Downloaded 54 times




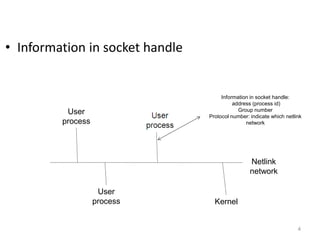



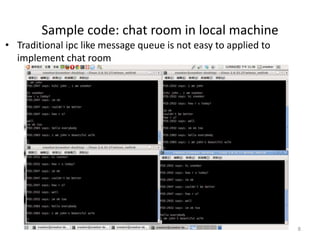


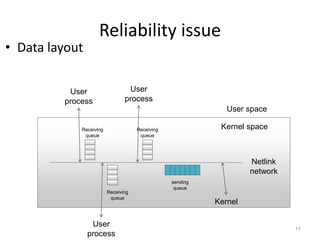
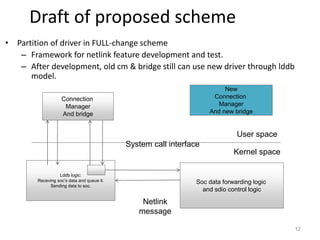


The document discusses the Netlink API for inter-process communication between kernel space and user space in Linux. It provides an overview of Netlink, sample code for creating sockets and sending/receiving messages, and analyzes reliability issues with asynchronous message transmission. Specifically: - Netlink allows communication between kernel and user processes by eliminating round trips between spaces but reliability can be an issue with asynchronous messaging. - Sample code demonstrates creating Netlink sockets, binding addresses, packing messages and sending/receiving between kernel and user callback functions. - Reliability is analyzed for various message transmissions, and solutions like acknowledging delivered messages are proposed to ensure successful inter-process communication via Netlink.














![[251] implementing deep learning using cu dnn](https://cdn.slidesharecdn.com/ss_thumbnails/215implementingdeeplearningusingcudnn-150915052020-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)


























































