Download as PDF, PPTX






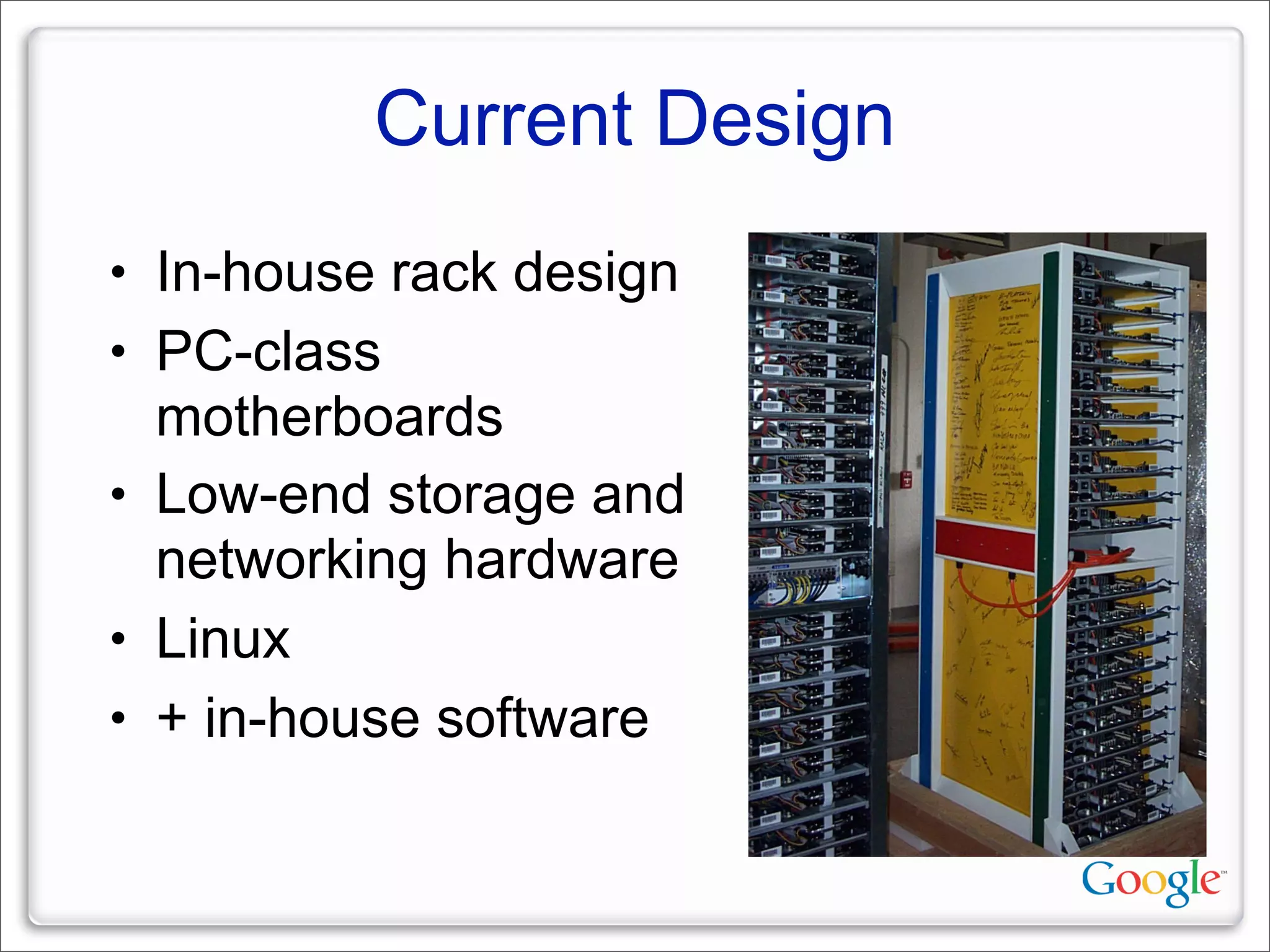

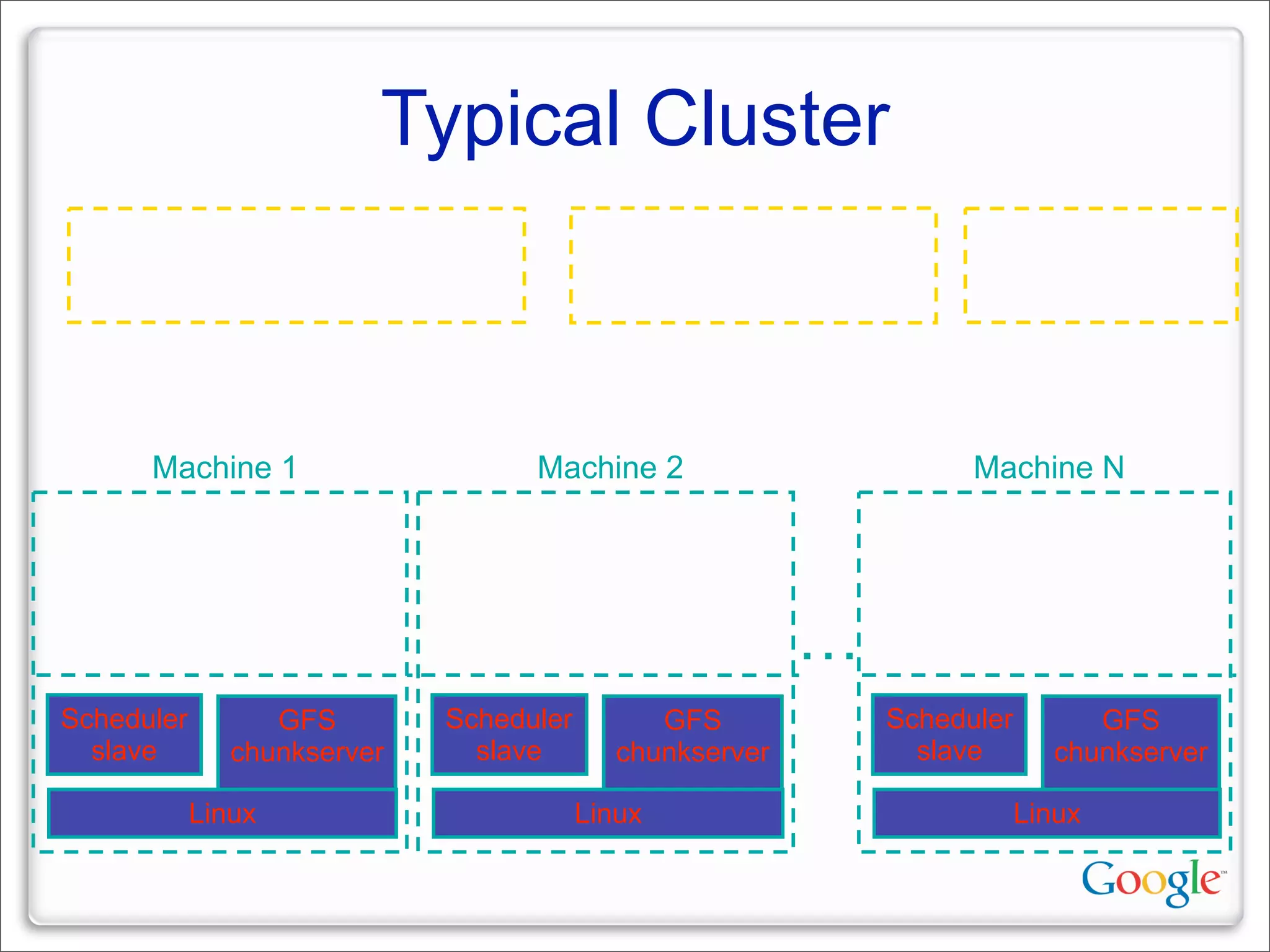




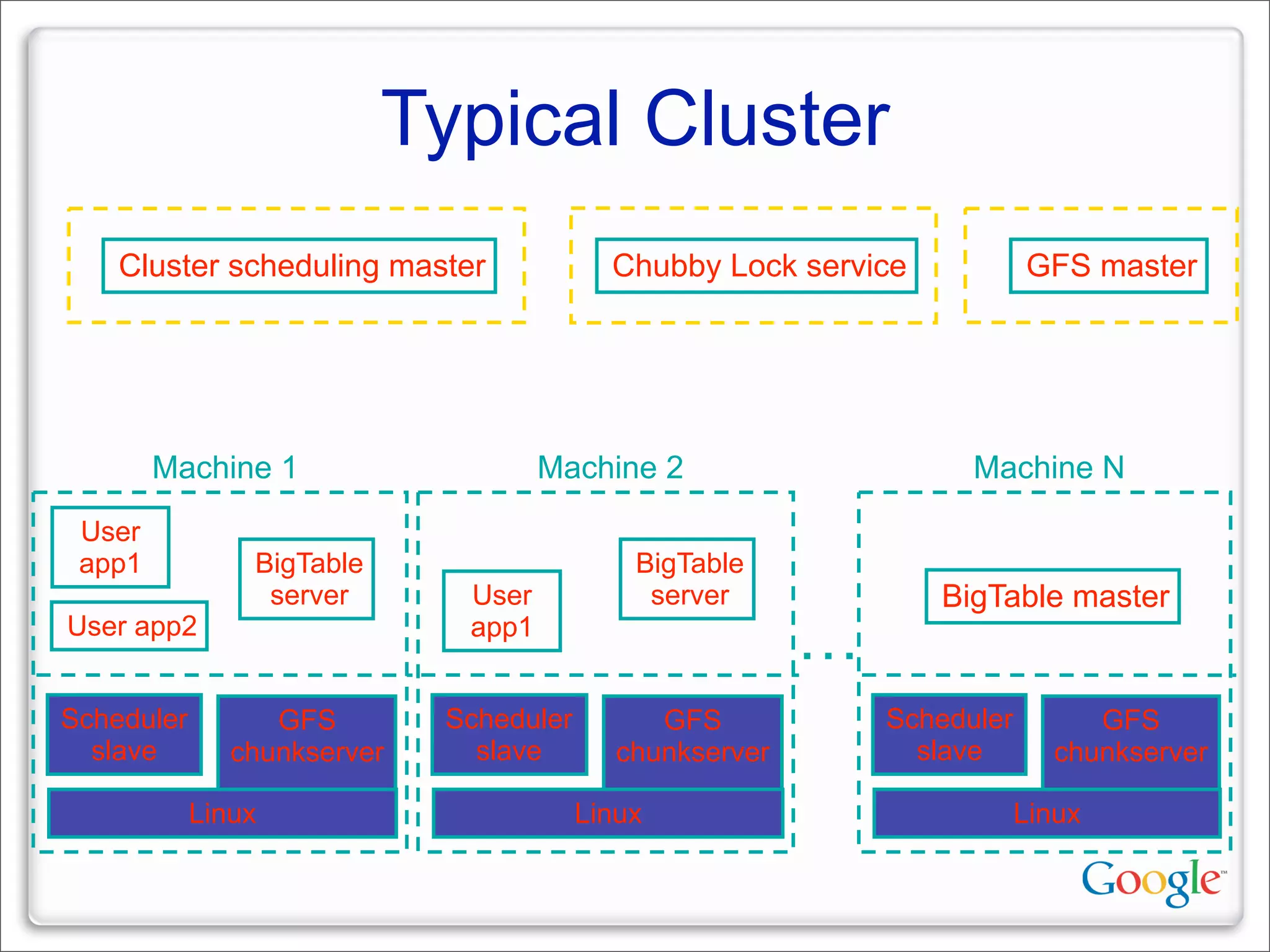






