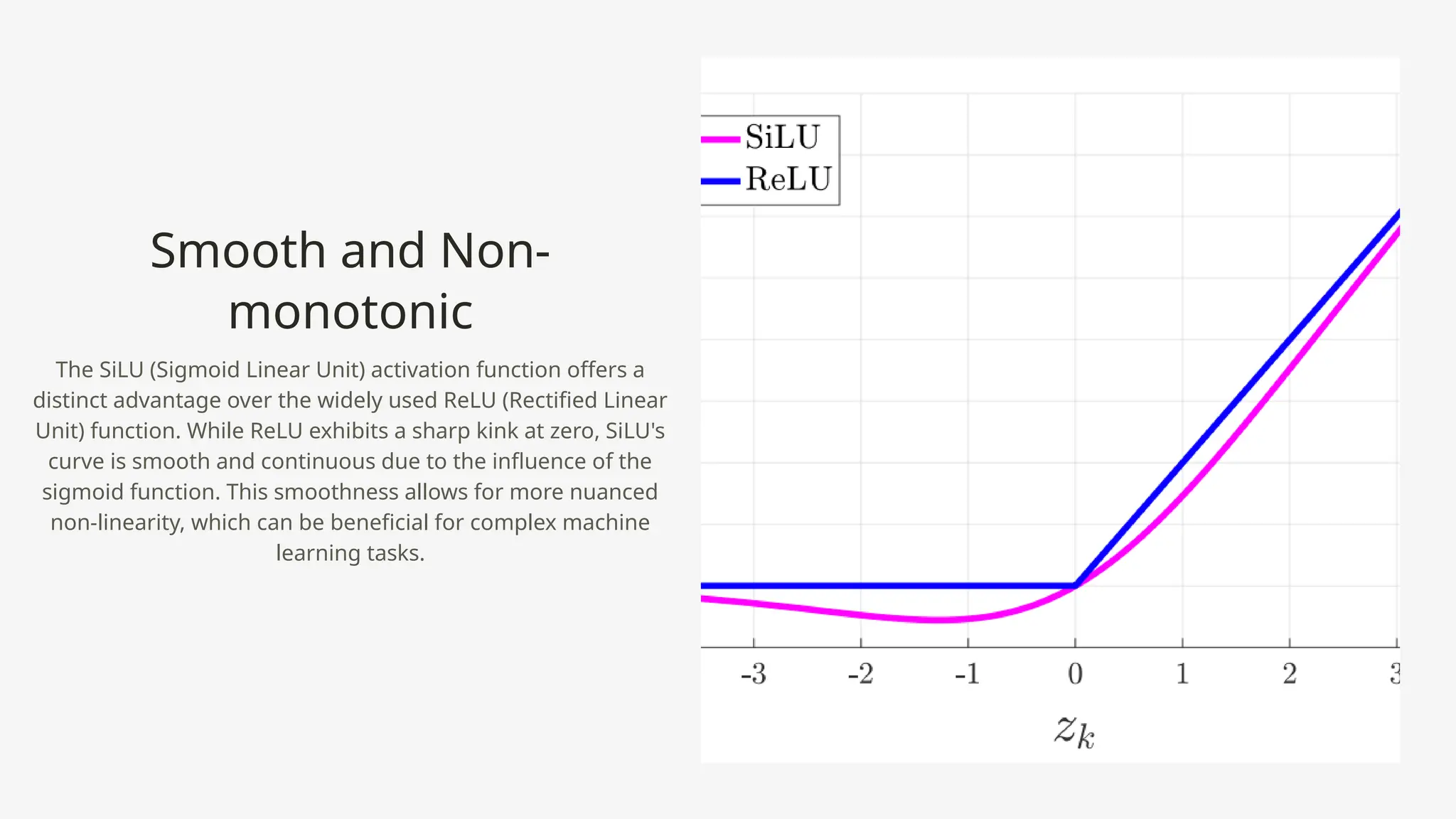
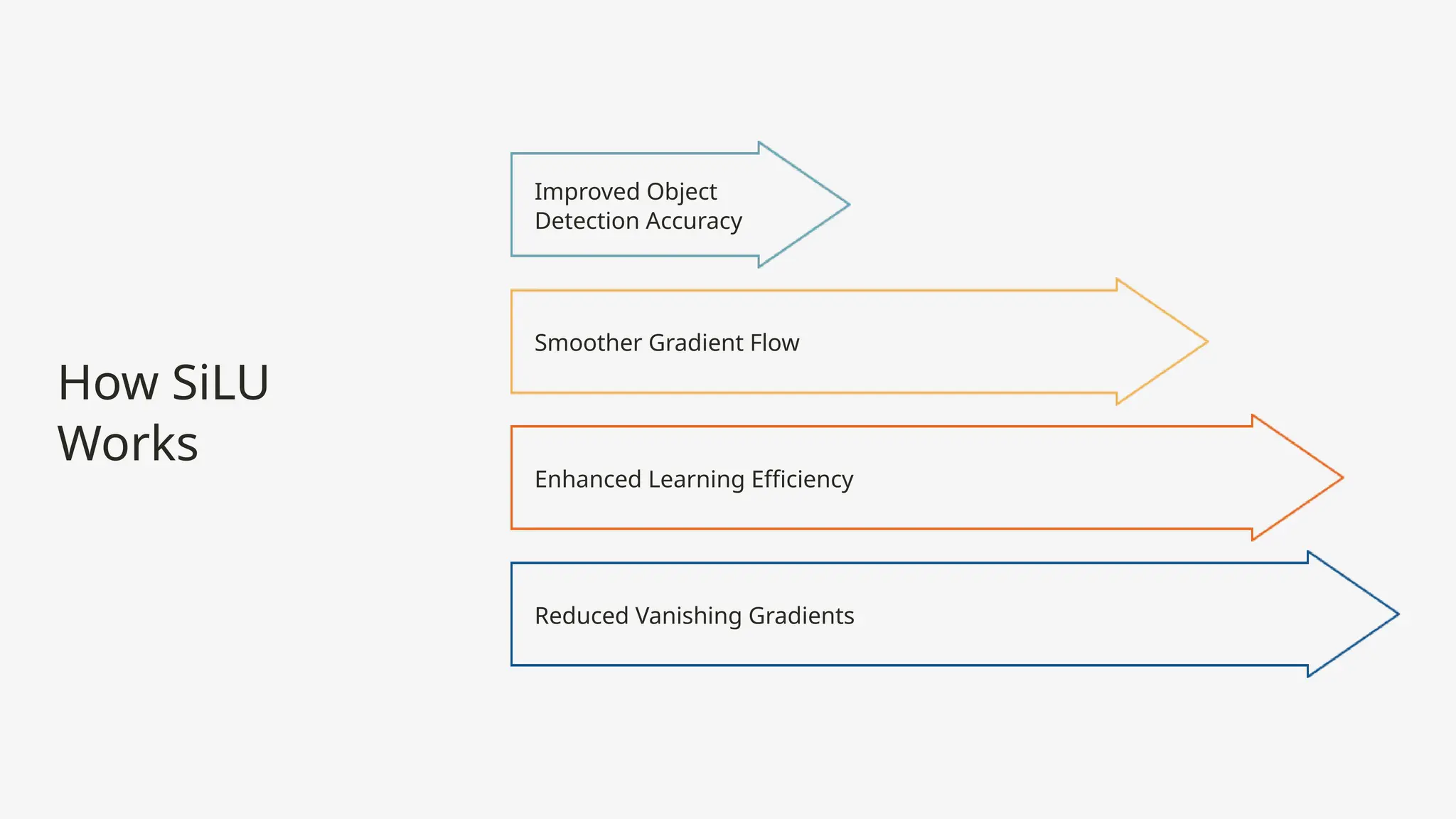
The Silu activation function (sigmoid linear unit) enhances neural networks by combining sigmoid and linear elements, resulting in a smoother, non-monotonic function that improves optimization and expressiveness. Unlike the traditional ReLU, Silu maintains a non-zero gradient, helping to mitigate the vanishing gradient problem and benefiting tasks like object detection in YOLO models. Its distinct characteristics lead to more effective learning and better performance in complex machine learning scenarios.




































![[5] Understanding the YOLOv8 Architecture.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/5understandingtheyolov8architecture-240724131844-70710c0c-thumbnail.jpg?width=640&height=640&fit=bounds)



![[4] - [2] The SIFT Algorithm Unlocking Image Recognition.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/4-2thesiftalgorithmunlockingimagerecognition-240720074301-91a1d13c-thumbnail.jpg?width=640&height=640&fit=bounds)





![[4] - [1] The SIFT Algorithm and Its Formulas.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/4-1thesiftalgorithmanditsformulas-240720073609-35dd0056-thumbnail.jpg?width=640&height=640&fit=bounds)



























