640&fit=bounds)


![[Keynote] 슬기로운 AWS 데이터베이스 선택하기 - 발표자: 강민석, Korea Database SA Manager, WWSO, A...](https://cdn.slidesharecdn.com/ss_thumbnails/d3s01aws-230704014400-3eeae447-thumbnail.jpg?width=640&height=640&fit=bounds)





![[Keynote] Accelerating Business Outcomes with AWS Data - 발표자: Saeed Gharadagh...](https://cdn.slidesharecdn.com/ss_thumbnails/d2s01keynoteacceleratingbusinessoutcomeswithawsdata-230704011737-e053cfca-thumbnail.jpg?width=640&height=640&fit=bounds)