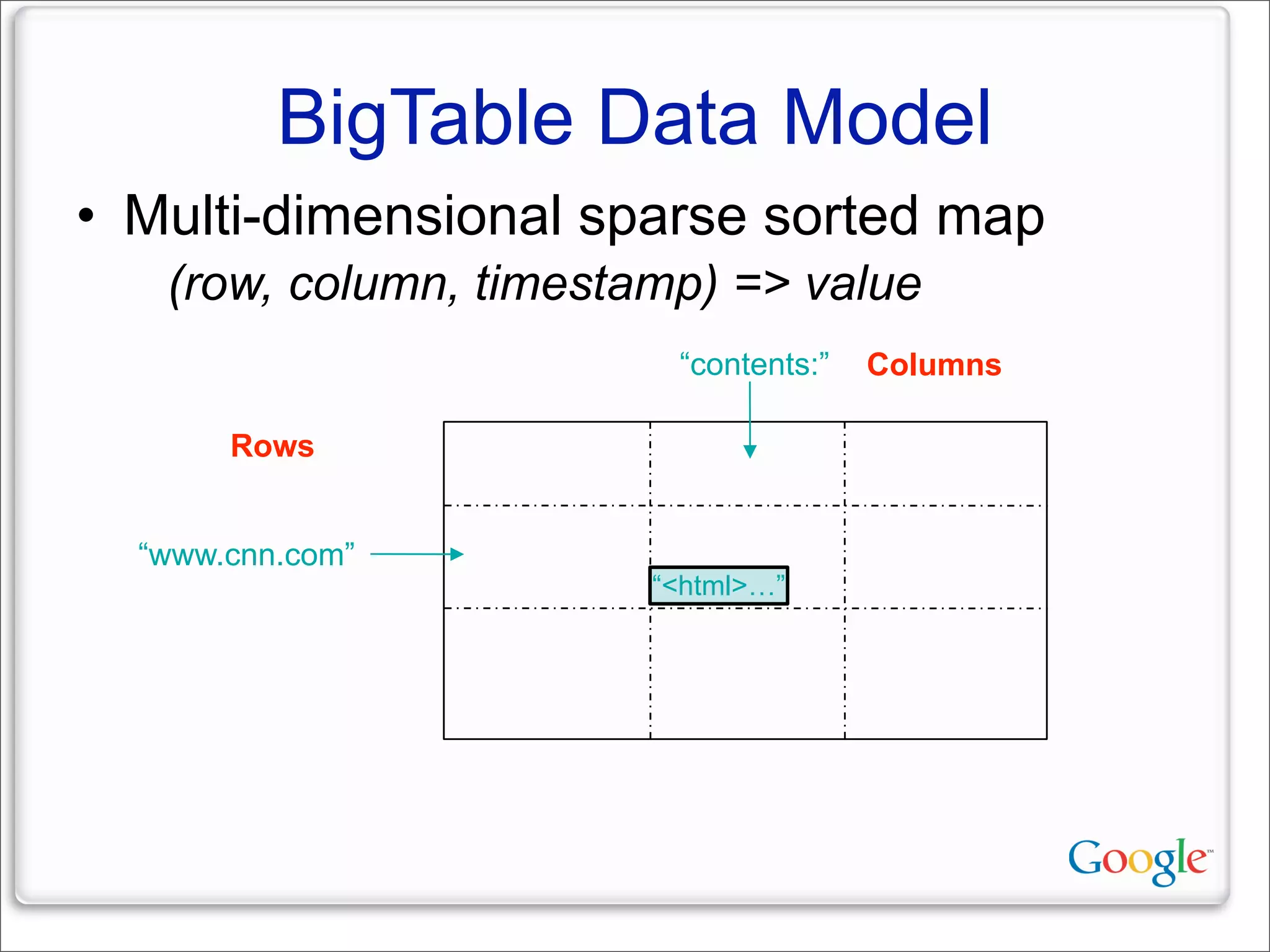

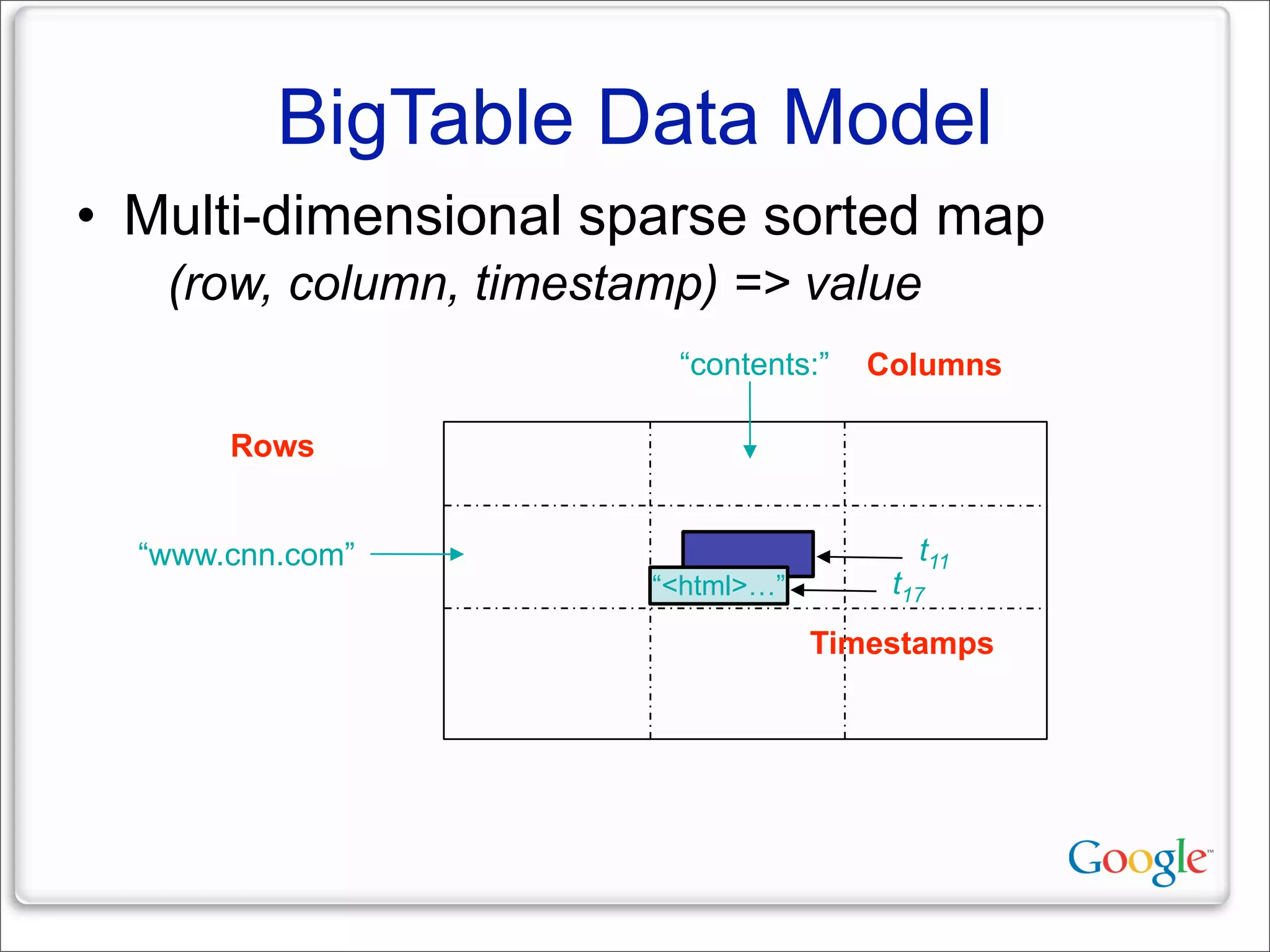

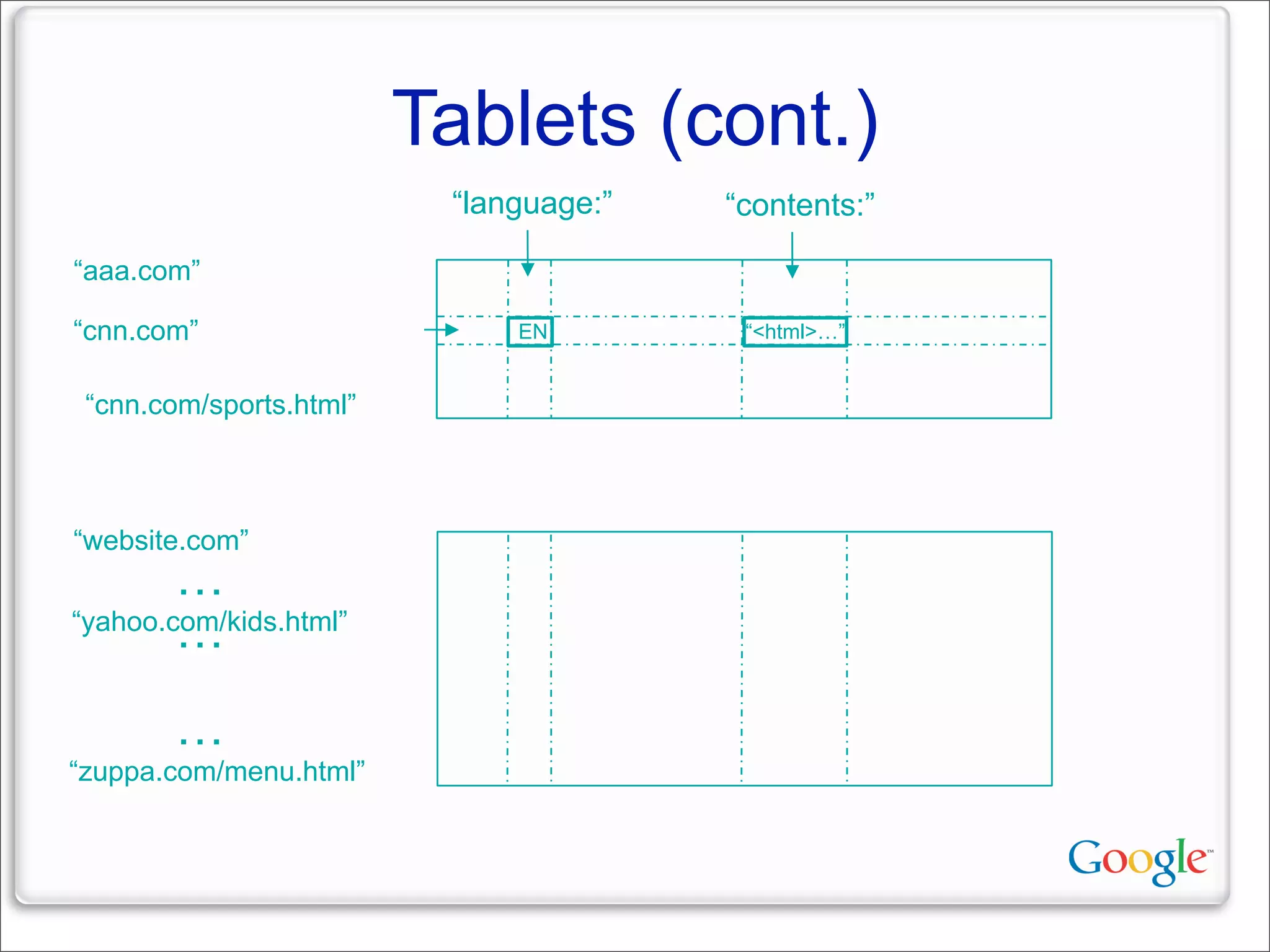
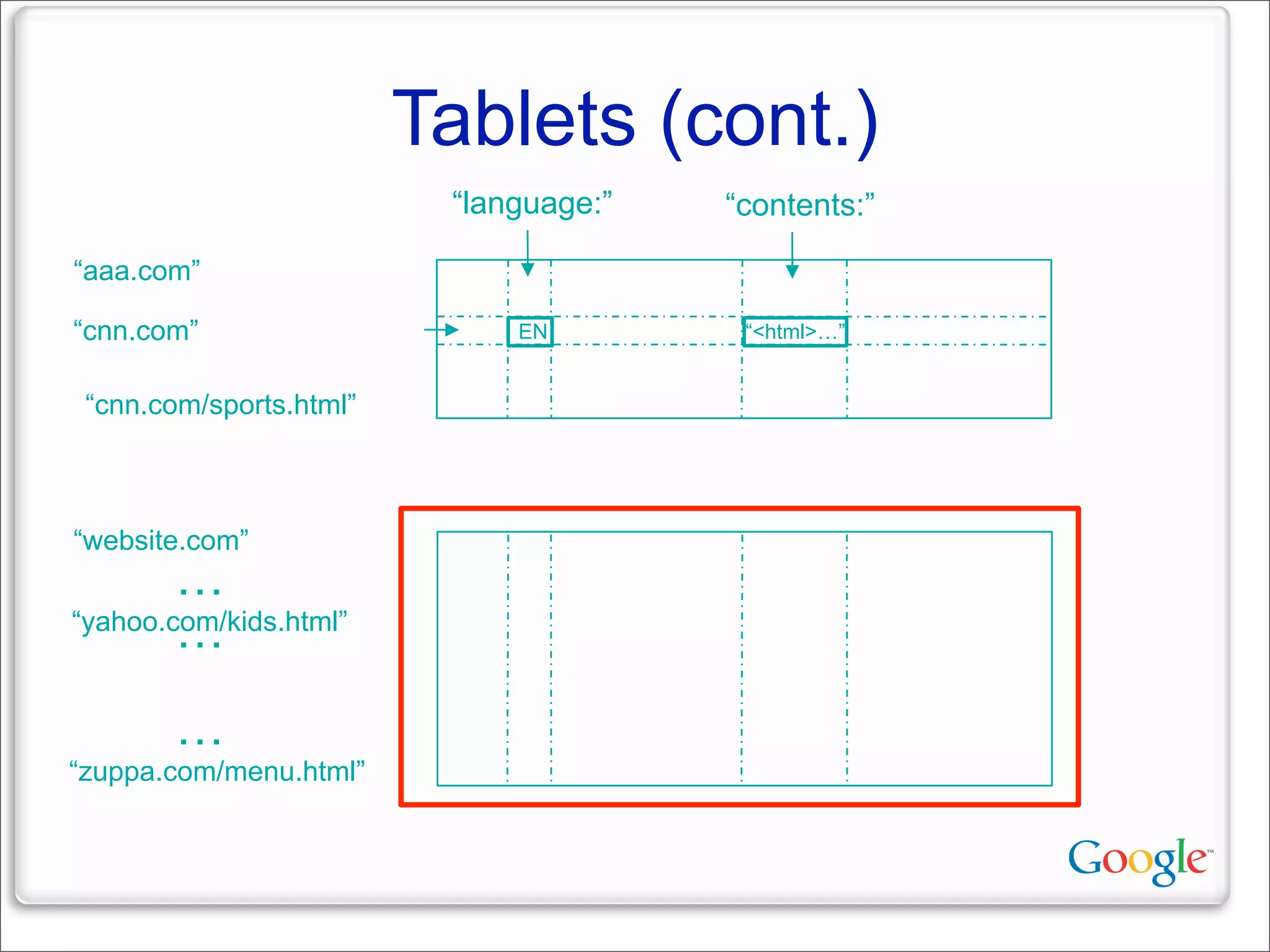

