Downloaded 36 times

































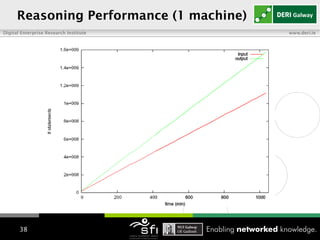







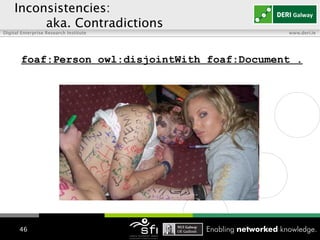










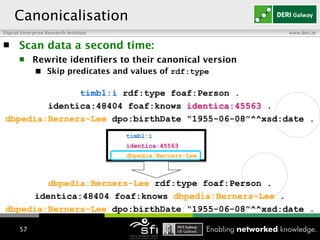











The document discusses using RDFS and OWL reasoning to integrate heterogeneous linked data by addressing issues like terminology and naming heterogeneity. It presents an approach using a subset of OWL 2 RL rules to reason over a billion triple corpus in a scalable way, handling the TBox separately from the ABox to avoid quadratic inferences. It also describes augmenting the reasoning with annotations to track trustworthiness and using this to filter inferences, detect inconsistencies and perform a light repair of the data. Consolidation is discussed as rewriting URIs to canonical identifiers based on owl:sameAs relations. Performance results show the different techniques taking between 1-20 hours to run over the corpus distributed across 9 machines.























































































