Neural Network isa computational learning system that uses a network of functions to
understand and translate a data input of one form into a desired output, usually in another form. The
concept of the artificial neural network was inspired by human biology and the way neurons of the
human brain function together to understand inputs from human senses.
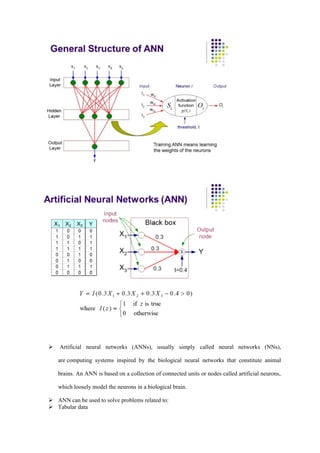
Artificial neuralnetworks (ANNs), usually simply called neural networks (NNs),
are computing systems inspired by the biological neural networks that constitute animal
brains. An ANN is based on a collection of connected units or nodes called artificial neurons,
which loosely model the neurons in a biological brain.
ANN can be used to solve problems related to:
Tabular data
6.
Image data
Text data
Advantages of Artificial Neural Network (ANN)
The term "Artificial Neural Network" is derived from Biological neural networks that develop the
structure of a human brain. Similar to the human brain that has neurons interconnected to one another,
artificial neural networks also have neurons that are interconnected to one another in various layers of
the networks. These neurons are known as nodes.
Input Layer:
As the name suggests, it accepts inputs in several different formats provided by the programmer.
Hidden Layer:
The hidden layer presents in-between input and output layers. It performs all the calculations to find
hidden features and patterns.
Output Layer:
The input goes through a series of transformations using the hidden layer, which finally results in
output that is conveyed using this layer.
The artificial neural network takes input and computes the weighted sum of the inputs and includes a
bias. This computation is represented in the form of a transfer function.
Advantages of Artificial Neural Network (ANN)
Parallel processing capability:
Artificial neural networks have a numerical value that can perform more than one task
simultaneously.
Storing data on the entire network:
Data that is used in traditional programming is stored on the whole network, not on a database. The
disappearance of a couple of pieces of data in one place doesn't prevent the network from working.
Capability to work with incomplete knowledge:
After ANN training, the information may produce output even with inadequate data. The loss of
performance here relies upon the significance of missing data.
Having a memory distribution:
For ANN is to be able to adapt, it is important to determine the examples and to encourage the
network according to the desired output by demonstrating these examples to the network. The
succession of the network is directly proportional to the chosen instances, and if the event can't appear
to the network in all its aspects, it can produce false output.
7.
Disadvantages of ArtificialNeural Network:
Assurance of proper network structure:
There is no particular guideline for determining the structure of artificial neural networks. The
appropriate network structure is accomplished through experience, trial, and error.
Unrecognized behavior of the network:
It is the most significant issue of ANN. When ANN produces a testing solution, it does not provide
insight concerning why and how. It decreases trust in the network.
Hardware dependence:
Artificial neural networks need processors with parallel processing power, as per their structure.
Therefore, the realization of the equipment is dependent.
Difficulty of showing the issue to the network:
ANNs can work with numerical data. Problems must be converted into numerical values before being
introduced to ANN. The presentation mechanism to be resolved here will directly impact the
performance of the network. It relies on the user's abilities.
The duration of the network is unknown:
The network is reduced to a specific value of the error, and this value does not give us optimum
results.
Convolution Neural Networks (CNN):
A convolutional neural network (CNN) is a type of artificial neural network used in image
recognition and processing that is specifically designed to process pixel data.
A CNN uses a system much like a multilayer perceptron that has been designed for reduced
processing requirements. The layers of a CNN consist of an input layer, an output layer and a
hidden layer that includes multiple convolutional layers, pooling layers, fully connected
layers and normalization layers. The removal of limitations and increase in efficiency for
image processing results in a system that is far more effective, simpler to trains limited for
image processing and natural language processing.