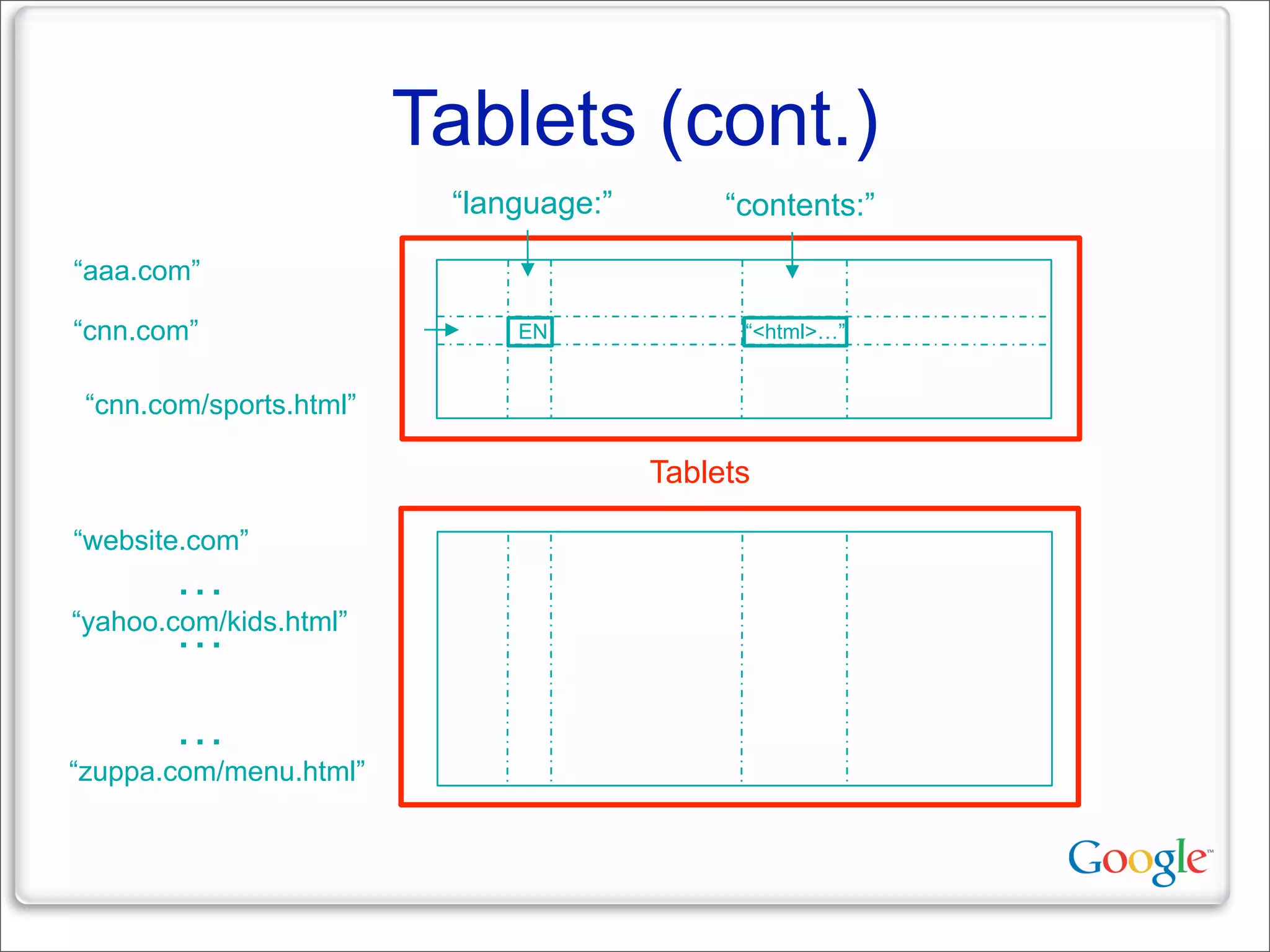
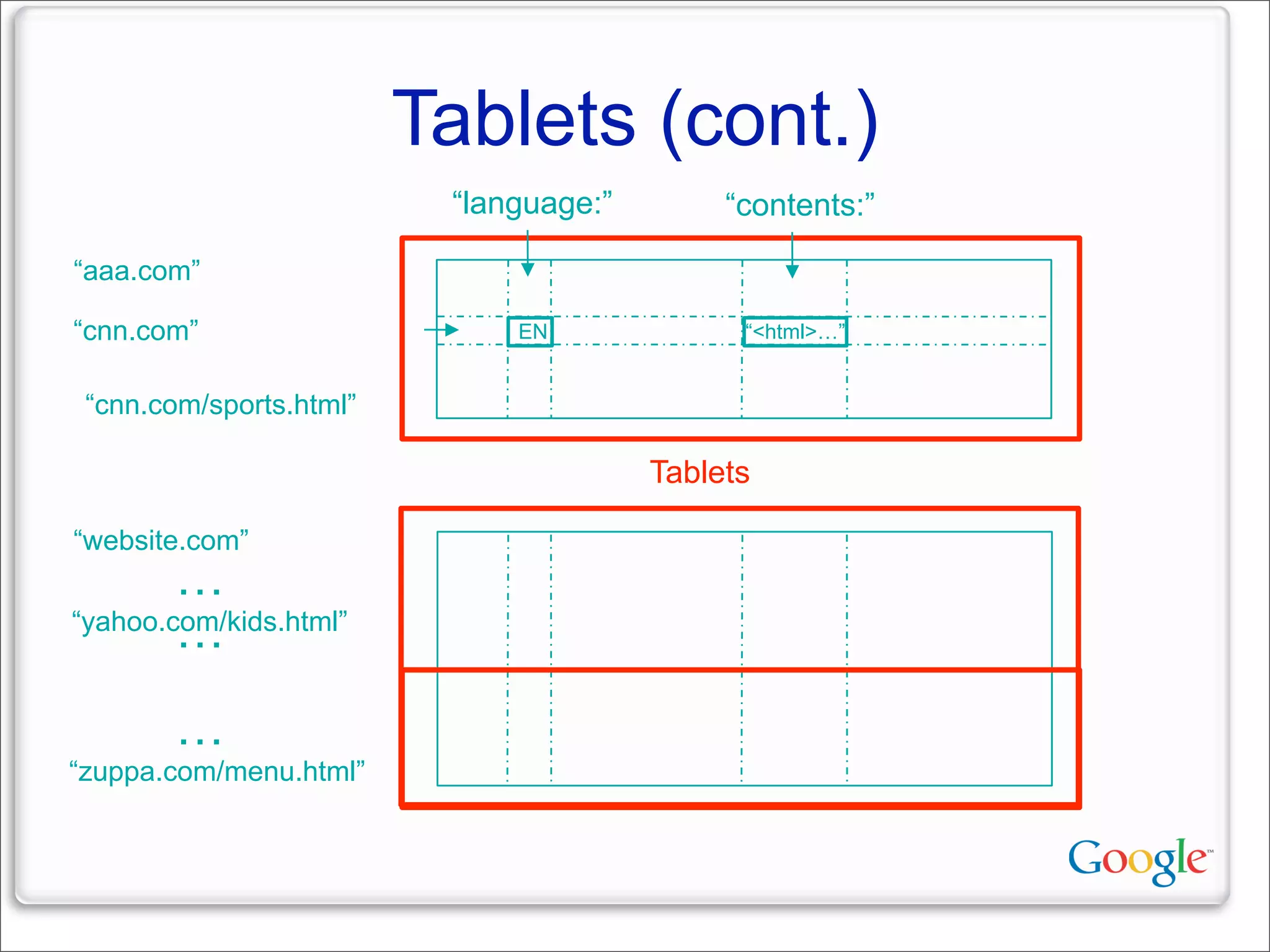
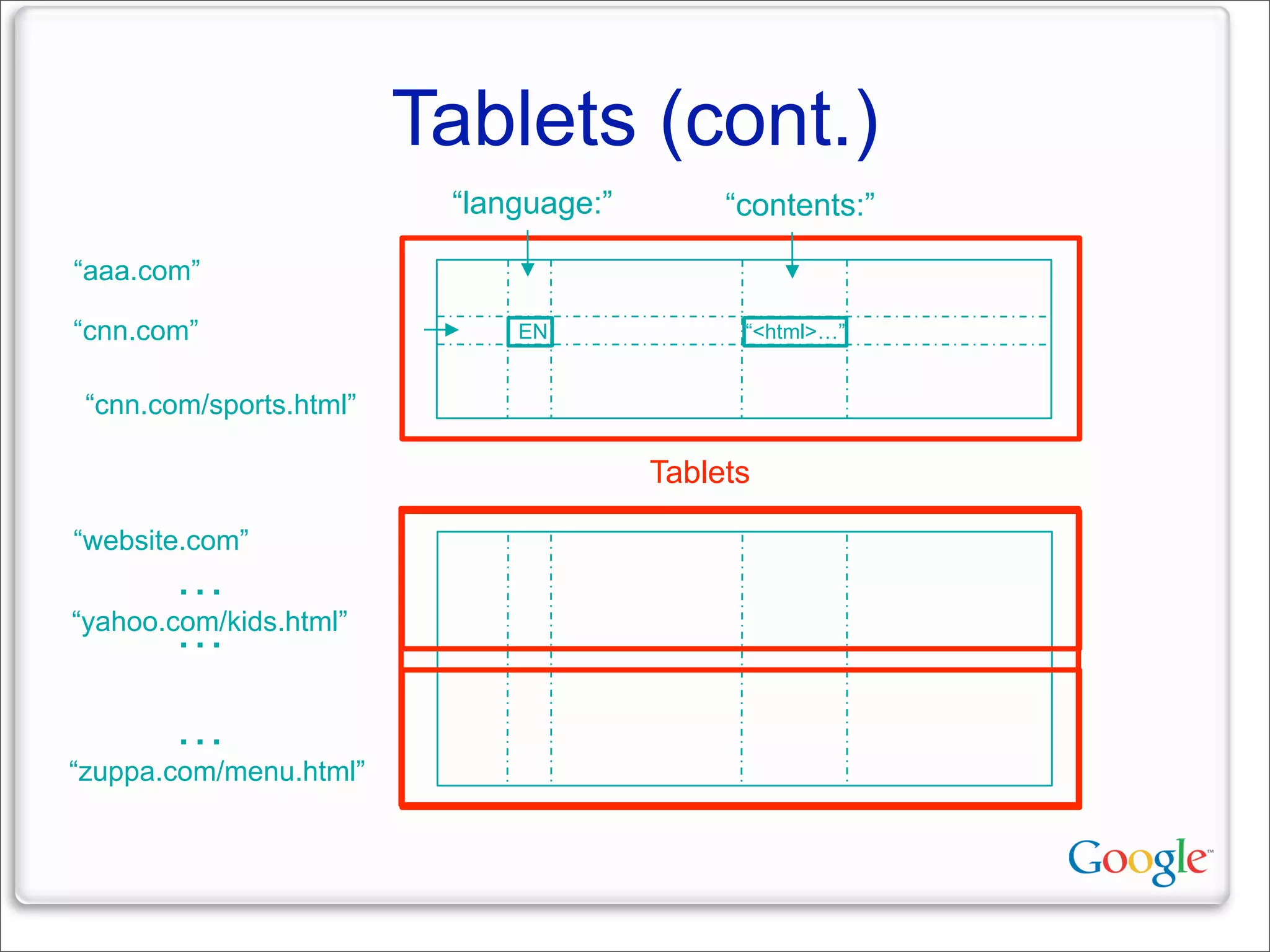
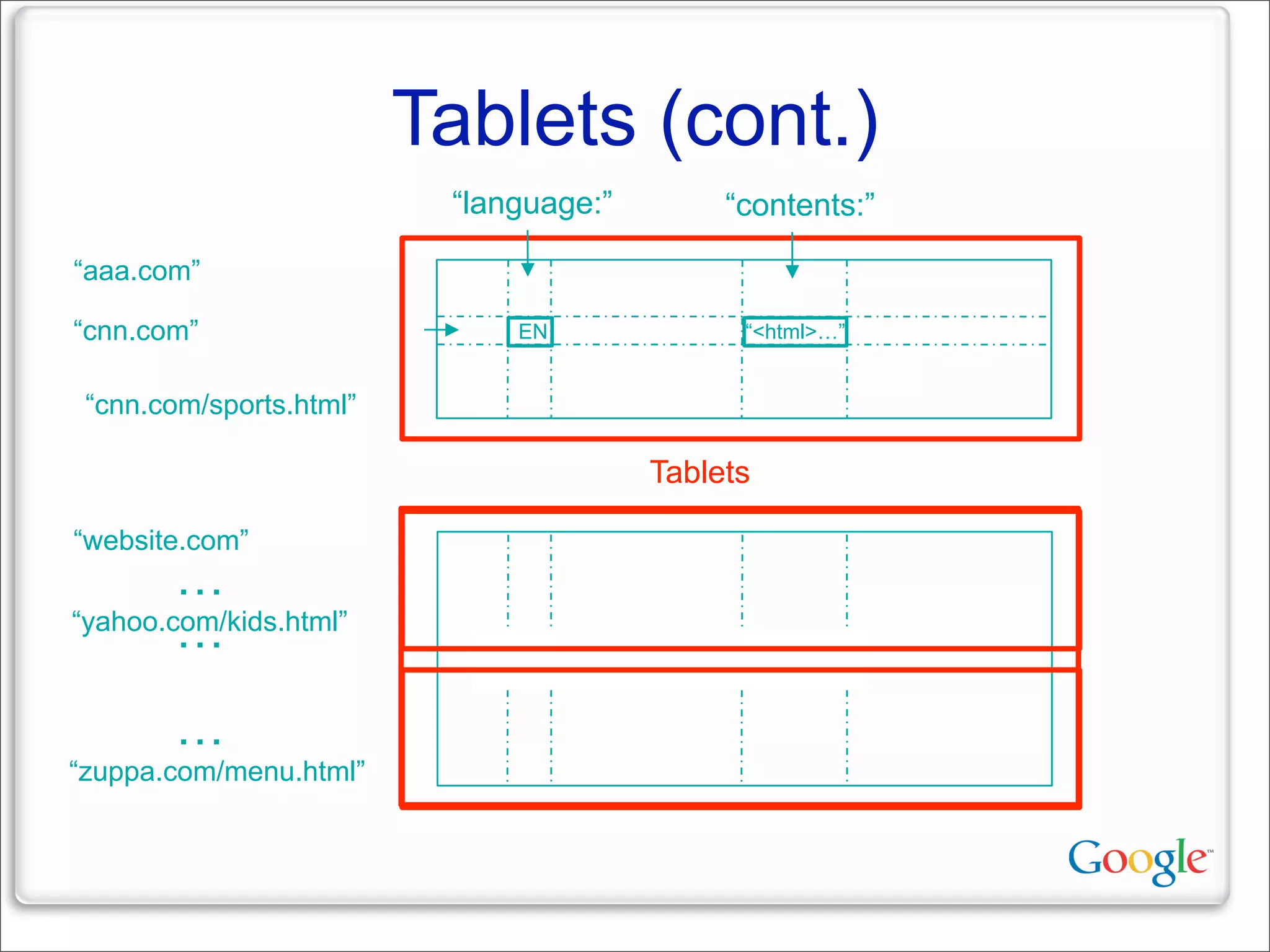

