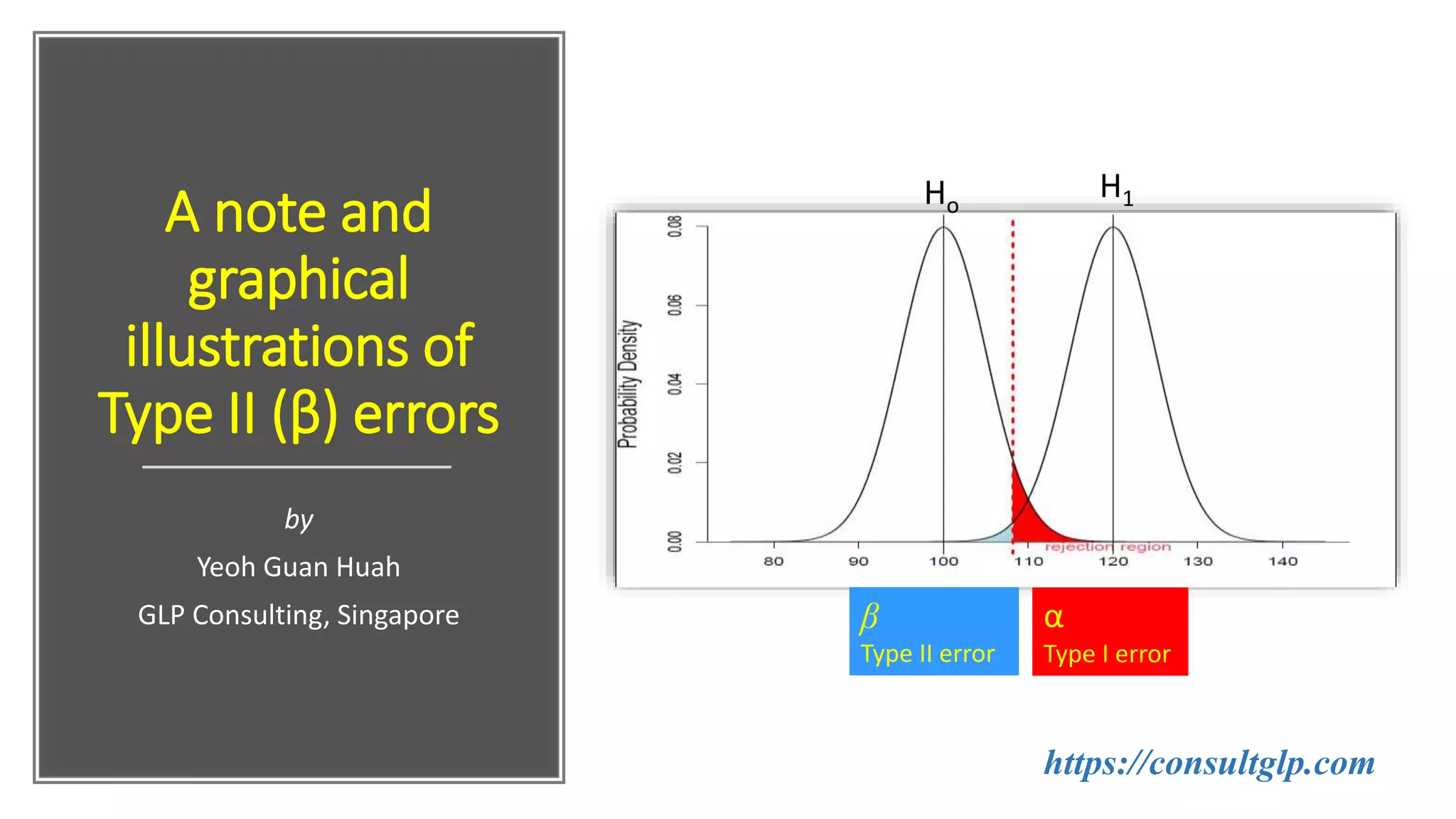
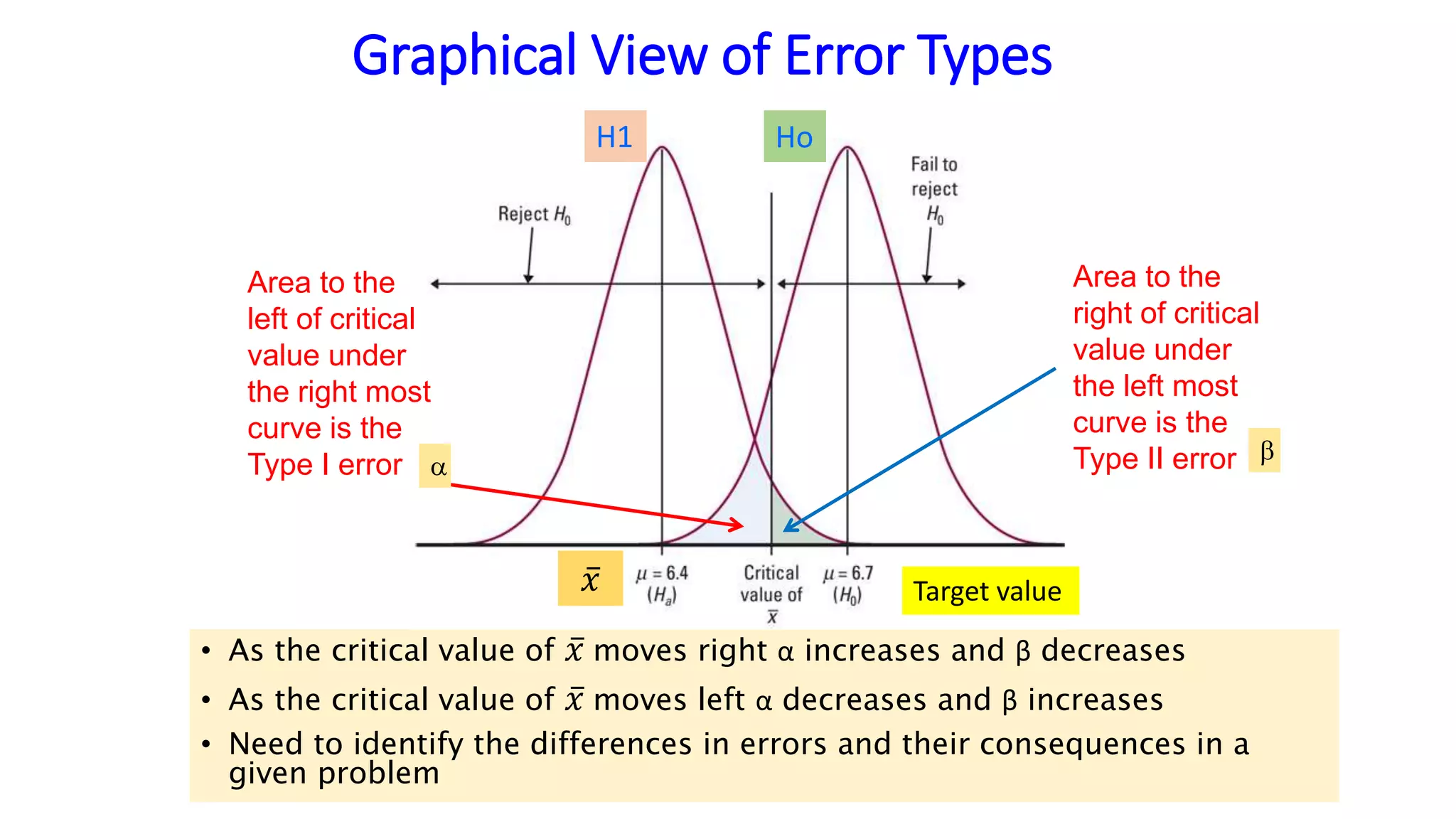
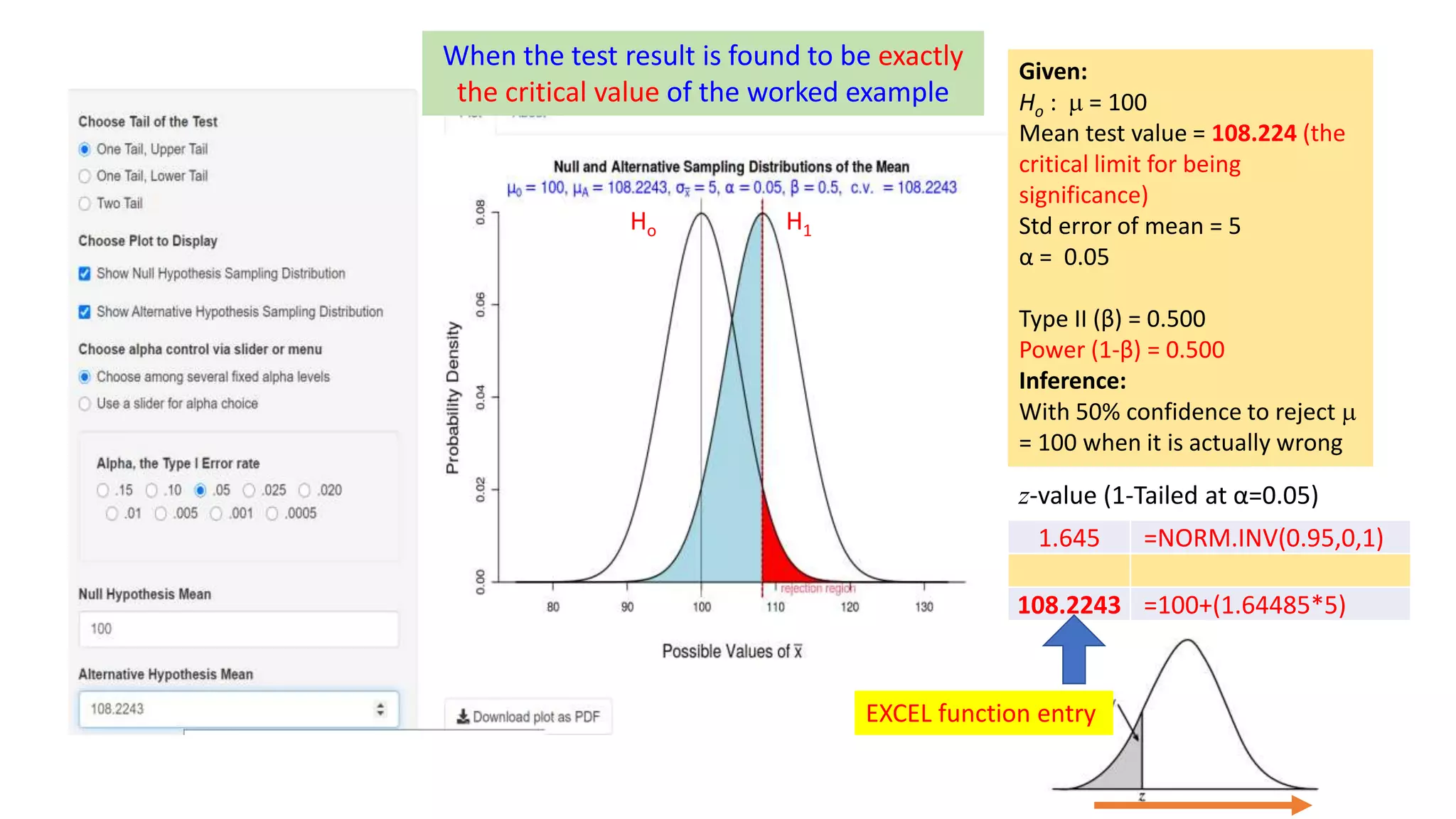
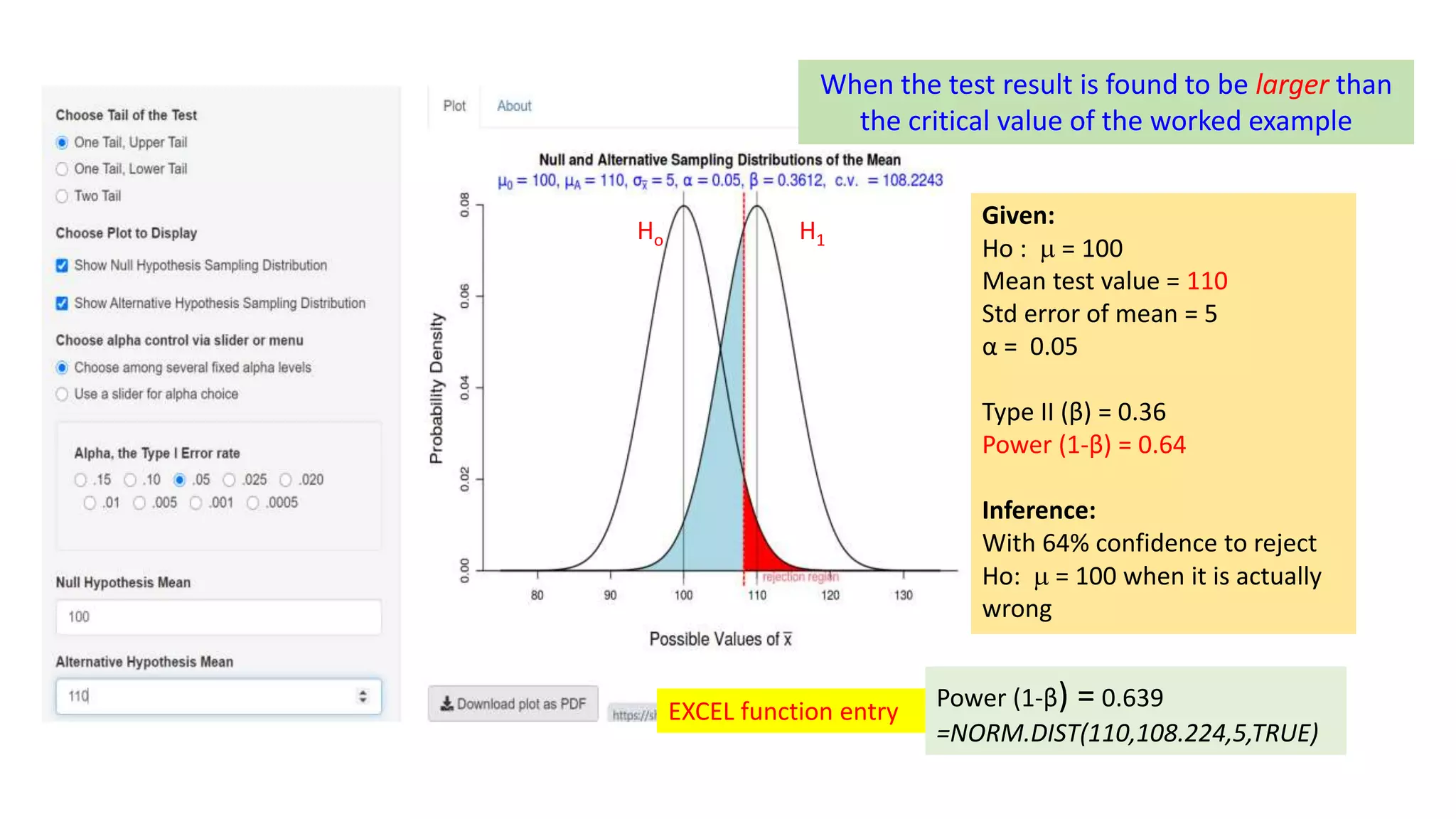
