Downloaded 10 times








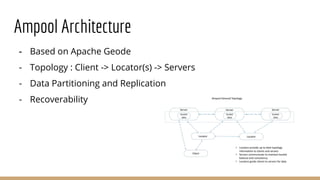
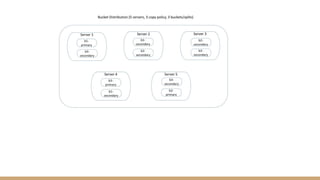









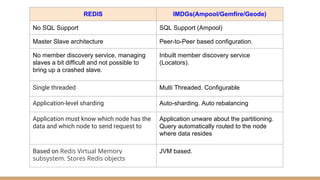








The document discusses in-memory data grids and Ampool. It describes that in-memory data grids like Ampool are sophisticated in-memory data stores that provide low latency reads and writes through data partitioning and replication across a scalable cluster. The document then provides details on Ampool's architecture based on Apache Geode, how it compares favorably to other in-memory solutions in providing both low-latency and analytics capabilities, and demonstrates its performance through examples.




![[Pgday.Seoul 2018] 이기종 DB에서 PostgreSQL로의 Migration을 위한 DB2PG](https://cdn.slidesharecdn.com/ss_thumbnails/04-pgdaydb2pgv1-181112042107-thumbnail.jpg?width=640&height=640&fit=bounds)


















