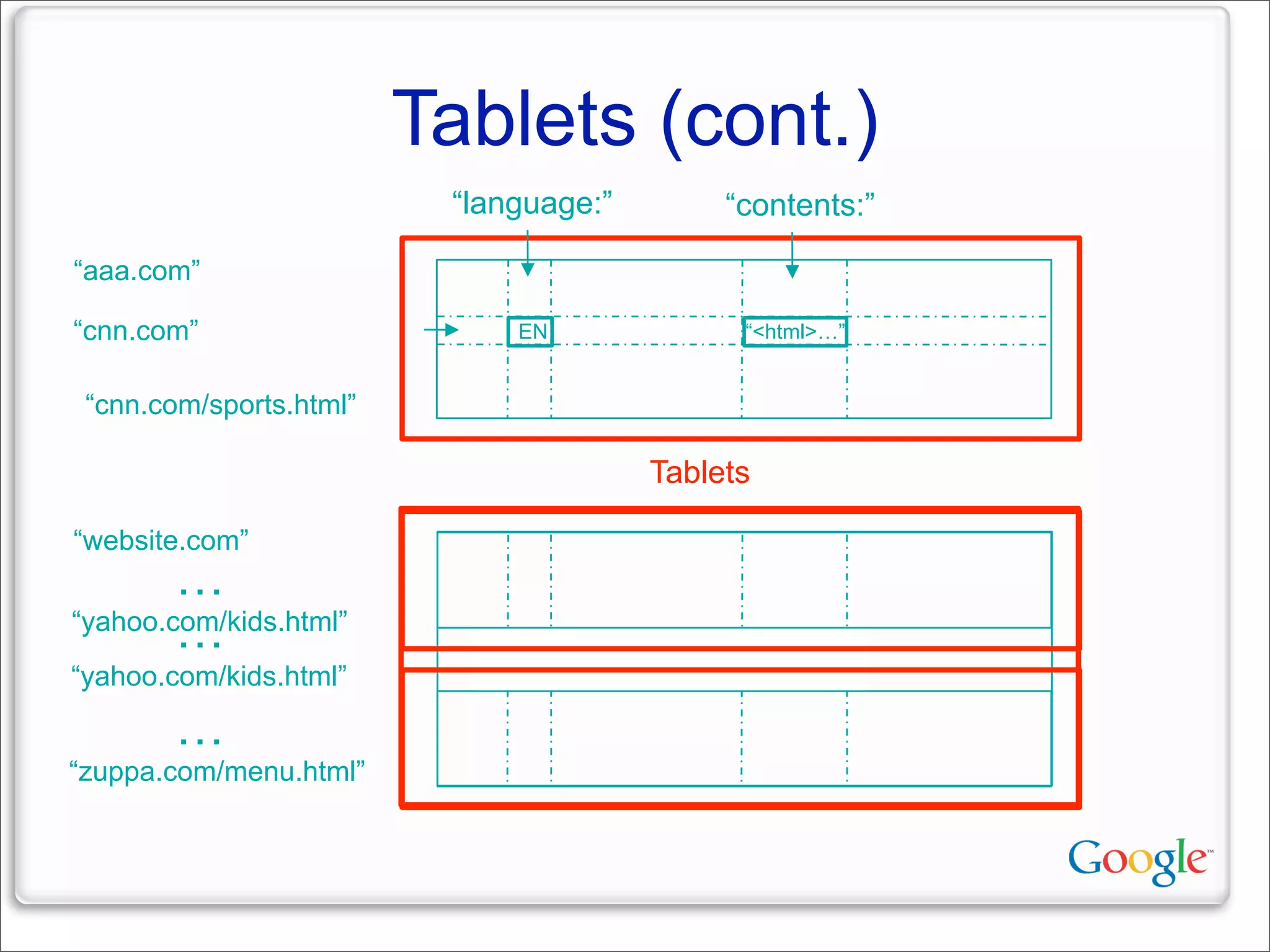
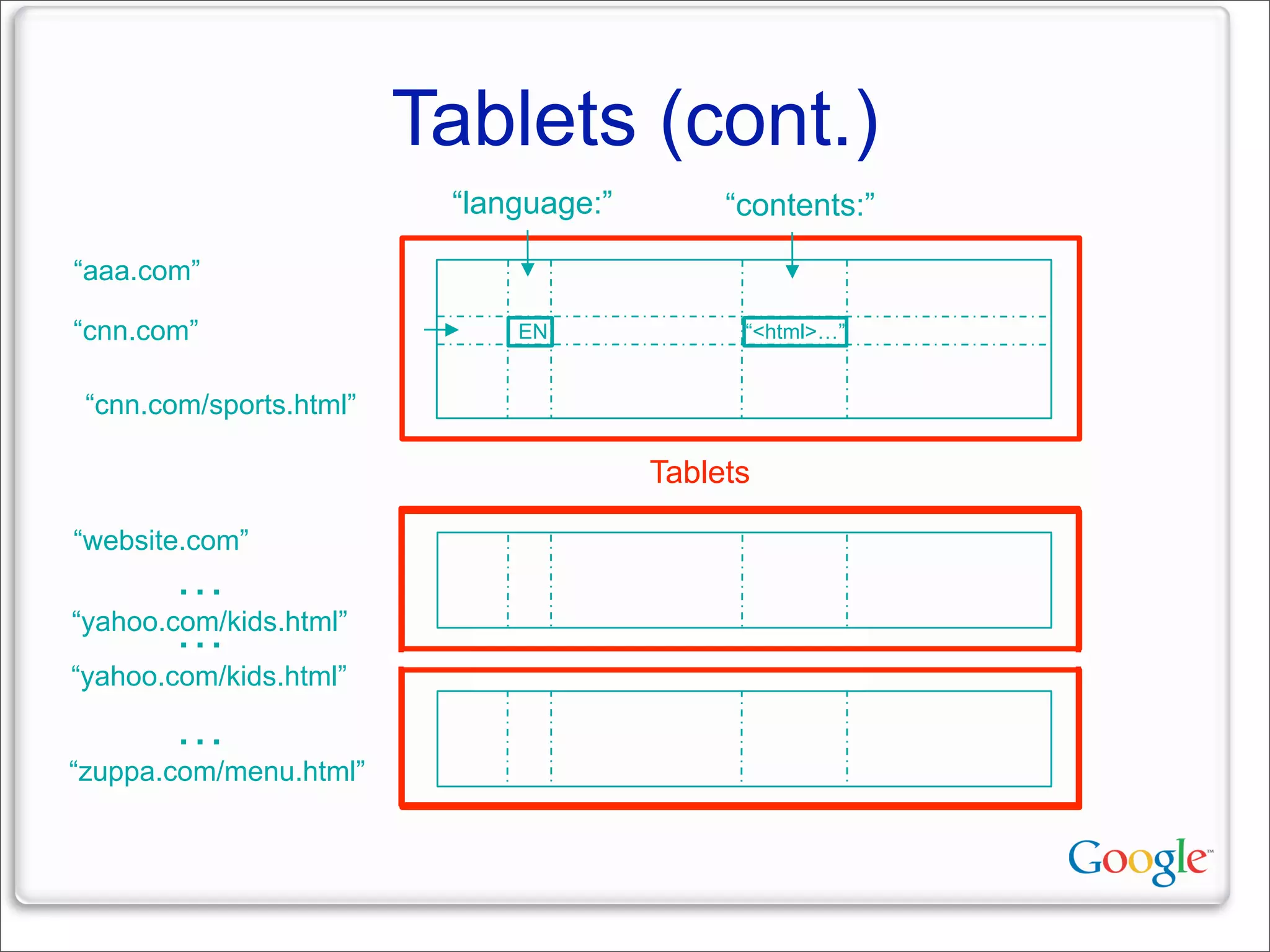