Advantages of Convolution Neural Network (CNN)
CNN learns the filters automatically without mentioning it explicitly. These filters help in extracting
the right and relevant features from the input data
Recurrent Neural Networks (RNN):
Recurrent neural networks (RNN) are a class of neural networks that are helpful in modeling sequence
data. Derived from feedforward networks, RNNs exhibit similar behavior to how human brains
8.
function. Simply put:recurrent neural networks produce predictive results in sequential data that other
algorithms can’t.
A usual RNN has a short-term memory. In combination with a LSTM they also have a long-term
memory (more on that later).
Another good way to illustrate the concept of a recurrent neural network's memory is to explain it
with an example:
Imagine you have a normal feed-forward neural network and give it the word "neuron" as an input
and it processes the word character by character. By the time it reaches the character "r," it has
already forgotten about "n," "e" and "u," which makes it almost impossible for this type of neural
network to predict which character would come next.
TYPES OF RNNS
One to One
One to Many
Many to One
Many to Many
We can use recurrent neural networks to solve the problems related to:
Time Series data
Text data
Audio data
Advantages of Recurrent Neural Network (RNN)
RNN captures the sequential information present in the input data i.e. dependency between the words
in the text while making predictions
9.
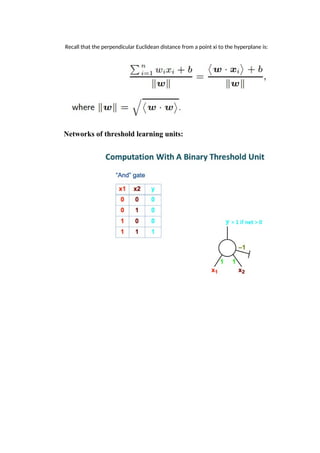
Threshold Logic Unit
TheThreshold Logic Unit (TLU) is a basic form of machine learning model consisting of a
single input unit (and corresponding weights), and an activation function. Note that the TLU is the
most basic form of AI-neuron/computational unit, knowledge of which will lay the foundation for
advanced topics in machine learning and deep learning. The TLU is based on mimicking the
functionality of biological neuron at high-level. A typical neuron receives a multitude of inputs from
afferent neurons, each associated with weight. The weighted-inputs are modulated in the receiving
10.
neuron (the efferent)and the neuron responds accordingly — fires/produces a pulse (1) or no firing/no
pulse (0). This is achieved in the TLU via an activation function which takes the activation a as an
input to generate a prediction y`. A threshold θ is defined and the model produces an output if the
threshold is exceeded, otherwise no output.
In the TLU, each input xᵢ, is associated with a weight wᵢ, in which the sum of the weighted inputs
(products of the input-weight xᵢ × wᵢ) is computed to decide the activation a: a = ∑ x × w
ᴺᵢ₌₁ ᵢ ᵢ
. The
below figure depicts a simple TLU architecture.
A simple network with a set of weighted-inputs, processing unit and an output unit. The linear sum of
the inputs x₁,x and the bias node and their corresponding weights.
₂
While the inputs remain unchanged, the weights are randomly initialised and are adjusted through a
training technique. For the TLU, the training process relies on a pair of examples x,y
ᵢ ᵢ, corresponding to
an arbitrary datapoint xᵢ and its class yᵢ. This form of learning is referred to as a supervised
learning because both the data instance and the target are used to direct the learning process. Other
forms of learning, which I will not belabour here, are unsupervised (utilises the input to infer relevant
clusters or categories) and reinforcement (motivates and rewards the model for a correct prediction,
hence the model is aimed at maximising rewards). A model is said to learn if it can correctly classify a
previously unseen datapoint. The final output or prediction is based on the sum of the weighted
inputs: y` = 1 if a ≥ θ otherwise y` = 0.
Weights adjustment in the TLU
From the perspective of a learning model datapoints belong to groups that are demarcated by a one or
more decision surface(s). Thus, the goal of a learning model is to achieve a certain task such as
11.
classification of objectsafter the training regime. During training, the model identifies a set of
parameters or free parameters (e.g. weights) to be used in conjunction with the input to achieve the
desired goal by identifying the decision surface. It is crucial in any ML-based model to identify the free
parameters that enable the model to identify distinguishing features.
