Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Masaru Tokuoka
2,688 views
inferences with gaussians: 記法によるrstanの推定結果の違い
広島大学で開催されているBayesian Cognitive Modelingの輪読会での発表資料です。
Education
◦
Read more
1
Save
Share
Embed
Embed presentation
Download
Download to read offline
1
/ 11
2
/ 11
3
/ 11
4
/ 11
5
/ 11
6
/ 11
7
/ 11
8
/ 11
9
/ 11
10
/ 11
11
/ 11
More Related Content
PDF
データ入力が終わってから分析前にすること
by
Masaru Tokuoka
PDF
MCMCで研究報告
by
Masaru Tokuoka
PDF
ベイズ主義による研究の報告方法
by
Masaru Tokuoka
PDF
第2回DARM勉強会
by
Masaru Tokuoka
PPTX
第1回DARM勉強会のANOVA補足(repeated measures designs)
by
Masaru Tokuoka
PDF
DARM勉強会第3回 (missing data analysis)
by
Masaru Tokuoka
PDF
rstanで情報仮説によるモデル評価してみる@Hjiyama.R
by
Masaru Tokuoka
PDF
ポワソン分布の分布感をつかむ
by
Masaru Tokuoka
データ入力が終わってから分析前にすること
by
Masaru Tokuoka
MCMCで研究報告
by
Masaru Tokuoka
ベイズ主義による研究の報告方法
by
Masaru Tokuoka
第2回DARM勉強会
by
Masaru Tokuoka
第1回DARM勉強会のANOVA補足(repeated measures designs)
by
Masaru Tokuoka
DARM勉強会第3回 (missing data analysis)
by
Masaru Tokuoka
rstanで情報仮説によるモデル評価してみる@Hjiyama.R
by
Masaru Tokuoka
ポワソン分布の分布感をつかむ
by
Masaru Tokuoka
Viewers also liked
PDF
第2回DARM勉強会.preacherによるmoderatorの検討
by
Masaru Tokuoka
PPTX
13.01.20.第1回DARM勉強会資料#3
by
Yoshitake Takebayashi
PDF
第4回DARM勉強会 (多母集団同時分析)
by
Masaru Tokuoka
PDF
エクセルで統計分析 統計プログラムHADについて
by
Hiroshi Shimizu
PDF
RでMplusがもっと便利にーmplusAutomationパッケージー #Hiroshimar05
by
Masaru Tokuoka
PDF
SEMを用いた縦断データの解析 潜在曲線モデル
by
Masaru Tokuoka
PPTX
偽相関と偏相関係数
by
Teruki Shinohara
PPTX
Tokyo r #37 Rubin's Rule
by
Hiroki Matsui
PDF
多重代入法の書き方 公開用
by
Koichiro Gibo
PPTX
要因計画データに対するベイズ推定アプローチ
by
Takashi Yamane
PDF
[AWSマイスターシリーズ] AWS CLI / AWS Tools for Windows PowerShell
by
Amazon Web Services Japan
第2回DARM勉強会.preacherによるmoderatorの検討
by
Masaru Tokuoka
13.01.20.第1回DARM勉強会資料#3
by
Yoshitake Takebayashi
第4回DARM勉強会 (多母集団同時分析)
by
Masaru Tokuoka
エクセルで統計分析 統計プログラムHADについて
by
Hiroshi Shimizu
RでMplusがもっと便利にーmplusAutomationパッケージー #Hiroshimar05
by
Masaru Tokuoka
SEMを用いた縦断データの解析 潜在曲線モデル
by
Masaru Tokuoka
偽相関と偏相関係数
by
Teruki Shinohara
Tokyo r #37 Rubin's Rule
by
Hiroki Matsui
多重代入法の書き方 公開用
by
Koichiro Gibo
要因計画データに対するベイズ推定アプローチ
by
Takashi Yamane
[AWSマイスターシリーズ] AWS CLI / AWS Tools for Windows PowerShell
by
Amazon Web Services Japan
Similar to inferences with gaussians: 記法によるrstanの推定結果の違い
PDF
StanとRでベイズ統計モデリング読書会 導入編(1章~3章)
by
Hiroshi Shimizu
PDF
Stanコードの書き方 中級編
by
Hiroshi Shimizu
PDF
PRML 10.3, 10.4 (Pattern Recognition and Machine Learning)
by
Toshiyuki Shimono
PDF
RStanとShinyStanによるベイズ統計モデリング入門
by
Masaki Tsuda
PPTX
ベイズ統計学の概論的紹介
by
Naoki Hayashi
PPTX
NagoyaStat#7 StanとRでベイズ統計モデリング(アヒル本)4章の発表資料
by
nishioka1
PDF
Stan超初心者入門
by
Hiroshi Shimizu
PDF
StanTutorial
by
Teito Nakagawa
PDF
Stanでガウス過程
by
Hiroshi Shimizu
PDF
MCMCサンプルの使い方 ~見る・決める・探す・発生させる~
by
. .