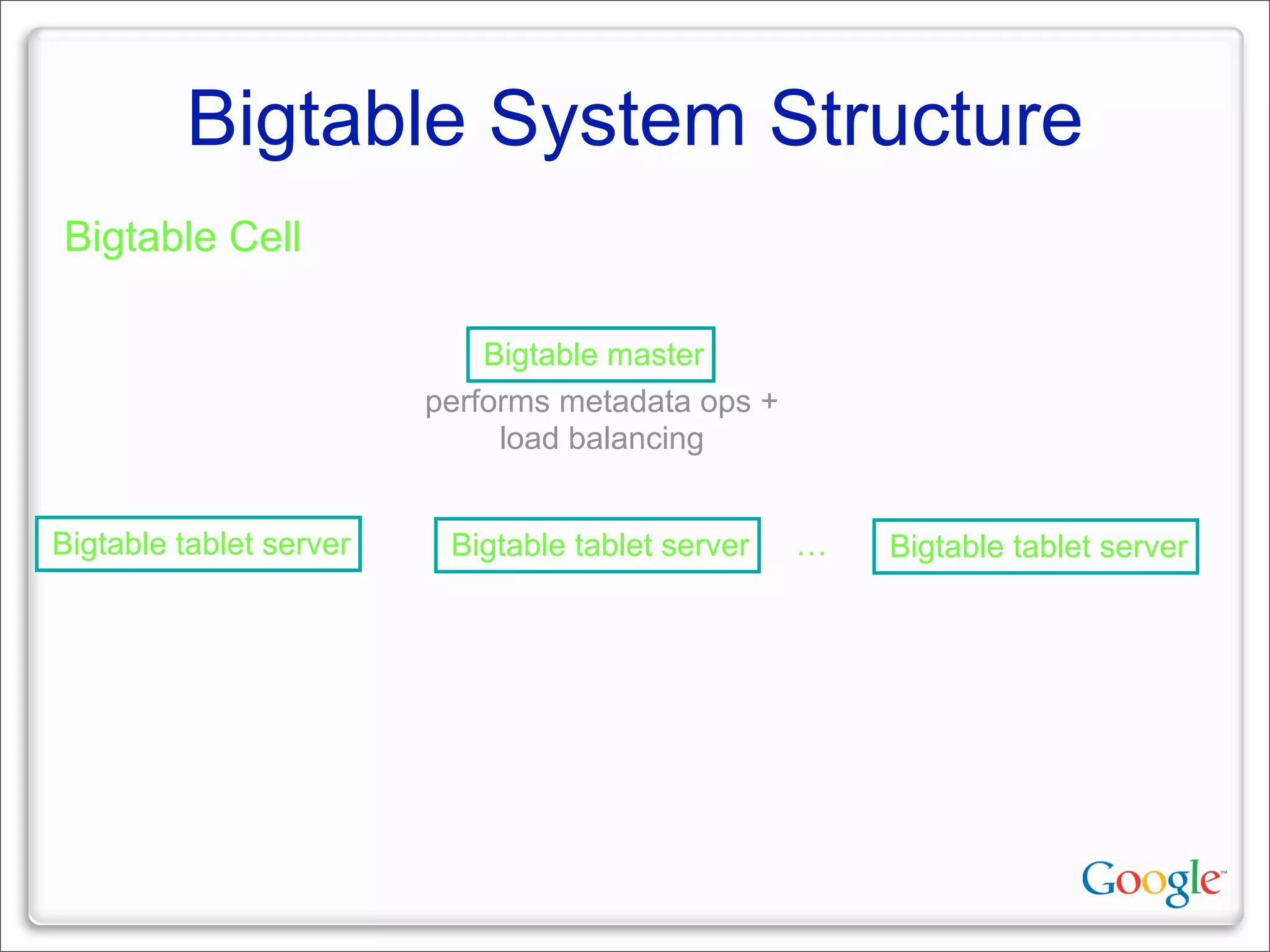
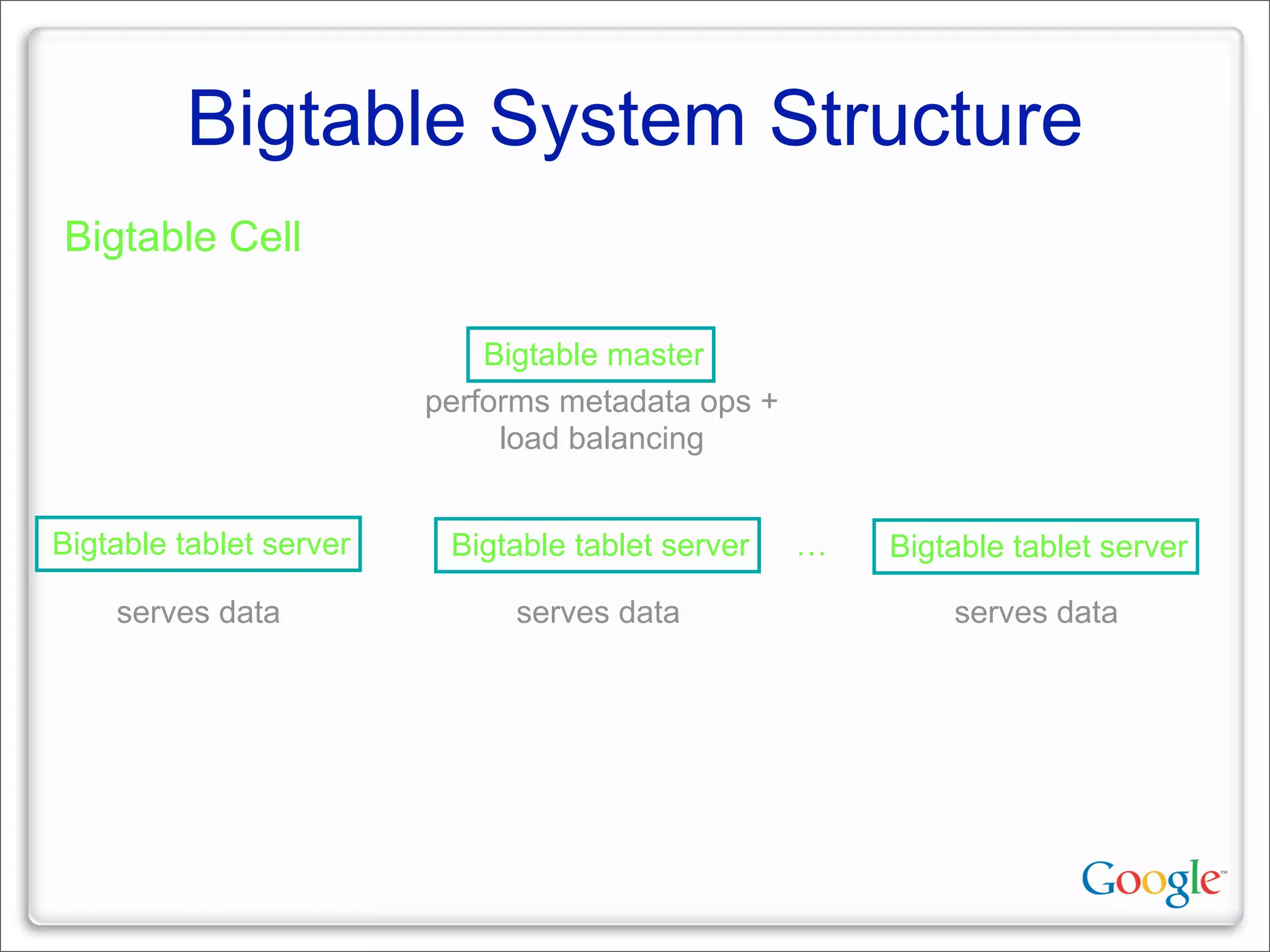
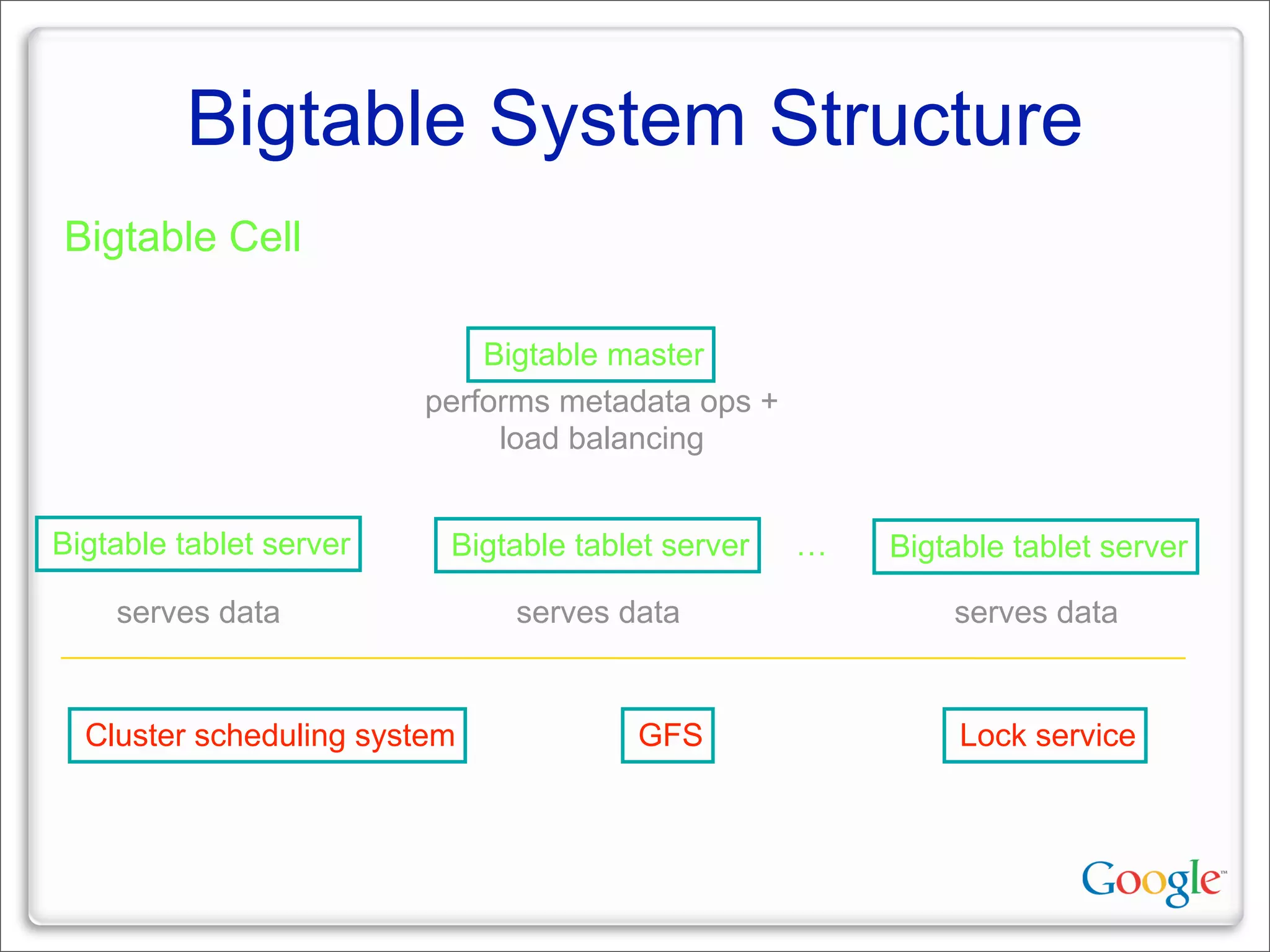