The TLU’s threshold is initialised as a scalar quantity that is used as a baseline or bias, i.e. a baseline to
attain before the neuron fires. For uniformity, the threshold is treated as a weight with a constant input
of -1 such that x×w > θ
ᵢ ᵢ is transformed and integrated into the mainstream of input-weight (x×w +(-
ᵢ ᵢ
1)×θ=0) for training. Consequently, a learning rule is defined and repeatedly applied until the right
setting for the weights vector is obtained. Adjustment to the weights vector is a function of the output
of the given instance. On that basis, the parameters are adjusted — either increased or decreased
according to the learning rule. For each training epoch or regime, a marginal change is made to the
weights. A well-trained model should be able to correctly classify new examples.
Some technical descriptions
With the augmented threshold, the action of the TLU is either positive or negative given by: w⋅x ≥ 0 →
y = 1 or w⋅x < 0 → y = 0. Because the input vector x is not affected during the training process
(remains unchanged), only the weight vector w is adjusted to align properly with the input vector.
Using a learning rate α (0<α<1) to control the process, a new vector w` is formed which is closer to the
input vector x. According to the decision rule, adjusting the weight can be based on addition or
subtracting the weight vector; since both are likely, a learning rule that combines both is used instead.
Thus, w` = w + αx or w` = w — αx results in w` = w + α(t-y')x, where t-y is used to decide the
adjustment direction (increase or decrease). Alternatively, the relationship can be expressed in several
ways:
1. In terms of change in the weight vector: δw = w`- w but w` = w + α(t-y)x , and δw = α(t-y)x
2. Or in terms of components of the weights vector: δw =
ᵢ α(tᵢ-yᵢ)xᵢ where i = 1 to n+1
12.
TLU Implementation
Having establishedthe theoretical base, the next step is to describe and implement the training phase of
the model. Basically, the implementation is based on the following steps:
1. Identify inputs and the corresponding representation
2. Identify the free parameters in the problem
3. Specify the learning rule
4. Adjust the free parameters for optimisation
5. Evaluate the model
Linear learning machines
• In supervised learning, the learning machine is given a training set of examples (inputs)
with associated labels (output values). S = ¡ (x1, y1), (x2, y2), . . . , (x`, y`) ¢ ⊆ (X × Y ) `
(` denotes number of training samples, xi are examples or instances, and yi their labels). • A
training set S is said to be trivial if all labels are equal. • Usually the input space is a subset
of the real value space, X ⊆ R n (n is the dimension of the input space). The input x = (x1,
x2, . . . , xn) 0 is a vector length n ( 0 denotes matrix transposition). • Linear functions are
probably the best understood and simplest hypothesis. • A learning machine using a
hypothesis that forms linear combinations of the input variables is known as a linear
learning machine
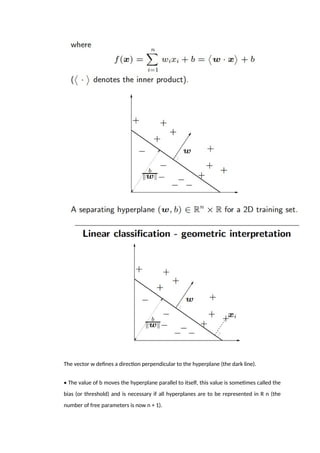
Linear classification A linear function f(x) is frequently used for binary classification, y ∈
{−1, +1}, as follows: assign x = (x1, x2, . . . , xn) to +ve class if f(x) ≥ 0, otherwise assign
to the −ve class,
13.
The vector wdefines a direction perpendicular to the hyperplane (the dark line).
• The value of b moves the hyperplane parallel to itself, this value is sometimes called the
bias (or threshold) and is necessary if all hyperplanes are to be represented in R n (the
number of free parameters is now n + 1).
14.
Recall that theperpendicular Euclidean distance from a point xi to the hyperplane is:
Networks of threshold learning units:
15.
Training of feedforward networks by back propagations
A feedforward neural network is an artificial neural network where the nodes
never form a cycle. This kind of neural network has an input layer, hidden layers,
and an output layer. It is the first and simplest type of artificial neural network.
16.
Back propagation (BP)is a feed forward neural network and it propagates the error in
backward direction to update the weights of hidden layers. The error is difference of
actual output and target output computed on the basis of gradient descent method.
