Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Masaru Tokuoka
5,084 views
rstanで情報仮説によるモデル評価してみる@Hjiyama.R
Education
◦
Read more
13
Save
Share
Embed
Embed presentation
Download
Downloaded 32 times
1
/ 29
2
/ 29
3
/ 29
4
/ 29
5
/ 29
6
/ 29
7
/ 29
8
/ 29
9
/ 29
10
/ 29
11
/ 29
12
/ 29
13
/ 29
14
/ 29
15
/ 29
16
/ 29
17
/ 29
18
/ 29
19
/ 29
20
/ 29
21
/ 29
22
/ 29
23
/ 29
24
/ 29
25
/ 29
26
/ 29
27
/ 29
28
/ 29
29
/ 29
More Related Content
PDF
RでMplusがもっと便利にーmplusAutomationパッケージー #Hiroshimar05
by
Masaru Tokuoka
PPTX
心理統計の課題をRmdで作る
by
考司 小杉
PPTX
データ分析スクリプトのツール化入門 - PyConJP 2016
by
Akinori Kohno
PDF
Pythonによるソーシャルデータ分析―わたしはこうやって修士号を取得しました―
by
Hisao Soyama
PPTX
Kandai R 入門者講習
by
考司 小杉
PPTX
Slack data Analysis
by
takutori
PDF
Kandai.R #1 公開用
by
Daisuke Nakanishi
PDF
RとPythonによるデータ解析入門
by
Atsushi Hayakawa
RでMplusがもっと便利にーmplusAutomationパッケージー #Hiroshimar05
by
Masaru Tokuoka
心理統計の課題をRmdで作る
by
考司 小杉
データ分析スクリプトのツール化入門 - PyConJP 2016
by
Akinori Kohno
Pythonによるソーシャルデータ分析―わたしはこうやって修士号を取得しました―
by
Hisao Soyama
Kandai R 入門者講習
by
考司 小杉
Slack data Analysis
by
takutori
Kandai.R #1 公開用
by
Daisuke Nakanishi
RとPythonによるデータ解析入門
by
Atsushi Hayakawa
Similar to rstanで情報仮説によるモデル評価してみる@Hjiyama.R
PDF
これからの仮説検証・モデル評価
by
daiki hojo
PDF
Rブートキャンプ
by
Kosuke Sato
PDF
StanとRでベイズ統計モデリング読書会 導入編(1章~3章)
by
Hiroshi Shimizu
PPTX
StanとRでベイズ統計モデリングに関する読書会(Osaka.stan) 第四章
by
nocchi_airport
PDF
Bayesian Sushistical Modeling
by
daiki hojo
PPTX
NagoyaStat#7 StanとRでベイズ統計モデリング(アヒル本)4章の発表資料
by
nishioka1
PDF
Stanコードの書き方 中級編
by
Hiroshi Shimizu
PPTX
要因計画データに対するベイズ推定アプローチ
by
Takashi Yamane
PDF
Pystan for nlp
by
Xiangze
PDF
東大計数特別講義20130528
by
Yoichi Motomura
PDF
Rでベイズをやってみよう!(コワい本1章)@BCM勉強会
by
Shushi Namba
PDF
Jubatusにおける大規模分散オンライン機械学習
by
Preferred Networks
PDF
【Zansa】第12回勉強会 -PRMLからベイズの世界へ
by
Zansa
PDF
Stanの紹介と応用事例(age heapingの統計モデル)
by
. .