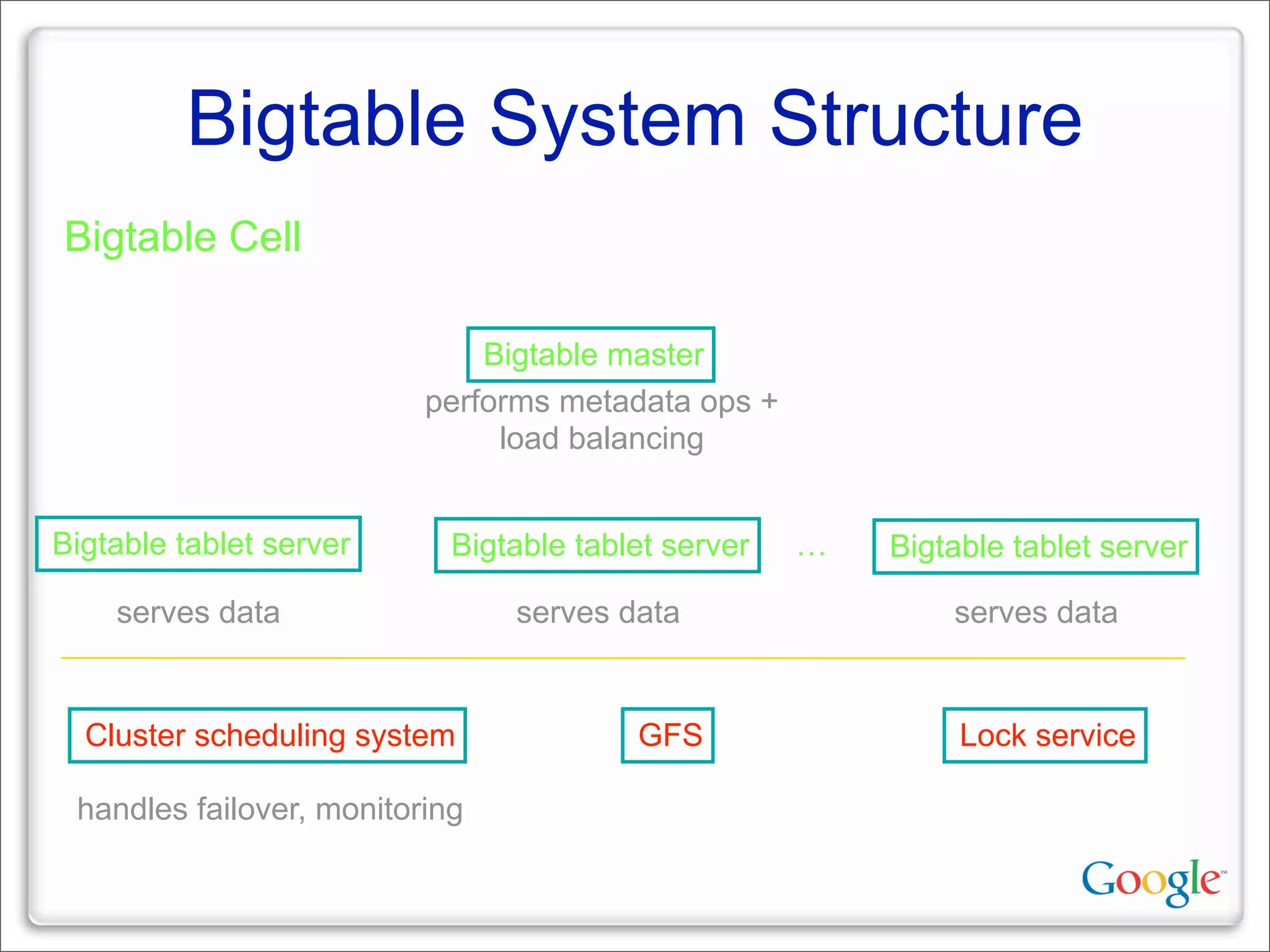
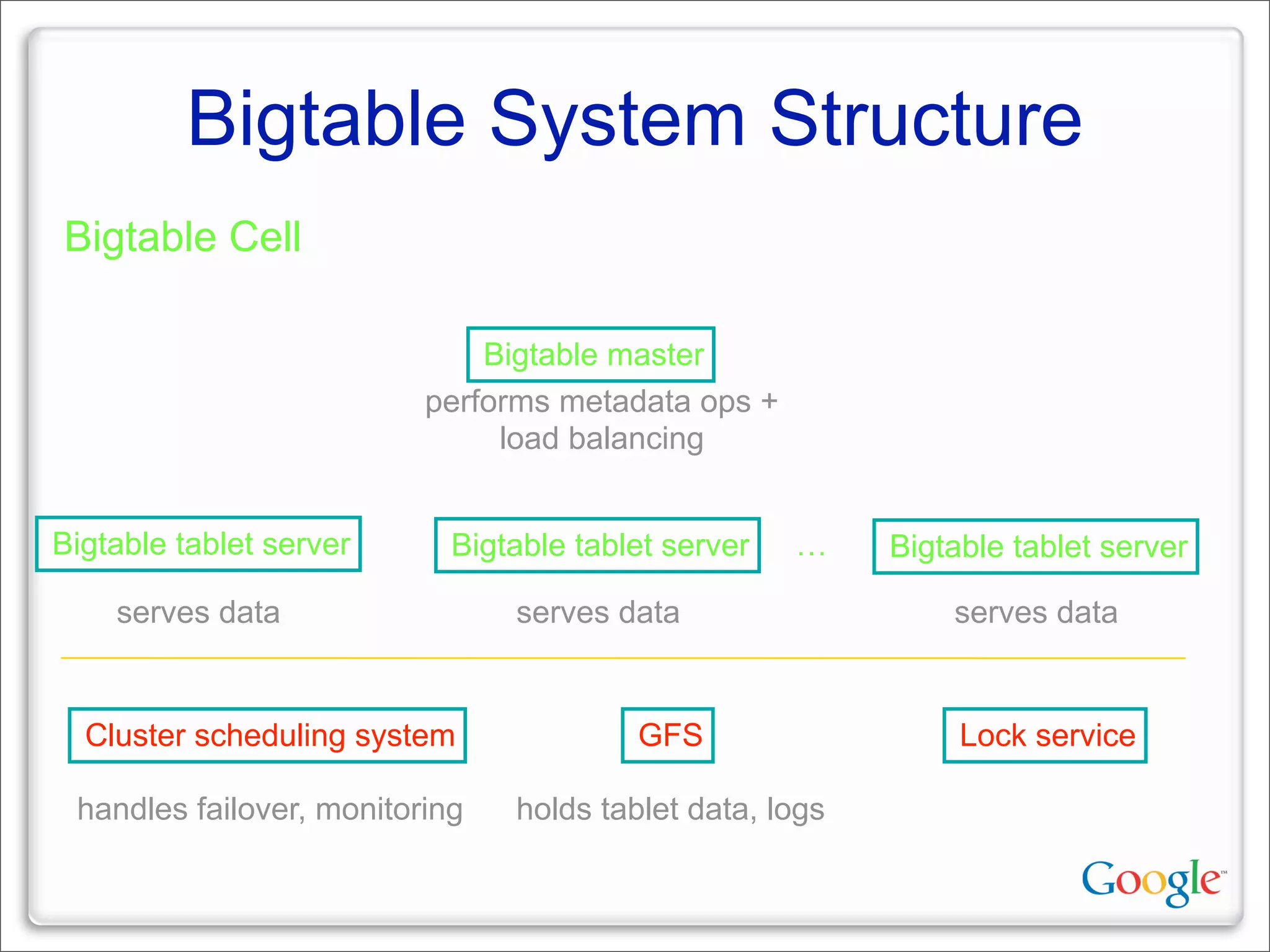