PDF
Stan勉強会資料(前編)
by
daiki hojo
PPTX
StanとRでベイズ統計モデリング 1,2章
by
Miki Katsuragi
StanとRでベイズ統計モデリング読書会 導入編(1章~3章)
by
Hiroshi Shimizu
Stanコードの書き方 中級編
by
Hiroshi Shimizu
PRML 10.3, 10.4 (Pattern Recognition and Machine Learning)
by
Toshiyuki Shimono
RStanとShinyStanによるベイズ統計モデリング入門
by
Masaki Tsuda
ベイズ統計学の概論的紹介
by
Naoki Hayashi
NagoyaStat#7 StanとRでベイズ統計モデリング(アヒル本)4章の発表資料
by
nishioka1
Stan超初心者入門
by
Hiroshi Shimizu
StanTutorial
by
Teito Nakagawa
Stanでガウス過程
by
Hiroshi Shimizu
MCMCサンプルの使い方 ~見る・決める・探す・発生させる~
by
. .
Stan勉強会資料(前編)
by
daiki hojo
StanとRでベイズ統計モデリング 1,2章
by
Miki Katsuragi
inferences with gaussians: 記法によるrstanの推定結果の違い
1.
4. Inferences with Gaussians 発達心理学研究室
D4 徳岡 大 2015年6月11日 1
2.
この資料の目的 • 「Bayesian Cognitive
Modeling」の4章のデータを 使って,rstanの記法の特徴をつかむこと • 同じモデルでもいくつかの書き方があることや同 じモデルを書いているはずなのに,サンプルサイ ズが小さすぎると平均の推定がおかしくなること がある,ということを体感してもらいたい 2
3.
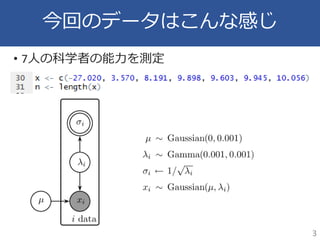
今回のデータはこんな感じ • 7人の科学者の能力を測定 3
4.
知っておくと便利?な BUGSとstanの使用の違い • 正規分布を用いる場合にBUGSとstanで使用が異なる • mu
= μ, sigma = sd • BUGSの場合: Gaussian (mu, 1/sigma^2) • stanの場合: normal (mu, sigma) • Baysian Cognitive Modeling のstanコードはBUGSを もとにしたためか,ややこしいやり方をしてい ることがある • 分散の無情報事前分布として,逆γ分布が 使用される • stanの場合,実はcaucy分布のほうがよい 4
5.
BUGS的なCodeの書き方 5 sigma = 1/sqrt(λ) λがγ分布 λが分散のつもり
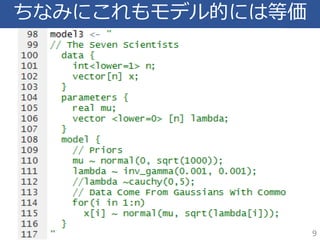
6.
このモデルと等価なはず! 6 λが逆γ分布 lambdas = sqrt(λ) λが分散のつもり
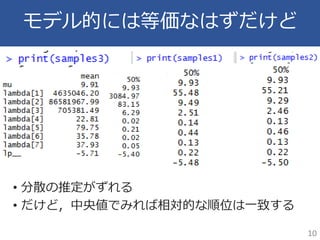
7.
推定平均値を比較したけど・・・ 7 • 平均がなんかずれてる。。 • このモデルの分散はN=1に基づくもの。階層モデル ともちょっと違う感じ
8.
中央値なら! • サンプルサイズが小さすぎるときは中央値のほう がMCMCの結果は頑健っぽい 8
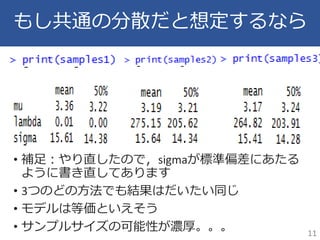
9.
ちなみにこれもモデル的には等価 9
10.
モデル的には等価なはずだけど • 分散の推定がずれる • だけど,中央値でみれば相対的な順位は一致する 10
11.
もし共通の分散だと想定するなら • 補足:やり直したので,sigmaが標準偏差にあたる ように書き直してあります • 3つのどの方法でも結果はだいたい同じ •
モデルは等価といえそう • サンプルサイズの可能性が濃厚。。。 11
Download



























![[AWSマイスターシリーズ] AWS CLI / AWS Tools for Windows PowerShell](https://cdn.slidesharecdn.com/ss_thumbnails/20140115aws-meister-regenerate-awsclipowershell-140130055421-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)