PDF
Stan勉強会資料(前編)
by
daiki hojo
PPT
Rの壁
by
Tokyo Medical and Dental University
PDF
統計ソフトRの使い方_2015.04.17
by
hicky1225
PDF
EMNLP 2011 reading
by
正志 坪坂
PDF
3.4
by
show you
PDF
Infer net wk77_110613-1523
by
Wataru Kishimoto
これからの仮説検証・モデル評価
by
daiki hojo
Rブートキャンプ
by
Kosuke Sato
StanとRでベイズ統計モデリング読書会 導入編(1章~3章)
by
Hiroshi Shimizu
StanとRでベイズ統計モデリングに関する読書会(Osaka.stan) 第四章
by
nocchi_airport
Bayesian Sushistical Modeling
by
daiki hojo
NagoyaStat#7 StanとRでベイズ統計モデリング(アヒル本)4章の発表資料
by
nishioka1
Stanコードの書き方 中級編
by
Hiroshi Shimizu
要因計画データに対するベイズ推定アプローチ
by
Takashi Yamane
Pystan for nlp
by
Xiangze
東大計数特別講義20130528
by
Yoichi Motomura
Rでベイズをやってみよう!(コワい本1章)@BCM勉強会
by
Shushi Namba
Jubatusにおける大規模分散オンライン機械学習
by
Preferred Networks
【Zansa】第12回勉強会 -PRMLからベイズの世界へ
by
Zansa
Stanの紹介と応用事例(age heapingの統計モデル)
by
. .
Stan勉強会資料(前編)
by
daiki hojo
Rの壁
by
Tokyo Medical and Dental University
統計ソフトRの使い方_2015.04.17
by
hicky1225
EMNLP 2011 reading
by
正志 坪坂
3.4
by
show you
Infer net wk77_110613-1523
by
Wataru Kishimoto
More from Masaru Tokuoka
PDF
混合モデルを使って反復測定分散分析をする
by
Masaru Tokuoka
PDF
MCMCで研究報告
by
Masaru Tokuoka
PPTX
第1回DARM勉強会のANOVA補足(repeated measures designs)
by
Masaru Tokuoka
PDF
SEMを用いた縦断データの解析 潜在曲線モデル
by
Masaru Tokuoka
PDF
第4回DARM勉強会 (多母集団同時分析)
by
Masaru Tokuoka
PDF
DARM勉強会第3回 (missing data analysis)
by
Masaru Tokuoka
PDF
170826 tokyo r_lt
by
Masaru Tokuoka
PDF
データ入力が終わってから分析前にすること
by
Masaru Tokuoka
PDF
ポワソン分布の分布感をつかむ
by
Masaru Tokuoka
PDF
第2回DARM勉強会.preacherによるmoderatorの検討
by
Masaru Tokuoka
PDF
ベイズ主義による研究の報告方法
by
Masaru Tokuoka
PDF
第2回DARM勉強会
by
Masaru Tokuoka
PDF
inferences with gaussians: 記法によるrstanの推定結果の違い
by
Masaru Tokuoka
混合モデルを使って反復測定分散分析をする
by
Masaru Tokuoka
MCMCで研究報告
by
Masaru Tokuoka
第1回DARM勉強会のANOVA補足(repeated measures designs)
by
Masaru Tokuoka
SEMを用いた縦断データの解析 潜在曲線モデル
by
Masaru Tokuoka
第4回DARM勉強会 (多母集団同時分析)
by
Masaru Tokuoka
DARM勉強会第3回 (missing data analysis)
by
Masaru Tokuoka
170826 tokyo r_lt
by
Masaru Tokuoka
データ入力が終わってから分析前にすること
by
Masaru Tokuoka
ポワソン分布の分布感をつかむ
by
Masaru Tokuoka
第2回DARM勉強会.preacherによるmoderatorの検討
by
Masaru Tokuoka
ベイズ主義による研究の報告方法
by
Masaru Tokuoka
第2回DARM勉強会
by
Masaru Tokuoka
inferences with gaussians: 記法によるrstanの推定結果の違い
by
Masaru Tokuoka
rstanで情報仮説によるモデル評価してみる@Hjiyama.R
1.
rstanで情報仮説による モデル評価をしてみる 広島大学大学院教育学研究科 徳岡 大 1 第2回R勉強会@広島(#HijiyamaR) 2015年5月23日
2.