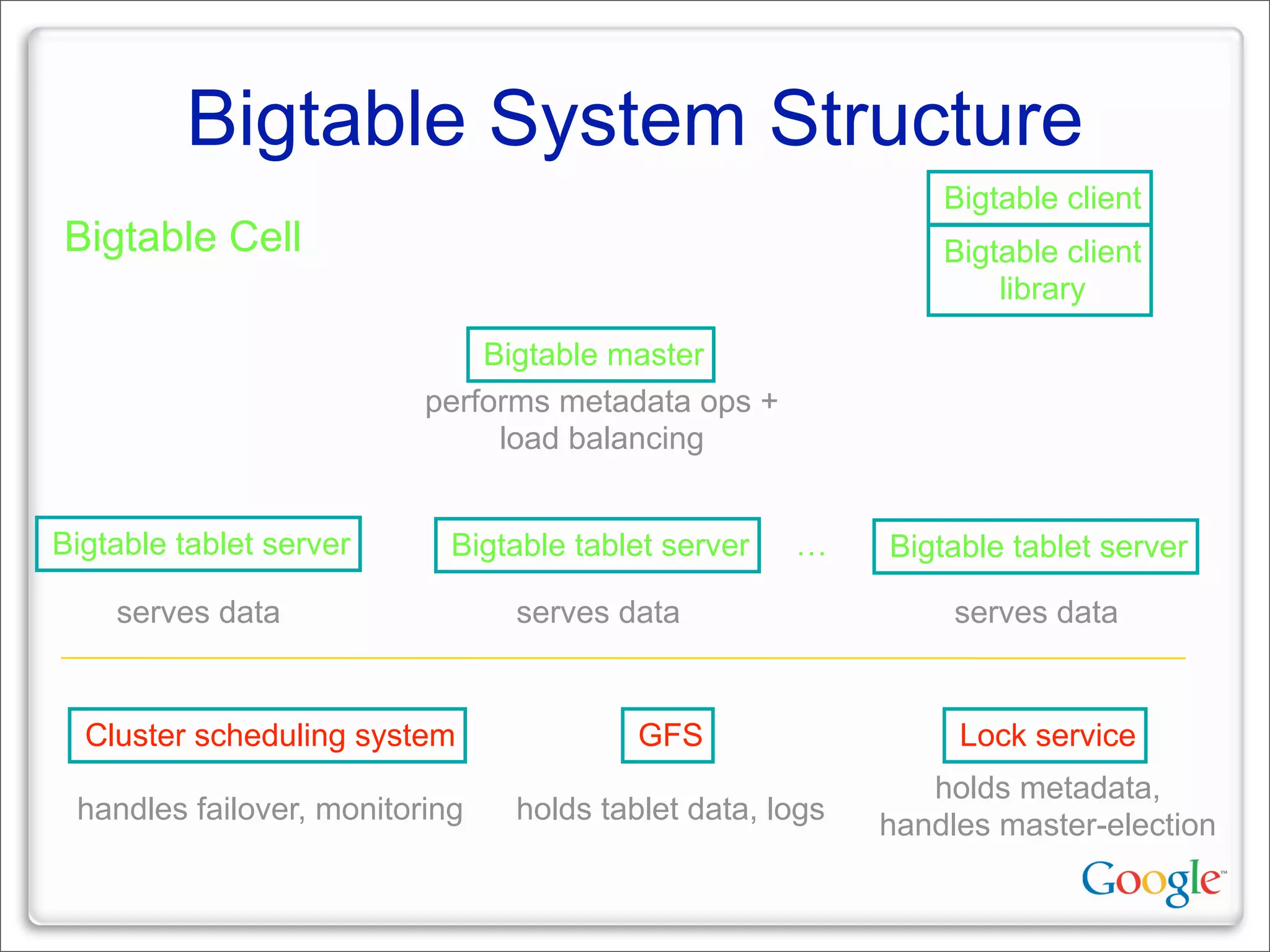
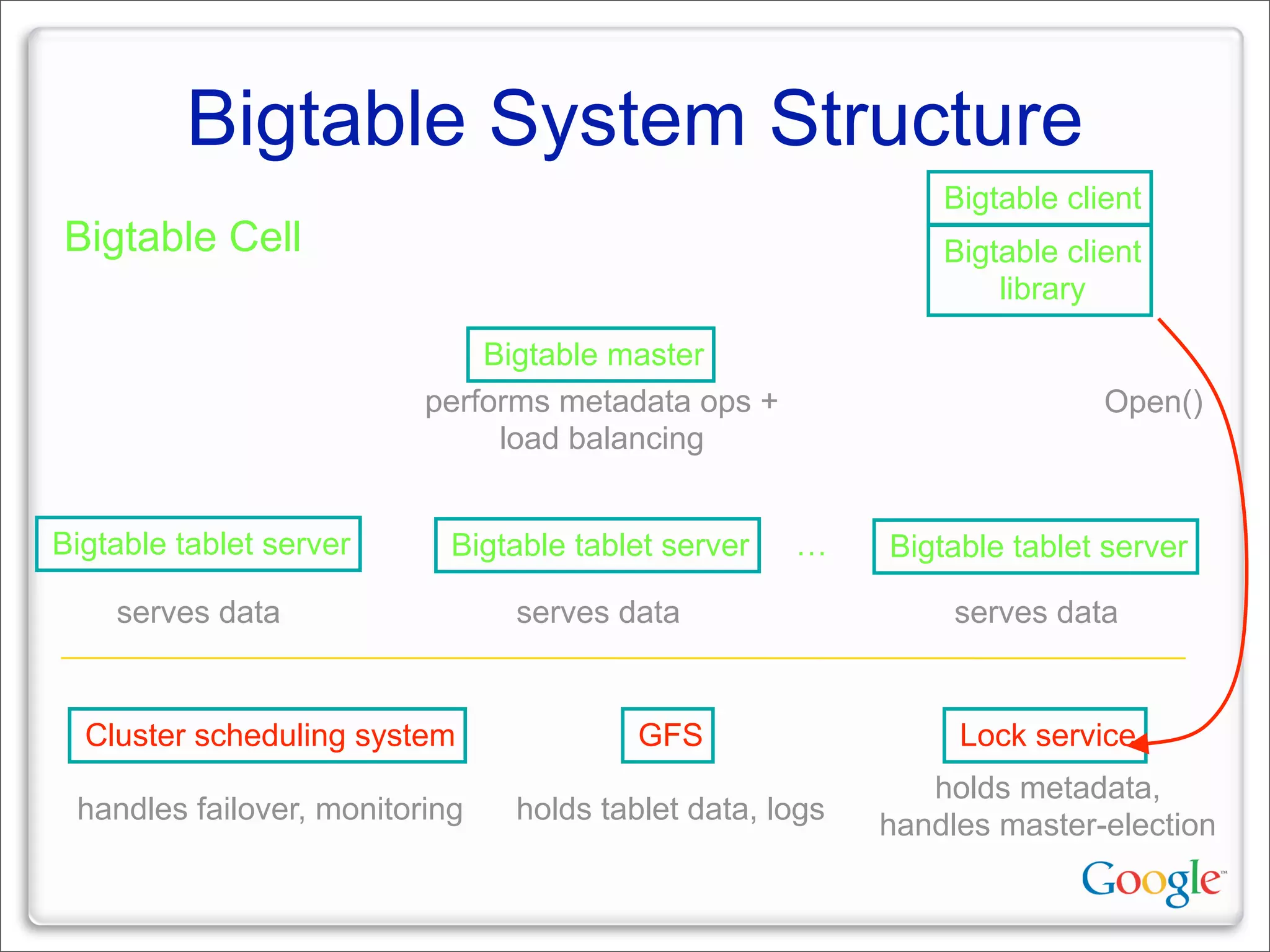
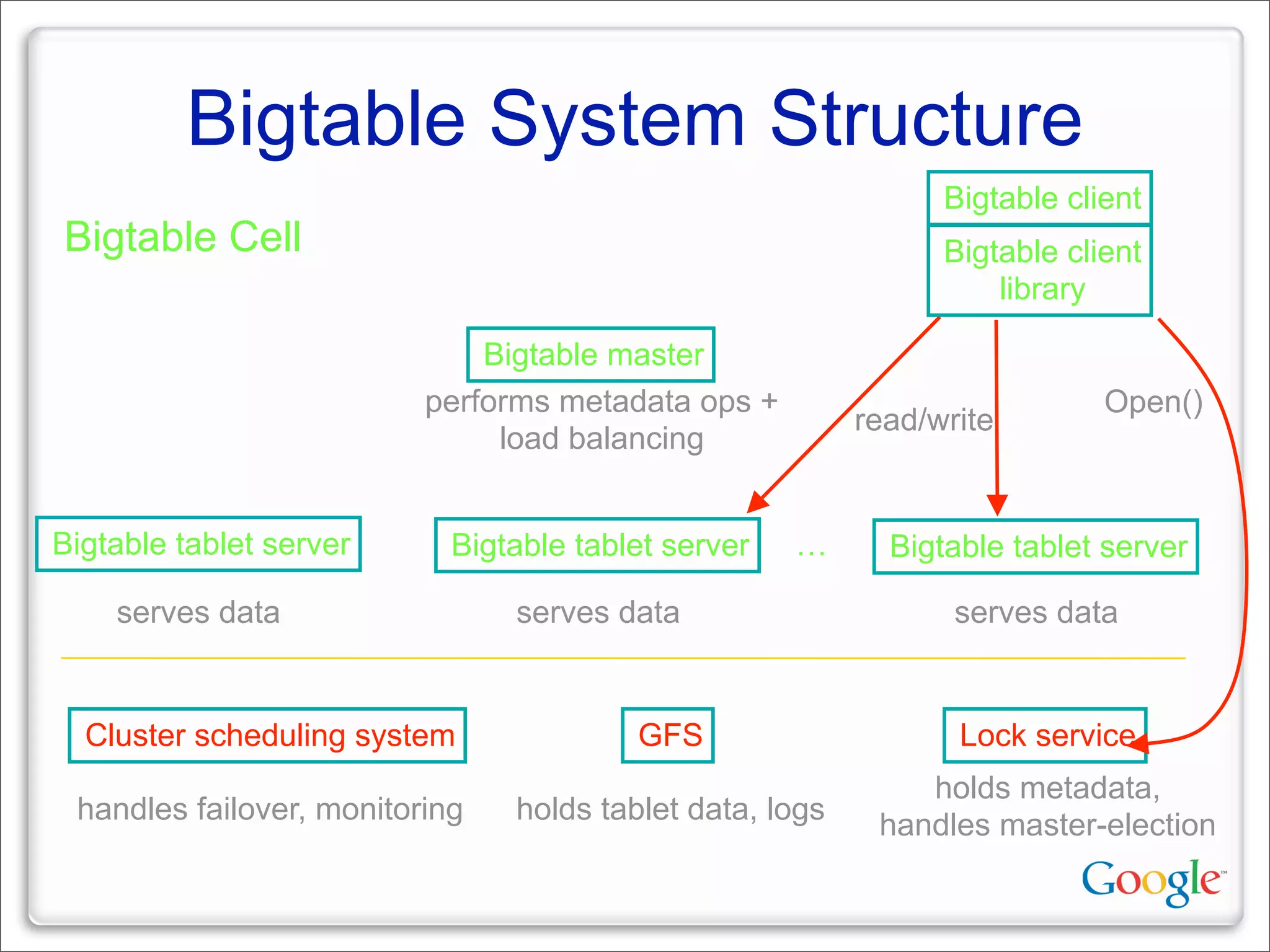
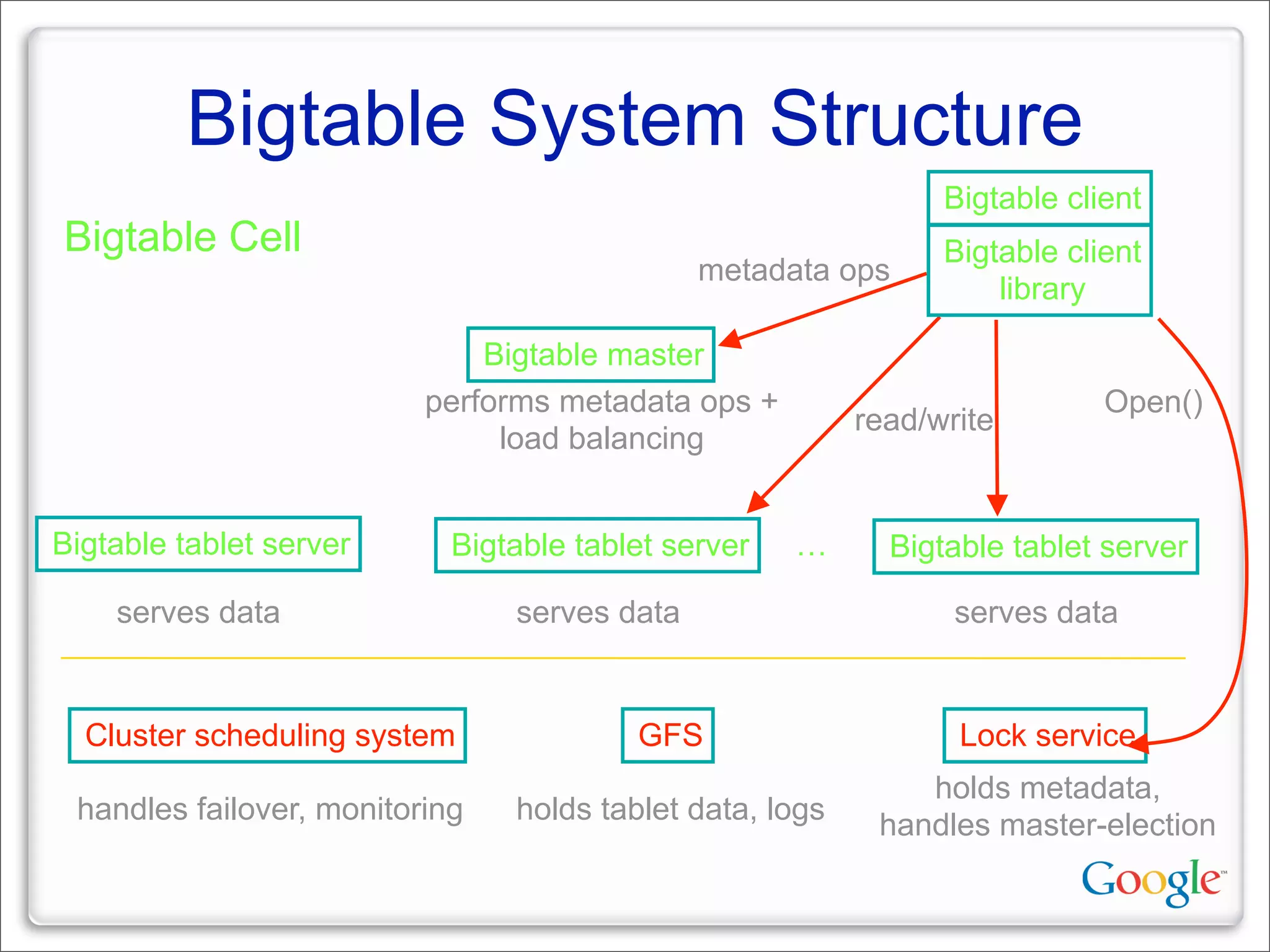




