1. The document proposes a fully distributed, peer-to-peer architecture for web crawling. The goal is to provide an efficient, decentralized system for crawling, indexing, caching and querying web pages.
2. A traditional web crawler recursively visits web pages, extracts URLs, parses pages for keywords, and visits extracted URLs. The proposed system follows this process but with a distributed, peer-to-peer architecture without a central server.
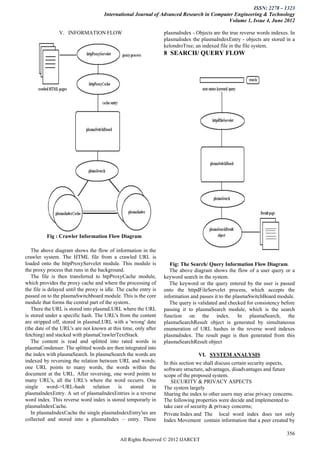
3. Each peer node includes components for crawling, indexing, and storing a local database. Peers communicate through an overlay network to distribute URLs, indexes, and search queries/results across the system in a decentralized manner.





















![[LvDuit//Lab] Crawling the web](https://cdn.slidesharecdn.com/ss_thumbnails/crawlingtheweb-140901103920-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)

























