Forward Propagation is the way to move from the Input layer (left) to the Output layer
(right) in the neural network. The process of moving from the right to left i.e backward
from the Output to the Input layer is called the Backward Propagation.
Backpropagation is the essence of neural network training. It is the method of fine-tuning the
weights of a neural network based on the error rate obtained in the previous epoch (i.e., iteration).
Proper tuning of the weights allows you to reduce error rates and make the model reliable by
increasing its generalization.
Backpropagation in neural network is a short form for “backward propagation of errors.” It is a
standard method of training artificial neural networks. This method helps calculate the gradient of a
loss function with respect to all the weights in the network.
History of Backpropagation
In 1961, the basics concept of continuous backpropagation were derived in the context of
control theory by J. Kelly, Henry Arthur, and E. Bryson.
In 1969, Bryson and Ho gave a multi-stage dynamic system optimization method.
In 1974, Werbos stated the possibility of applying this principle in an artificial neural
network.
In 1982, Hopfield brought his idea of a neural network.
In 1986, by the effort of David E. Rumelhart, Geoffrey E. Hinton, Ronald J. Williams,
backpropagation gained recognition.
In 1993, Wan was the first person to win an international pattern recognition contest with the
help of the backpropagation method.
Backpropagation isfast, simple and easy to program
It has no parameters to tune apart from the numbers of input
It is a flexible method as it does not require prior knowledge about the network
It is a standard method that generally works well
It does not need any special mention of the features of the function to be learned.
Types of Backpropagation Networks
Two Types of Backpropagation Networks are:
Static Back-propagation
Recurrent Backpropagation
Static back-propagation:
It is one kind of backpropagation network which produces a mapping of a static input for static
output. It is useful to solve static classification issues like optical character recognition.
Recurrent Backpropagation:
Recurrent Back propagation in data mining is fed forward until a fixed value is achieved. After that,
the error is computed and propagated backward.
The main difference between both of these methods is: that the mapping is rapid in static back-
propagation while it is nonstatic in recurrent backpropagation.
Disadvantages of using Backpropagation
The actual performance of backpropagation on a specific problem is dependent on the input
data.
Back propagation algorithm in data mining can be quite sensitive to noisy data
You need to use the matrix-based approach for backpropagation instead of mini-batch.
Knowledge Based System
The typical architecture of a knowledge-based system, which informs its problem-solving
method, includes a knowledge base and an inference engine. The knowledge base contains a
collection of information in a given field -- medical diagnosis, for example. The inference
engine deduces insights from the information housed in the knowledge base. Knowledge-
based systems also include an interface through which users query the system and interact
with it.
A knowledge-based system may vary with respect to its problem-solving method or approach.
Some systems encode expert knowledge as rules and are therefore referred to as rule-based
19.
systems. Another approach,case-based reasoning, substitutes cases for rules. Cases are
essentially solutions to existing problems that a case-based system will attempt to apply to a
new problem.
Knowledge-based systems represent a rules-based or case-based approach to AI
Where knowledge-based systems are used
Over the years, knowledge-based systems have been developed for a number of applications.
MYCIN, for example, was an early knowledge-based system created to help doctors diagnose
diseases. Healthcare has remained an important market for knowledge-based systems, which
are now referred to as clinical decision-support systems in the health sciences context.
Knowledge-based systems have also been employed in applications as diverse as avalanche
path analysis, industrial equipment fault diagnosis and cash management.
Knowledge-based systems and artificial intelligence
While a subset of artificial intelligence, classical knowledge-based systems differ in approach
to some of the newer developments in AI.
Daniel Dennett, a philosopher and cognitive scientist, in his 2017 book, From Bacteria to
Bach and Back, cited a strategy shift from early AI, characterized by "top-down-organized,
bureaucratically efficient know-it-all" systems to systems that harness Big Data and
"statistical pattern-finding techniques" such as data-mining and deep learning in a more
bottom-up approach.
Examples of AI following the latter approach include neural network systems, a type of deep-
learning technology that concentrates on signal processing and pattern recognition problems
such as facial recognition.