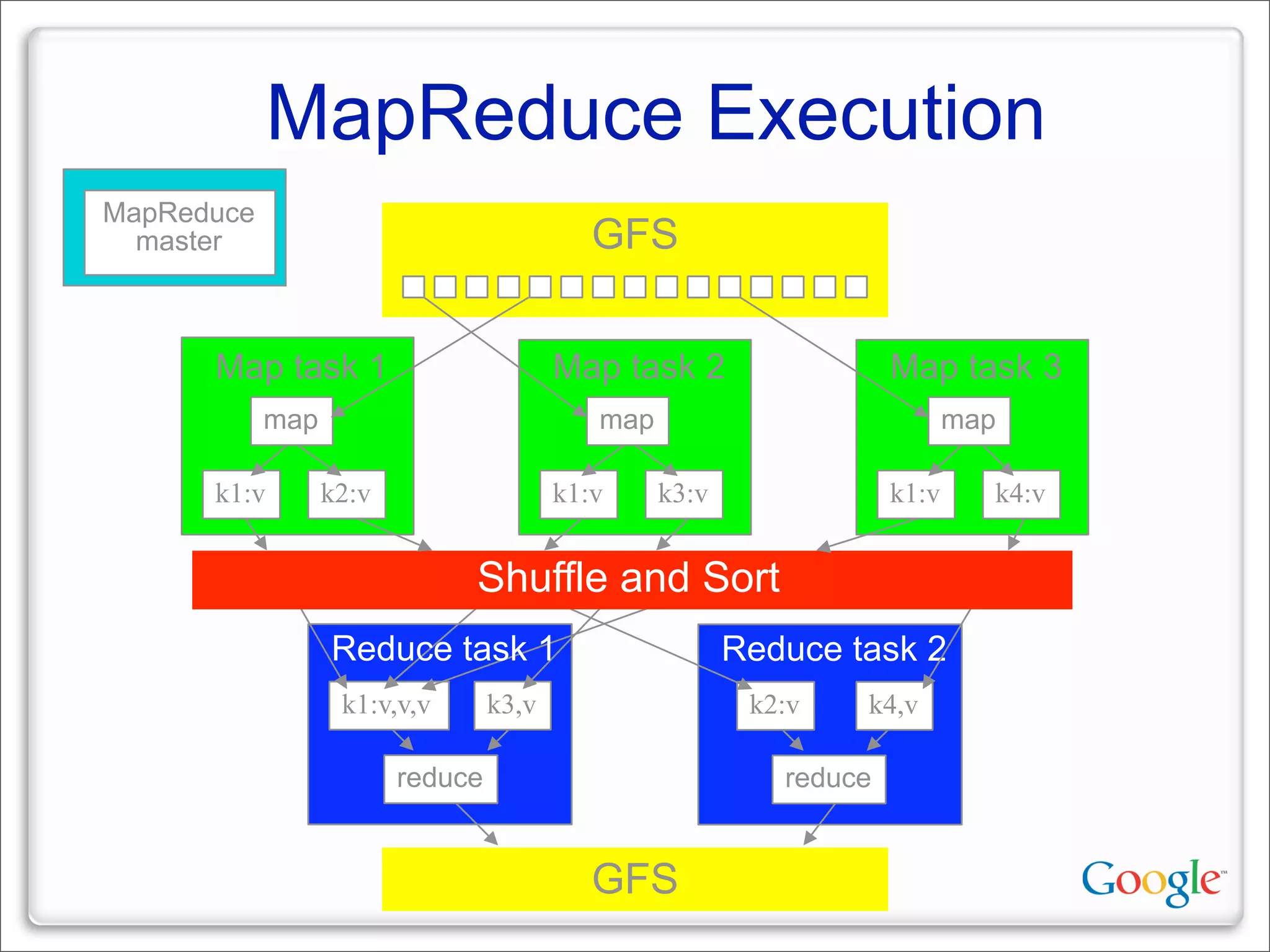



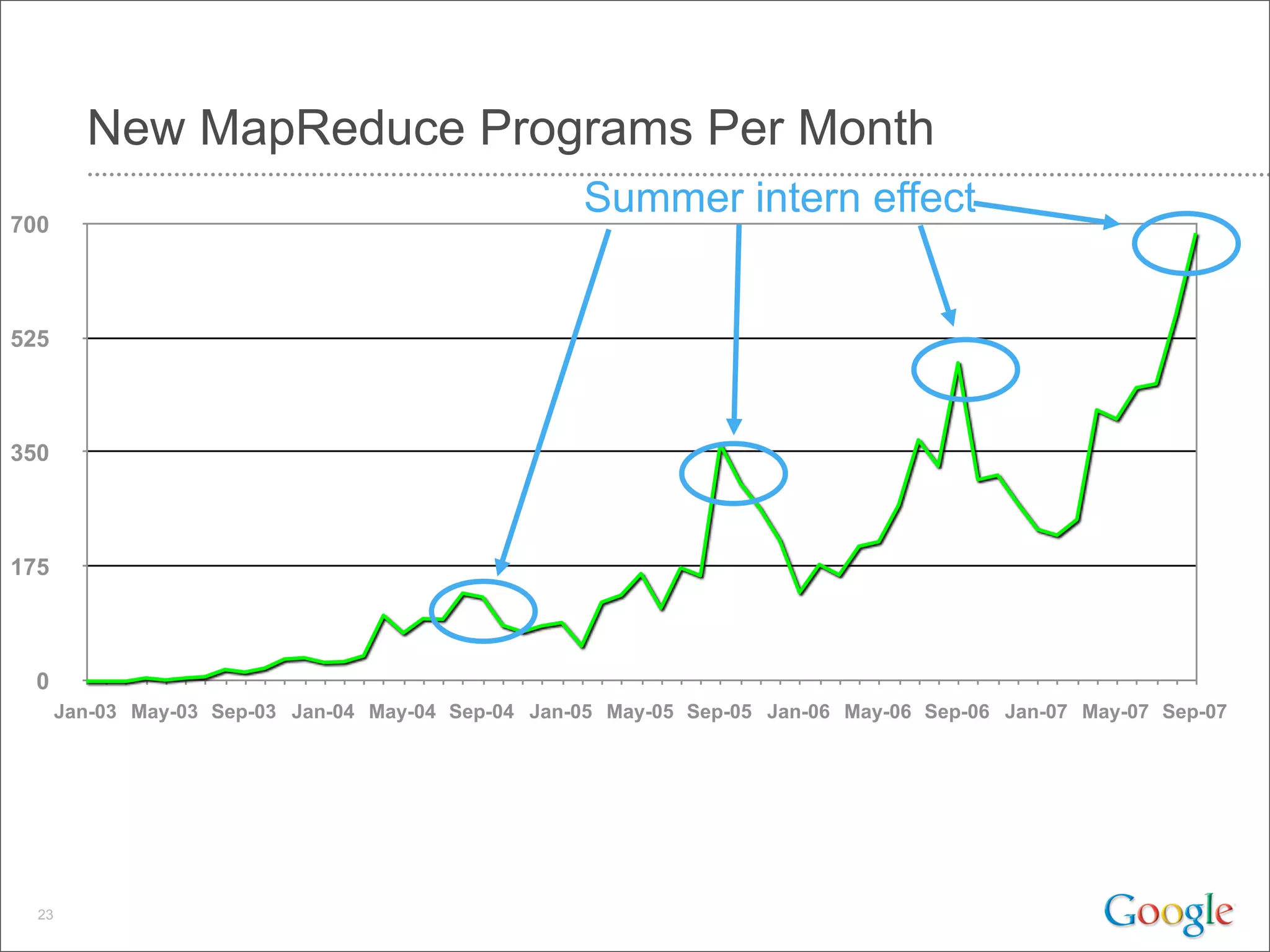





This document discusses Google's systems for handling large datasets, including their hardware infrastructure, distributed systems like GFS and BigTable, and future directions. It notes that Google uses many low-cost machines running Linux and in-house software to provide redundancy and scalability. Distributed file system GFS and database BigTable are used to store and access petabytes of data across thousands of machines.



























![An Overview of [Linux] Kernel Lock Improvements -- Linuxcon NA 2014](https://cdn.slidesharecdn.com/ss_thumbnails/linuxcon-2014-locking-final-140826225054-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)




























![[DevFest Strasbourg 2025] - NodeJs Can do that !!](https://cdn.slidesharecdn.com/ss_thumbnails/devfeststrasbourg2025-nodejscandothat-251127142731-da65b6fd-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Full-Stack Development] Digital Accessibility: Why Developers nee...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-digitalaccessibilitywhydevelopersneedtoknowandcarein2025-251127011019-0674441d-thumbnail.jpg?width=640&height=640&fit=bounds)






![[BDD 2025 - Artificial Intelligence] Building AI Systems That Users (and Comp...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-buildingaisystemsthatusersandcompanieslove-251124030845-038f7732-thumbnail.jpg?width=640&height=640&fit=bounds)








![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)
