Download as PDF, PPTX





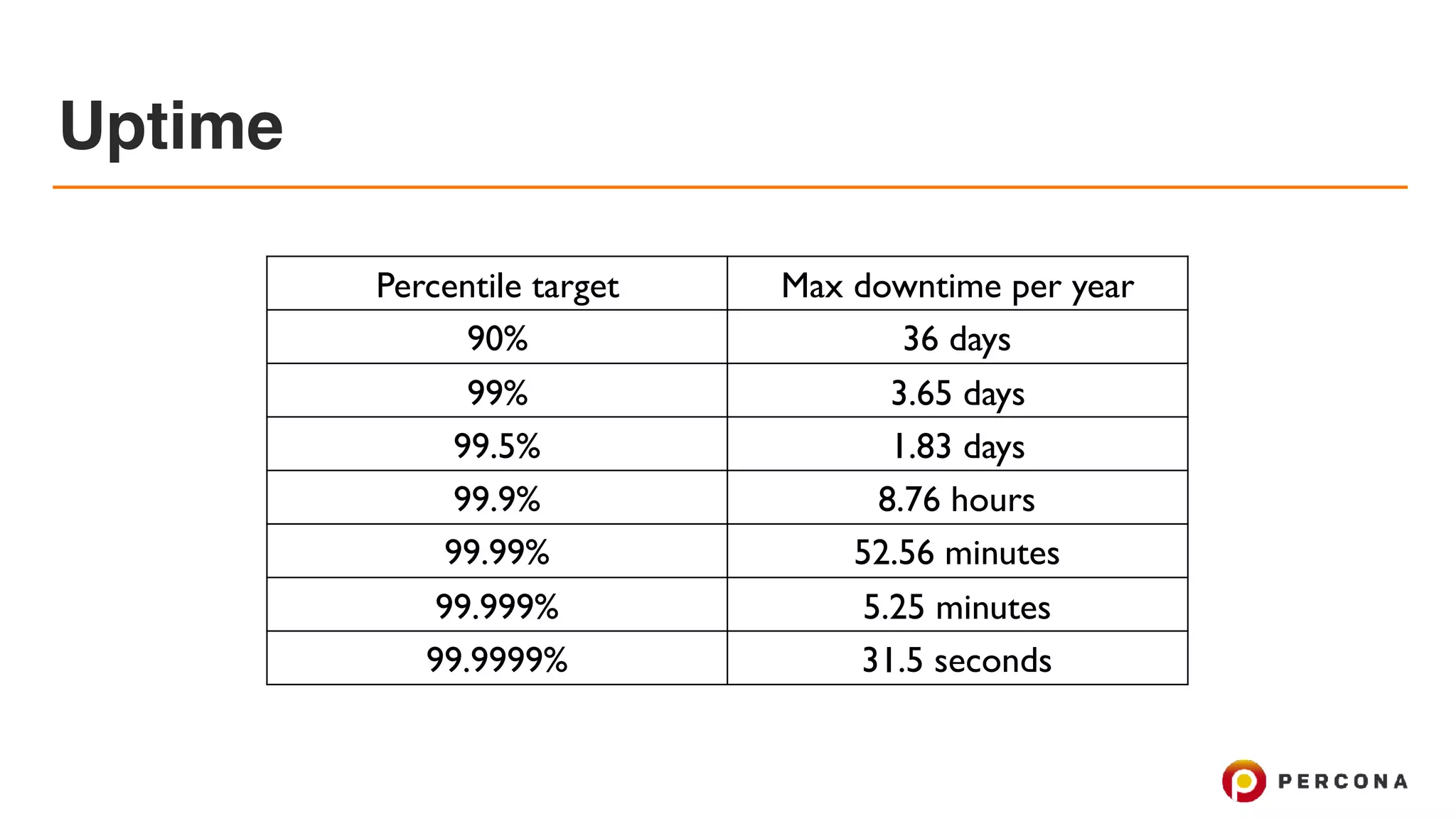
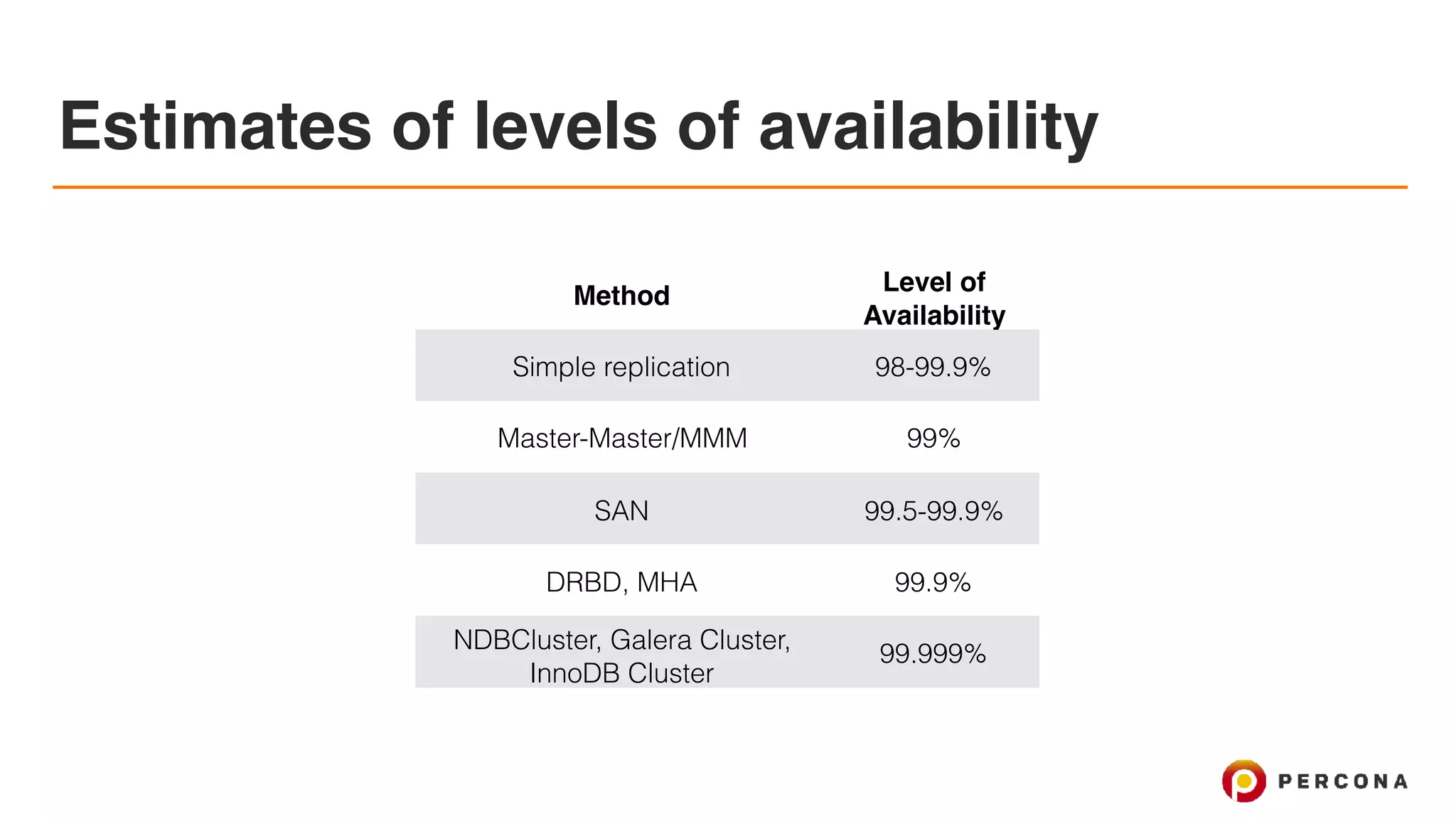












































The document discusses the advancements and best practices in achieving high availability (HA) and scalability in MySQL databases over the past decade, emphasizing various redundancy techniques such as replication and clustering. It highlights tools and frameworks, including Percona's offerings, to enhance MySQL performance and reliability while addressing common challenges like node failure and data integrity. The conclusion notes that effective monitoring and automation are crucial to manage multi-node systems and maintain high availability in modern cloud environments.







































![[db tech showcase Tokyo 2014] B15: Scalability with MariaDB and MaxScale by ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbtstokyo2014b15mariadbcorporationcolincharlesscalabilitywithmariadbandmaxscale-141208020836-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)


























