Download to read offline







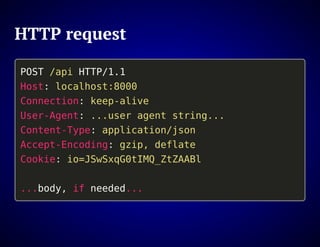
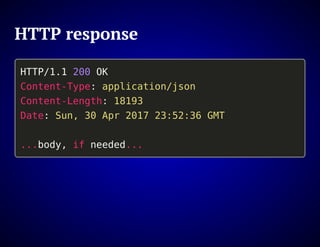









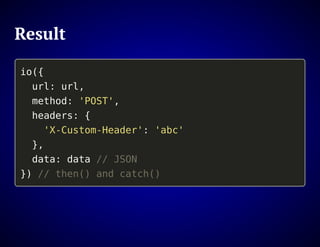




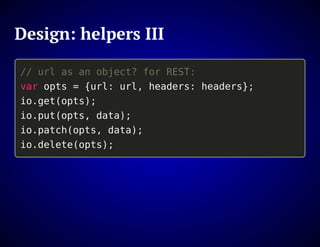




























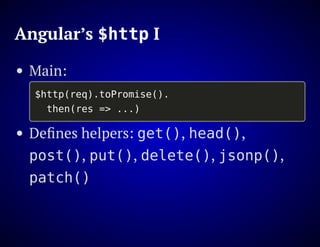



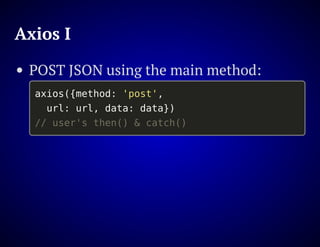

















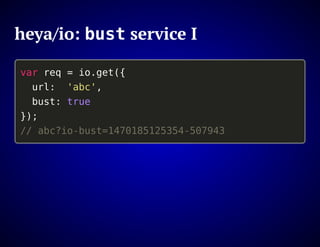
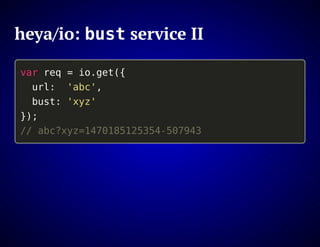






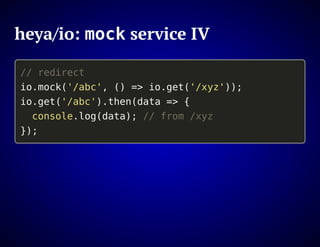







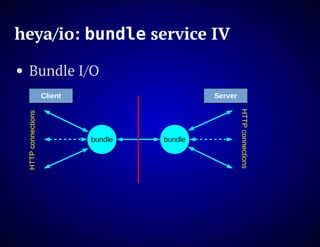










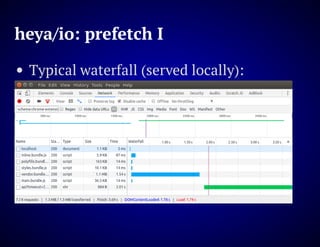


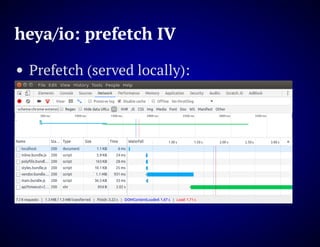

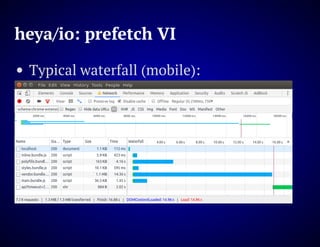
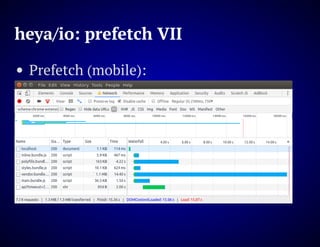






The document outlines the design and functionality of an ideal I/O library for browser applications, highlighting its capabilities compared to existing libraries like Angular and React. It discusses various design decisions, error handling, and features such as caching, bundling, and prefetching to enhance performance and simplify code. Additionally, it emphasizes the importance of user-friendly APIs and presents the heya/io library as a lightweight and extensible solution for modern web development.























































































