Downloaded 21 times

































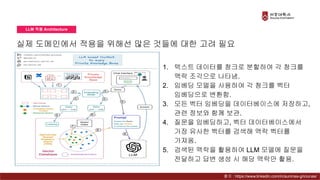
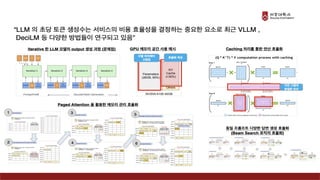
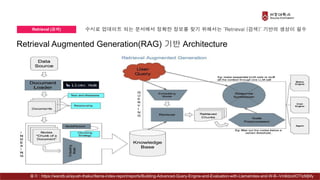
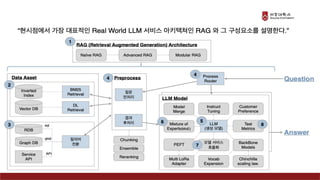

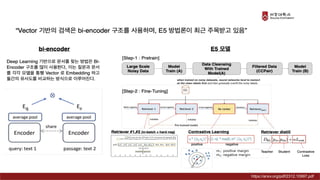
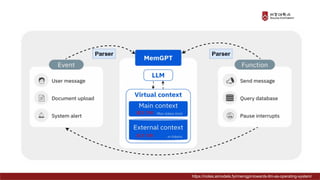
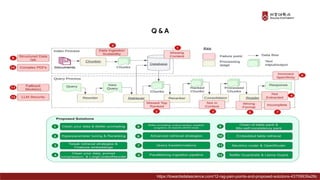
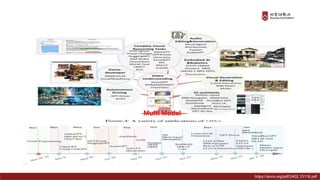

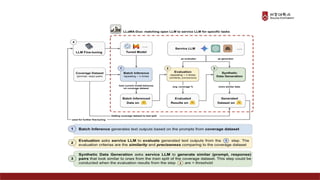

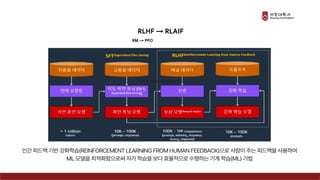

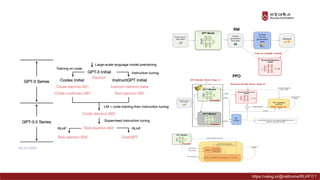
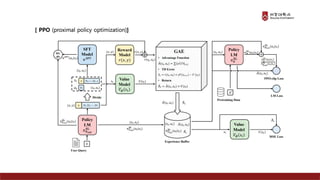






















Presentation material from the IT graduate school joint event - Korea University Graduate School of Computer Information and Communication - Sogang University Graduate School of Information and Communication - Sungkyunkwan University Graduate School of Information and Communication - Yonsei University Graduate School of Engineering - Hanyang University Graduate School of Artificial Intelligence Convergence



![[코세나, kosena] 생성AI 프로젝트와 사례](https://cdn.slidesharecdn.com/ss_thumbnails/ai-240212104807-42c291b6-thumbnail.jpg?width=640&height=640&fit=bounds)
































![[2021 Google I/O] LaMDA : Language Models for DialogApplications](https://cdn.slidesharecdn.com/ss_thumbnails/lamda-220318093910-thumbnail.jpg?width=640&height=640&fit=bounds)










![[MLOps KR 행사] MLOps 춘추 전국 시대 정리(210605)](https://cdn.slidesharecdn.com/ss_thumbnails/mlops-basic-210605064957-thumbnail.jpg?width=640&height=640&fit=bounds)



