自己紹介 • 徳岡 ⼤大(とくおか まさる) • 広島⼤大学⼤大学院教育学研究科D4 •
動機づけ,⽬目標理理論論なんかの研究してます • R歴:4年年⽬目。思い通りに関数とか使えないまだまだ初⼼心者 • twitter: @t_̲macya • DARM(RとMplusを使⽤用した医療療・⼼心理理データ解析勉強会) を主催しています。今年年も1回くらいは開催したい。。 2
3.
本発表のモチベーション • 前回のHiRoshima.Rに参加できなかった無念念 • なんだか周りでベイズやらMCMCが流流⾏行行っている •
ベイズを使うと仮説の尤もらしさが⽐比較できるらしい し,差がないという仮説も主張できるらしい • 論論⽂文にはBUGSのコードが載っていてもrstanの コードはないのでrstanに翻訳しながら,理理解を 深めていきたい 3
4.
注意!! • 発表者もまだ発表内容について勉強中 • 発表内容は,コードなどは⼀一応計算結果を確認して いるが,概念念的な理理解の細かいところで誤っている 可能性はあり •
間違いなどを⾒見見つけたらご指摘ください! • 今回の内容は,基本的に以下の紹介 岡⽥田謙介 (2014). ベイズ統計による情報仮説の評価 は分散分析にとって代わるか? 基礎⼼心理理学研究, 32, 2, 223-‐‑‒231. • なので,詳しく知りたい⼈人は岡⽥田(2014)を。 4
5.
情報仮説でモデル評価のメリット • 帰無仮説も含めて,どの仮説が尤もらしいか ⽐比較できる • 仮説の複雑さも反映される •
事後モデル確率率率(posterior model probability: PMP)を求めることでそれぞれの仮説が真で ある確率率率を算出できる←わかりやすい! • 他のベイズ主義的なメリットも享受できる 5
6.
情報仮説でモデル評価って何? • 情報仮説:不不等式制約で表現される仮説(
) • 無制約仮説( ) • 情報仮説の複雑さを考慮して,ベイズファクターを算 出。ベイズファクターの値で評価する ※仮説の複雑さ:情報仮説と整合的な確率率率密度度の割合 ※ベイズファクター(BF):前⽥田和寛先⽣生の資料料がわかりやすい ので参照してください(http://www.slideshare.net/ kazutantan/bayes-‐‑‒factor) 6
7.
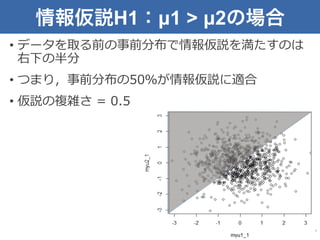
情報仮説H1:µ1 > µ2の場合 •
データを取る前の事前分布で情報仮説を満たすのは 右下の半分 • つまり,事前分布の50%が情報仮説に適合 • 仮説の複雑さ = 0.5 7
8.
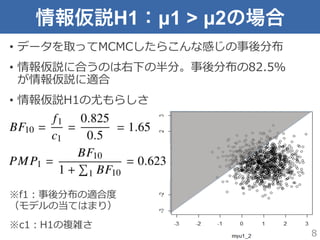
情報仮説H1:µ1 > µ2の場合 •
データを取ってMCMCしたらこんな感じの事後分布 • 情報仮説に合うのは右下の半分。事後分布の82.5% が情報仮説に適合 • 情報仮説H1の尤もらしさ ※f1:事後分布の適合度度 (モデルの当てはまり) ※c1:H1の複雑さ 8
9.
岡田(2014)をrstanで再現 • 使⽤用データ:マウスの体重データ(Lock5Data パッケージのLightatNightというデータセット) • 従属変数:4週間後の体重の増加量量 •
独⽴立立変数:LD群,LL群,DM群の1要因3⽔水準 • 3つの仮説 • どの仮説が真である確率率率が⾼高いか 9
10.
