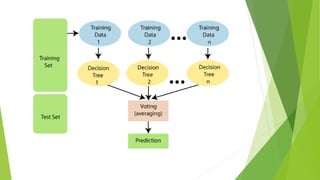
The document discusses regression analysis and random forest machine learning algorithms. It explains that regression analysis is used to predict continuous variables like sales based on related predictor variables like advertisement spending. Regression finds the correlation between variables to enable predictions. Random forest is an ensemble technique that creates multiple decision trees on subsets of data and takes a majority vote of the trees' predictions to improve accuracy. It provides a two-phase working process for random forest involving creating trees on random data samples and then making predictions based on the trees' votes.