Downloaded 32 times






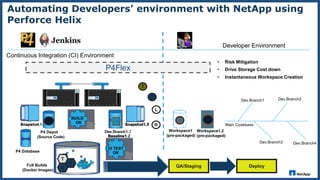



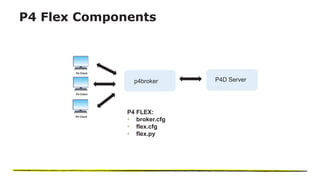


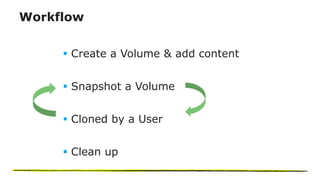
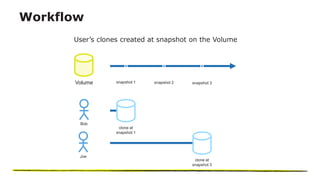



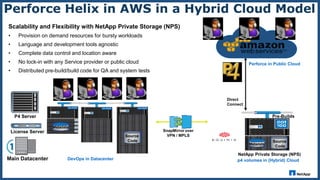

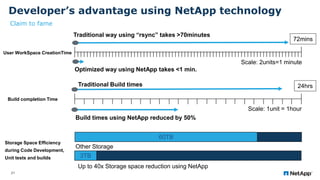


The document presents an overview of NetApp's P4Flex, a tool designed to enhance software development efficiency by automating developers' environments using Perforce Helix CI. It outlines the system requirements, workflows for volume management, and advantages of deploying P4Flex in a hybrid cloud model with NetApp technology. Key benefits include reduced workspace creation time and significant storage space efficiency during development and testing phases.









![[Citrix] Perforce Standardisation at Citrix](https://cdn.slidesharecdn.com/ss_thumbnails/perforce-standardization-citrix-paper-130524110547-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)



























![[NetApp] Managing Big Workspaces with Storage Magic](https://cdn.slidesharecdn.com/ss_thumbnails/storage-magic-netapp-slides-130523182514-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)














![[Paris merge world tour] Perforce Server Update](https://cdn.slidesharecdn.com/ss_thumbnails/paris-mergeworldtourperforceserverupdate-130718052353-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Tel aviv merge world tour] Perforce Server Update](https://cdn.slidesharecdn.com/ss_thumbnails/telavivmergeworldtourperforceserverupdate-130718081007-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[AMD] Novel Use of Perforce for Software Auto-updates and File Transfer](https://cdn.slidesharecdn.com/ss_thumbnails/novel-use-software-auto-updates-slides-130524111001-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)


![[MathWorks] Versioning Infrastructure](https://cdn.slidesharecdn.com/ss_thumbnails/versioning-infrastructure-mathworks-paper-130523183417-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[SAP] Perforce Administrative Self Services at SAP](https://cdn.slidesharecdn.com/ss_thumbnails/admin-self-services-sap-slides-130523171754-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Europe merge world tour] Perforce Server Update](https://cdn.slidesharecdn.com/ss_thumbnails/europe-mergeworldtourperforceserverupdate-130718035120-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)





![[Europe merge world tour] Perforce Europe Merge World Tour Keynote](https://cdn.slidesharecdn.com/ss_thumbnails/europe-mergeworldtourperforceeuropemergeworldtourkeynote-130718034027-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)









