分析前にデータを整えたり 10 パッケージを読み込んから データセットを読み込む 独⽴立立変数の⽔水準に対応するダミー変数を作成 ①独⽴立立変数のダミー変数と従属変数だけをdat3に移す② 各変数の名前を変更更③サンプルサイズの変数を作成
11.
データをリスト形式に 11 rstanが読み込めるリスト形 式にする。 こんな⾵風になっていれば ⼤大丈夫
12.
stanコード 12 このあたりのことは,⼩小杉考司先⽣生の資料料 がわかりやすいので参照してください。 http://www.slideshare.net/KojiKosugi/r-stan ”informative_hypothese.stan”というファイ ル名でこのモデルを作業ディレクトリに 保存しておきます。
13.
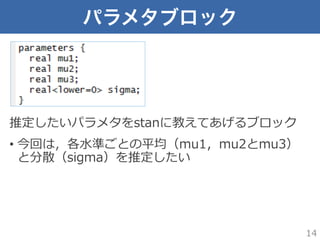
データブロック • stanに読み込ませるデータセットにどんなものが ⼊入っているかを教えてあげるブロック • int:整数 •
real:実数 • [ ]内は添え字。d1とかは n 個⼊入ってますよ 13
14.
パラメタブロック 推定したいパラメタをstanに教えてあげるブロック • 今回は,各⽔水準ごとの平均(mu1,mu2とmu3) と分散(sigma)を推定したい 14
15.
パラメタ変換ブロック 推定したいパラメタを変換するブロック • 平均を各⽔水準と対応させるためにmu1〜~3とd1〜~3 を組み合わせてmuという変数を作成 • sigmaを平⽅方根して,sという標準偏差を推定 •
新しいパラメタを全て指定してから,変換式を記述 15
16.
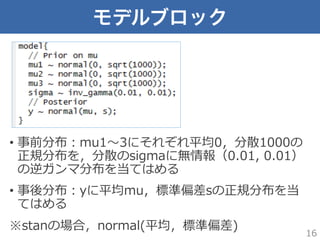
モデルブロック • 事前分布:mu1〜~3にそれぞれ平均0,分散1000の 正規分布を,分散のsigmaに無情報(0.01, 0.01) の逆ガンマ分布を当てはめる •
事後分布:yに平均mu,標準偏差sの正規分布を当 てはめる ※stanの場合,normal(平均,標準偏差) 16
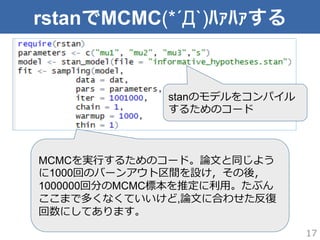
17.
rstanでMCMC(*´Д`)ハァハァする 17 stanのモデルをコンパイル するためのコード MCMCを実⾏行行するためのコード。論論⽂文と同じよう に1000回のバーンアウト区間を設け,その後, 1000000回分のMCMC標本を推定に利利⽤用。たぶん ここまで多くなくていいけど,論論⽂文に合わせた反復復 回数にしてあります。
18.
結果を見てみる • 元のデータセットのデータと⽐比較 18
19.
BFとPMPの算出 19 MCMC標本の抽出 ①MCMC標本それぞれに対してDM > LDなら1,でなけれ ば0でコード化②LL
> DMなら1 ,でなければ0でコード化 ③DM > LDかつLL > DMなら1でなければ0でコード化④③ を満たすMCMC標本の割合を算出
20.
BFとPMPの算出 20 複雑さは,⺟母数の数と不不等式の数の場合 の数によって求めることができる(c1 = 3! =
6, c2 = 3C1 = 3) BFの算出 PMPの算出 • 残りのBFやPMPも同様に算出していく
21.
