Downloaded 579 times
![Practical Web Scraping with Web::Scraper Tatsuhiko Miyagawa [email_address] Six Apart, Ltd. / Shibuya Perl Mongers YAPC::Europe 2007 Vienna](https://image.slidesharecdn.com/webscraper1372/85/Web-Scraper-1-320.jpg)
![Practical Web Scraping with Web::Scraper Tatsuhiko Miyagawa [email_address] Six Apart, Ltd. / Shibuya Perl Mongers YAPC::Europe 2007 Vienna](https://image.slidesharecdn.com/webscraper1372/75/Web-Scraper-1-2048.jpg)















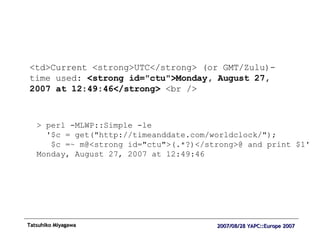
















![XPath <td>Current <strong>UTC</strong> (or GMT/Zulu)-time used: <strong id="ctu">Monday, August 27, 2007 at 12:49:46</strong> <br /> use HTML::TreeBuilder::XPath; my $tree = HTML::TreeBuilder::XPath->new_from_content($content); print $tree->findnodes ('//strong[@id="ctu"]') ->shift->as_text; # Monday, August 27, 2007 at 12:49:46](https://image.slidesharecdn.com/webscraper1372/85/Web-Scraper-36-320.jpg)


![XPath: //strong[@id="ctu"] CSS Selector: strong#ctu](https://image.slidesharecdn.com/webscraper1372/85/Web-Scraper-39-320.jpg)













![$key: key for the result hash append "[]" for looping](https://image.slidesharecdn.com/webscraper1372/85/Web-Scraper-53-320.jpg)


![process "ul.sites > li > a", 'urls[]' => ' @href '; # { urls => [ … ] } <ul class="sites"> <li><a href=" http://vienna.openguides.org/ ">OpenGuides</a></li> <li><a href=" http://vienna.yapceurope.org/ ">YAPC::Europe</a></li> </ul>](https://image.slidesharecdn.com/webscraper1372/85/Web-Scraper-56-320.jpg)
![process '//ul[@class="sites"]/li/a', 'names[]' => ' TEXT '; # { names => [ 'OpenGuides', … ] } <ul class="sites"> <li><a href="http://vienna.openguides.org/"> OpenGuides </a></li> <li><a href="http://vienna.yapceurope.org/"> YAPC::Europe </a></li> </ul>](https://image.slidesharecdn.com/webscraper1372/85/Web-Scraper-57-320.jpg)
![process "ul.sites > li", 'sites[]' => scraper { process 'a', link => '@href', name => 'TEXT'; }; # { sites => [ { link => …, name => … }, # { link => …, name => … } ] }; <ul class="sites"> <li><a href="http://vienna.openguides.org/">OpenGuides</a></li> <li><a href="http://vienna.yapceurope.org/">YAPC::Europe</a></li> </ul>](https://image.slidesharecdn.com/webscraper1372/85/Web-Scraper-58-320.jpg)
![process "ul.sites > li > a", 'sites[]' => sub { # $_ is HTML::Element +{ link => $_->attr('href'), name => $_->as_text }; }; # { sites => [ { link => …, name => … }, # { link => …, name => … } ] }; <ul class="sites"> <li><a href="http://vienna.openguides.org/">OpenGuides</a></li> <li><a href="http://vienna.yapceurope.org/">YAPC::Europe</a></li> </ul>](https://image.slidesharecdn.com/webscraper1372/85/Web-Scraper-59-320.jpg)
![process "ul.sites > li > a", 'sites[]' => { link => '@href', name => 'TEXT'; }; # { sites => [ { link => …, name => … }, # { link => …, name => … } ] }; <ul class="sites"> <li><a href="http://vienna.openguides.org/">OpenGuides</a></li> <li><a href="http://vienna.yapceurope.org/">YAPC::Europe</a></li> </ul>](https://image.slidesharecdn.com/webscraper1372/85/Web-Scraper-60-320.jpg)


![Thumbnail URLs on Flickr set #!/usr/bin/perl use strict; use Data::Dumper; use Web::Scraper; use URI; my $url = "http://flickr.com/photos/bulknews/sets/72157601700510359/"; my $s = scraper { process "a.image_link img", "thumbs[]" => '@src'; }; warn Dumper $s->scrape( URI->new($url) );](https://image.slidesharecdn.com/webscraper1372/85/Web-Scraper-64-320.jpg)

![Twitter Friends #!/usr/bin/perl use strict; use Web::Scraper; use URI; use Data::Dumper; my $url = "http://twitter.com/miyagawa"; my $s = scraper { process "span.vcard a", "people[]" => '@title'; }; warn Dumper $s->scrape( URI->new($url) ) ;](https://image.slidesharecdn.com/webscraper1372/85/Web-Scraper-67-320.jpg)
![Twitter Friends (complex) #!/usr/bin/perl use strict; use Web::Scraper; use URI; use Data::Dumper; my $url = "http://twitter.com/miyagawa"; my $s = scraper { process "span.vcard", "people[]" => scraper { process "a", link => '@href', name => '@title'; process "img", thumb => '@src'; }; }; warn Dumper $s->scrape( URI->new($url) ) ;](https://image.slidesharecdn.com/webscraper1372/85/Web-Scraper-68-320.jpg)


![> scraper http://example.com/ scraper> process "a", "links[]" => '@href'; scraper> d $VAR1 = { links => [ 'http://example.org/', 'http://example.net/', ], }; scraper> y --- links: - http://example.org/ - http://example.net/](https://image.slidesharecdn.com/webscraper1372/85/Web-Scraper-71-320.jpg)









The document discusses practical web scraping using the Web::Scraper module in Perl. It provides an example of scraping the current UTC time from a website using regular expressions, then refactors it to use Web::Scraper for a more robust and maintainable approach. Key advantages of Web::Scraper include using CSS selectors and XPath to be less fragile, and proper handling of HTML encoding.











































































