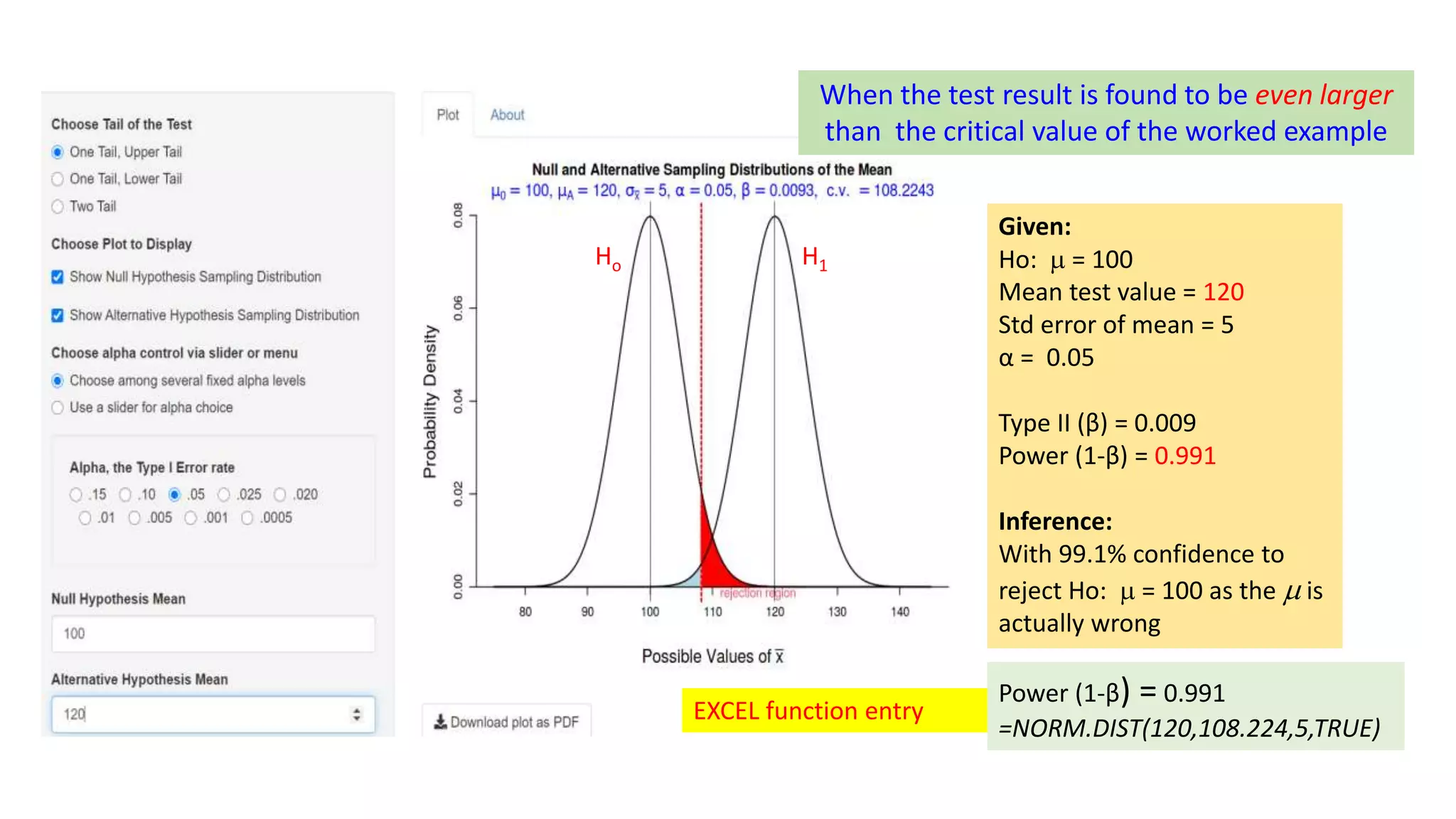
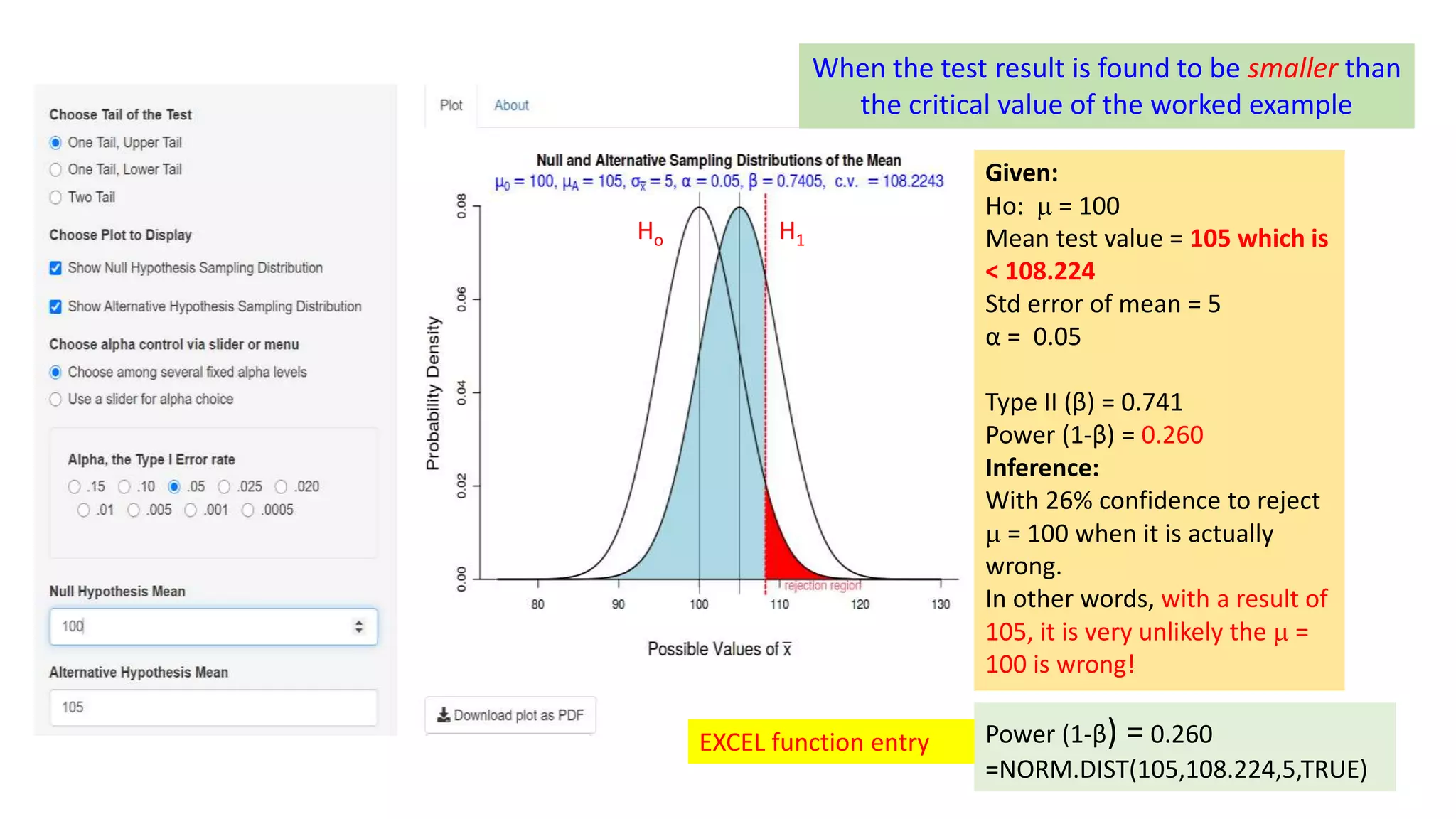
This document discusses Type I and Type II errors in hypothesis testing. It begins by introducing the concepts of Type I errors, which occur when a null hypothesis is incorrectly rejected, and Type II errors, which occur when a null hypothesis is incorrectly accepted. The document then provides examples to illustrate Type I and Type II errors using hypothesis testing on a population mean. It shows how the probabilities of Type I and Type II errors are related and how varying the test value and critical value impacts the likelihood of each type of error. The document concludes by emphasizing that reducing Type I errors increases the risk of Type II errors.