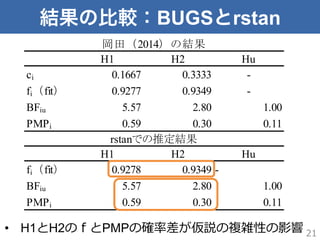
結果の比較:BUGSとrstan H1 H2 Hu ci
0.1667 0.3333 - fi(fit) 0.9277 0.9349 - BFiu 5.57 2.80 1.00 PMPi 0.59 0.30 0.11 H1 H2 Hu fi(fit) 0.9278 0.9349 - BFiu 5.57 2.80 1.00 PMPi 0.59 0.30 0.11 岡田(2014)の結果 rstanでの推定結果 21• H1とH2のfとPMPの確率率率差が仮説の複雑性の影響
22.
ついでに自分のデータでもやってみた • ⽇日本版達成⽬目標尺度度(AGQ-‐‑‒R)の項⽬目内容の妥当性 • 習得回避⽬目標:“私の⽬目的は⾃自分のベストをつくさな いことを少しでも避けることだ” •
定義:課題習得の失敗に注意が向けられており、失 敗を回避しようとする⽬目標 • 項⽬目が失敗回避っていうよりも成功接近では?? • 回答者が項⽬目内容を失敗回避的に捉えているのかを 検討する 22
23.
データの中身 成功接近的意味 • ポジティブなこと(成功、有能)意味がどの程度度 含まれているか(7件法) 失敗回避的意味 • ネガティブなこと(失敗、無能)を回避する意味が どの程度度含まれているか(7件法) •
仮説 23 H1: 成功接近的意味<失敗回避的意味 H0: 成功接近的意味=失敗回避的意味
24.
せっかくだから階層ベイズで 今回使⽤用するstanコード • 橙⾊色枠内が平均の個⼈人差に関わる データ⽣生成モデル 24
25.
MCMCはこんな条件で • 反復復回数は21000回 (iter
=21000) • 2本のMCMCを⾛走らせる (chain = 2) • バーンアウト区間は1000回 (warmup = 1000) • 10回ごとにMCMC標本をとってくる (thin = 10) • 最終的に2000のMCMC標本が得られる 25
26.
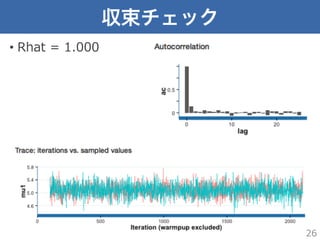
収束チェック • Rhat =
1.000 26
27.
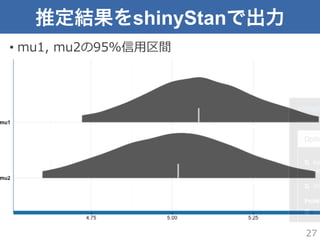
推定結果をshinyStanで出力 • mu1, mu2の95%信⽤用区間 27
28.
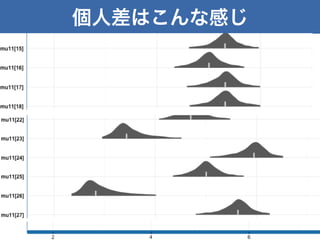
個人差はこんな感じ 28
29.
どの仮説が尤もらしいか H1:失敗回避>成功接近 • BF10 =
0.83 • PMP1 = 0.45 H0:失敗回避=成功接近 • BF00 = 1 • PMP0 = 0.55 結論論:H0のほうが妥当な仮説といえそう • 帰無仮説のBFは常に1になるのでPMPが極端に⼤大きい 値にはならない。帰無仮説を主張したい場合よりも, 複数の仮説から選択したい場合に有効かも 29
Download










![データブロック
• stanに読み込ませるデータセットにどんなものが
⼊入っているかを教えてあげるブロック
• int:整数
• real:実数
• [ ]内は添え字。d1とかは n 個⼊入ってますよ
13](https://image.slidesharecdn.com/kazutanr02-150522065243-lva1-app6892/85/rstan-Hjiyama-R-13-320.jpg)