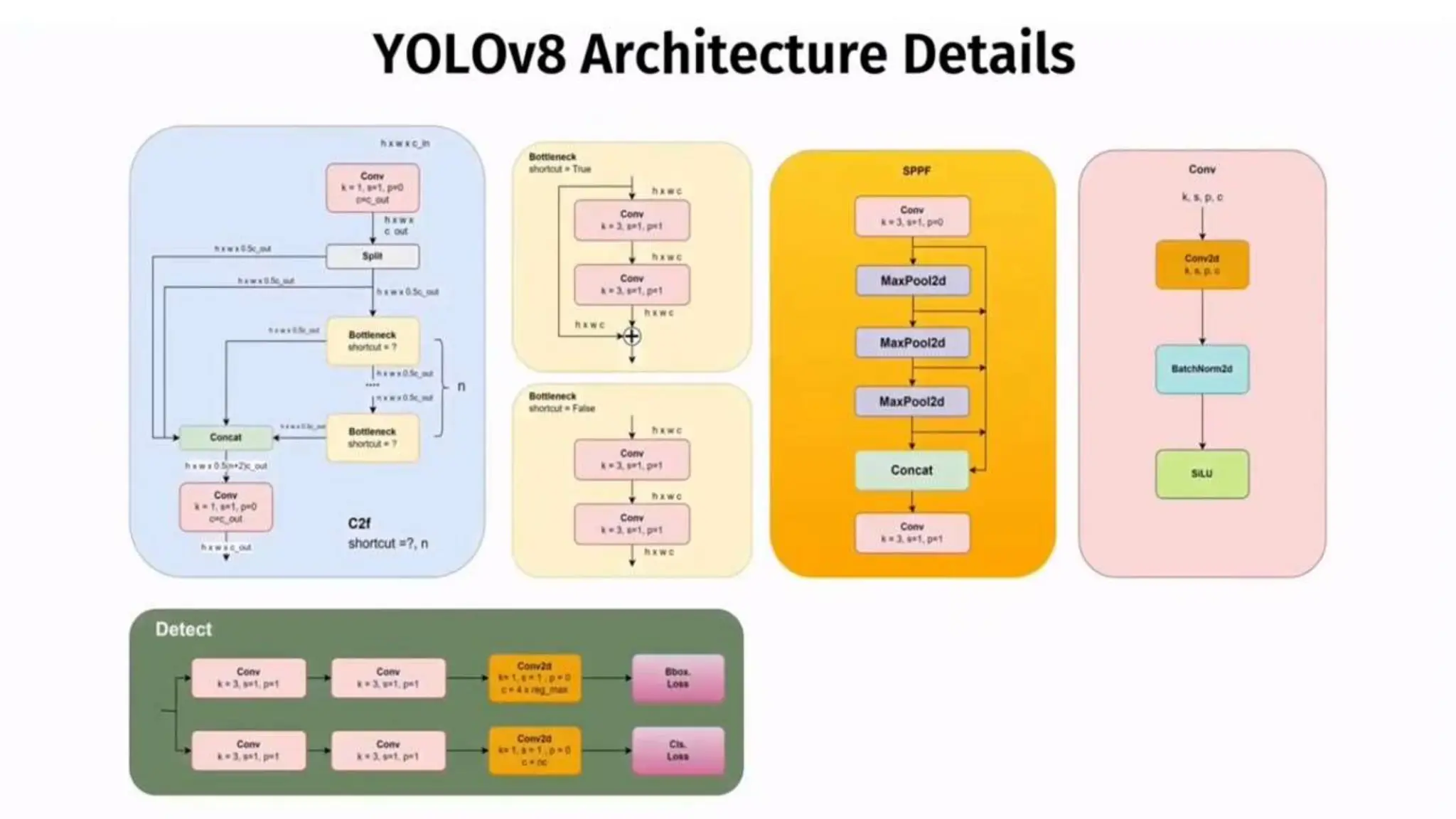
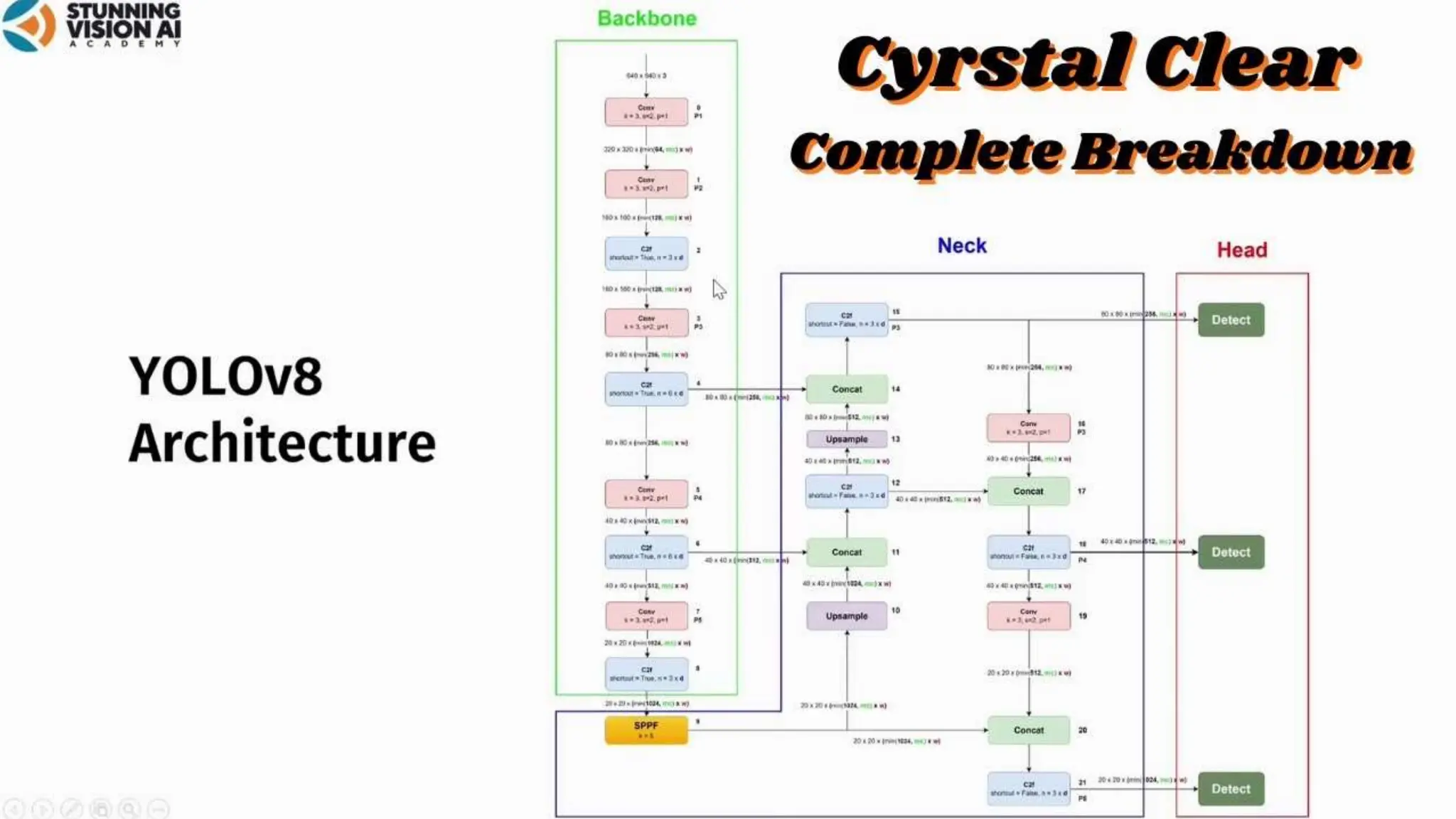
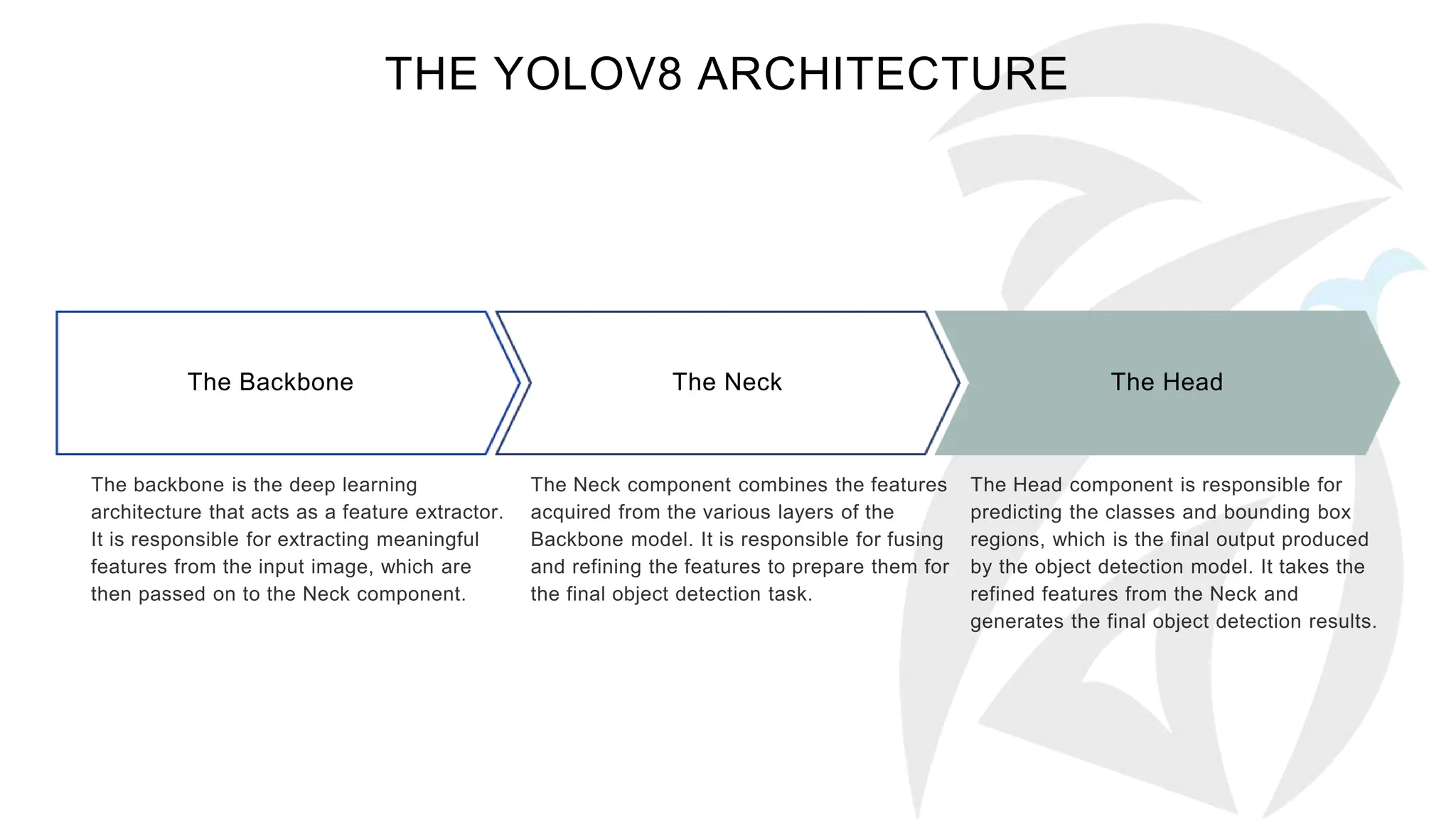
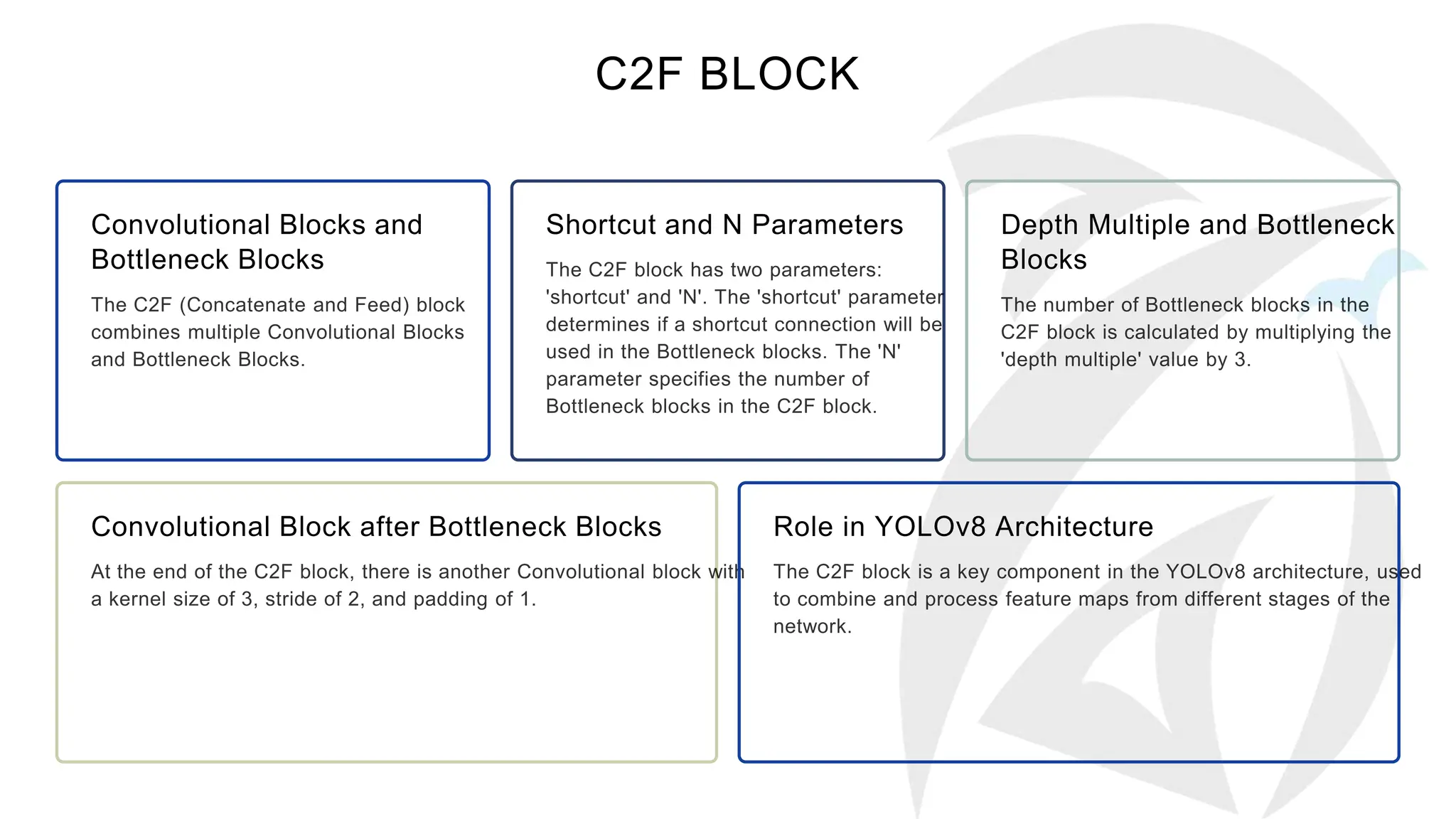
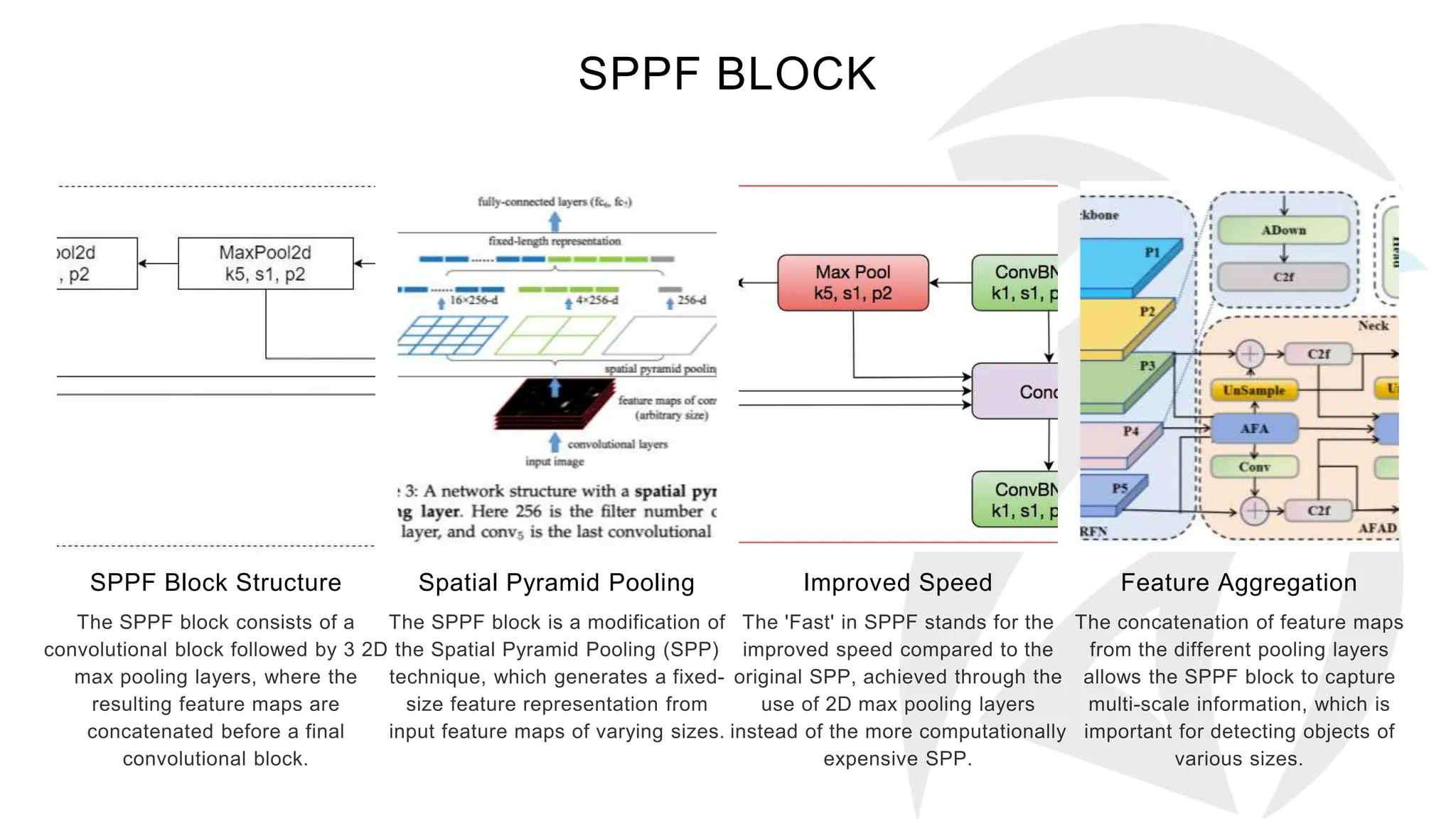
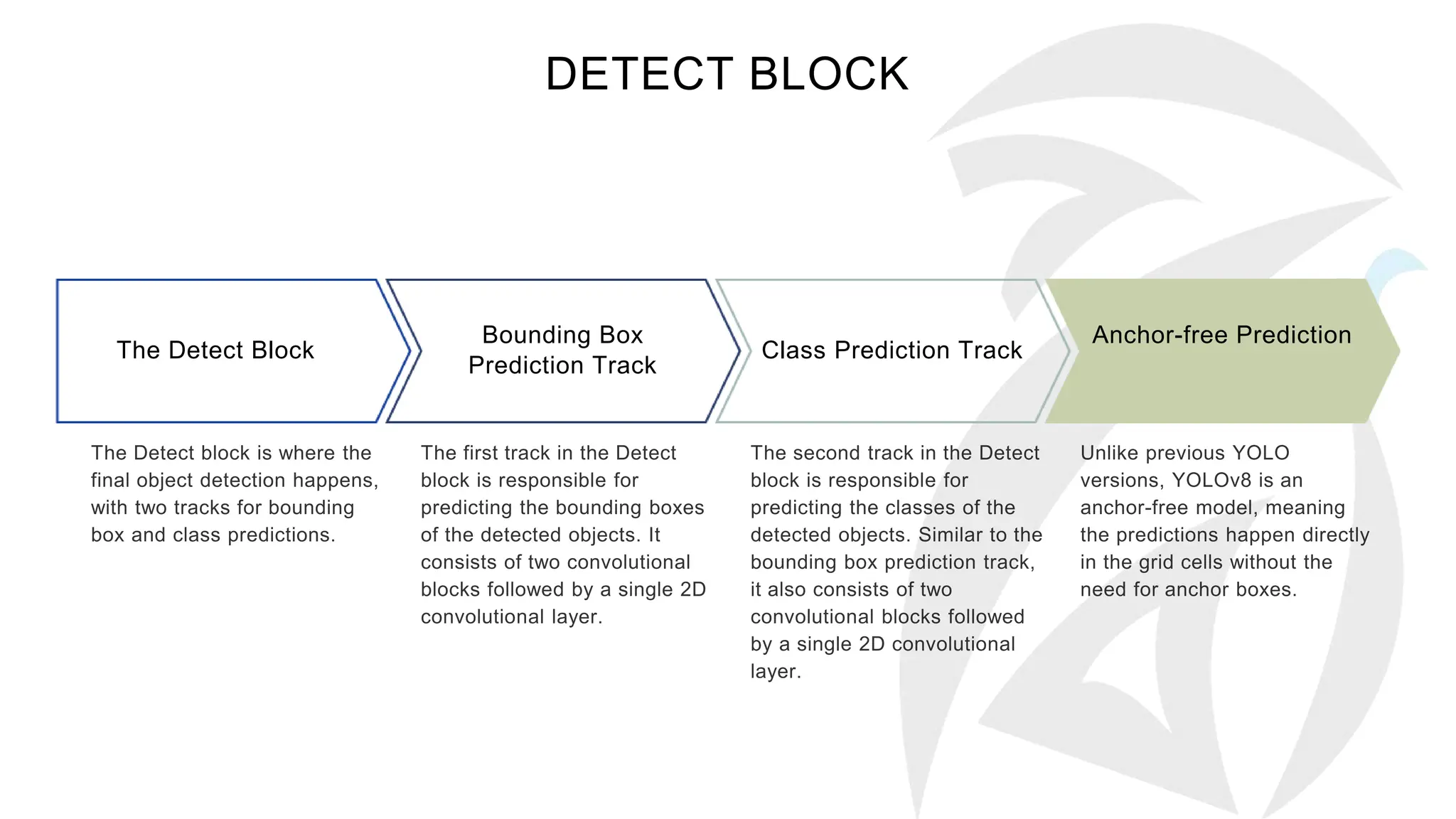
The document describes the YOLOv8 object detection architecture, including its backbone, neck, and head components, which work together for feature extraction, combination, and detection. It details the roles of different blocks, such as convolutional, SPPF, and detect blocks, along with hyper-parameter settings that affect the model's depth and width. Overall, YOLOv8 is presented as a powerful and efficient evolution of its predecessors in object detection.























































![[7] The SiLU Activation Function Unlocking Neural Network Potential.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/7thesiluactivationfunctionunlockingneuralnetworkpotential-240828102029-8df6451c-thumbnail.jpg?width=640&height=640&fit=bounds)
![[4] - [2] The SIFT Algorithm Unlocking Image Recognition.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/4-2thesiftalgorithmunlockingimagerecognition-240720074301-91a1d13c-thumbnail.jpg?width=640&height=640&fit=bounds)
![[4] - [1] The SIFT Algorithm and Its Formulas.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/4-1thesiftalgorithmanditsformulas-240720073609-35dd0056-thumbnail.jpg?width=640&height=640&fit=bounds)



































