Download as PDF, PPTX















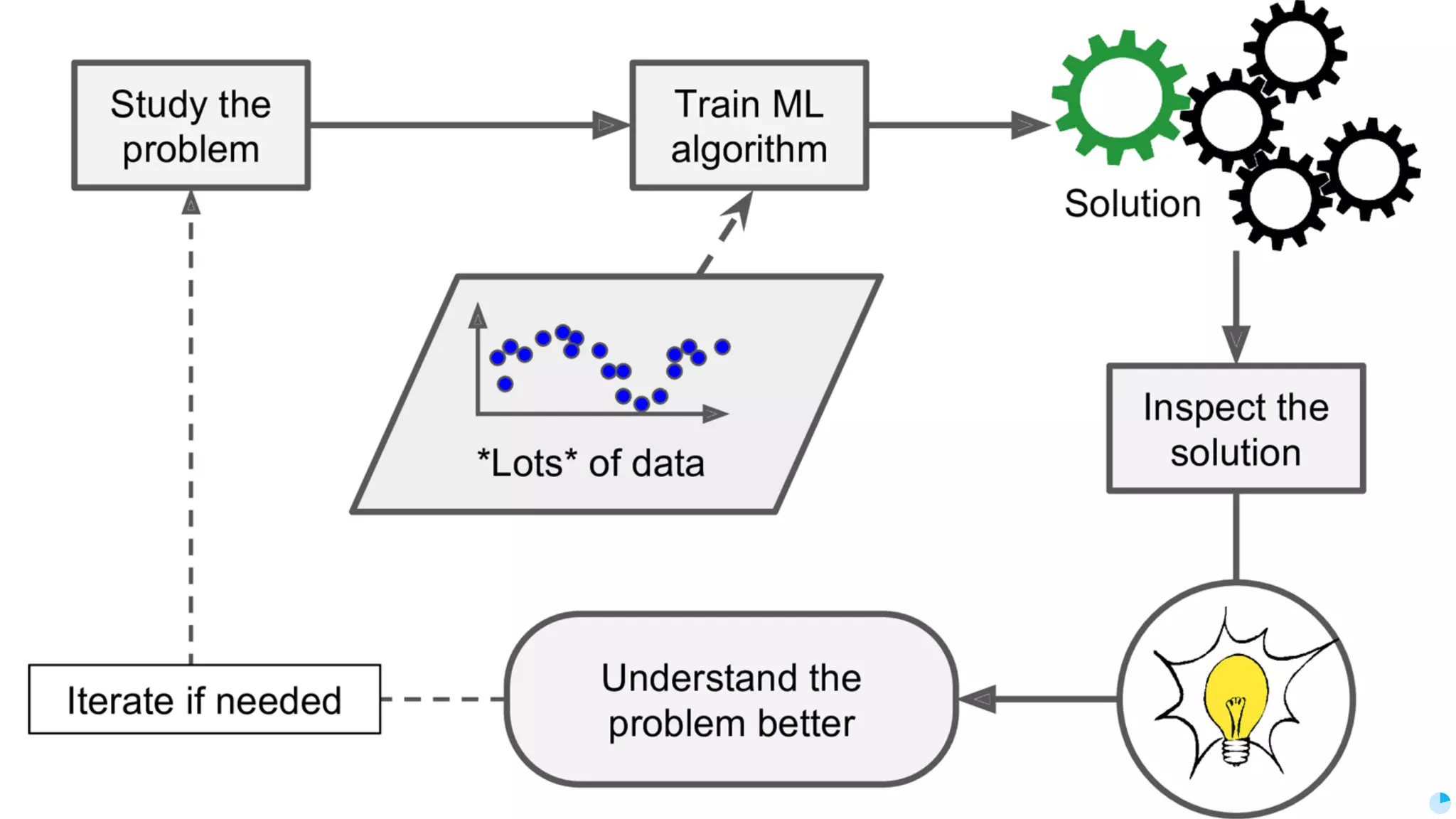
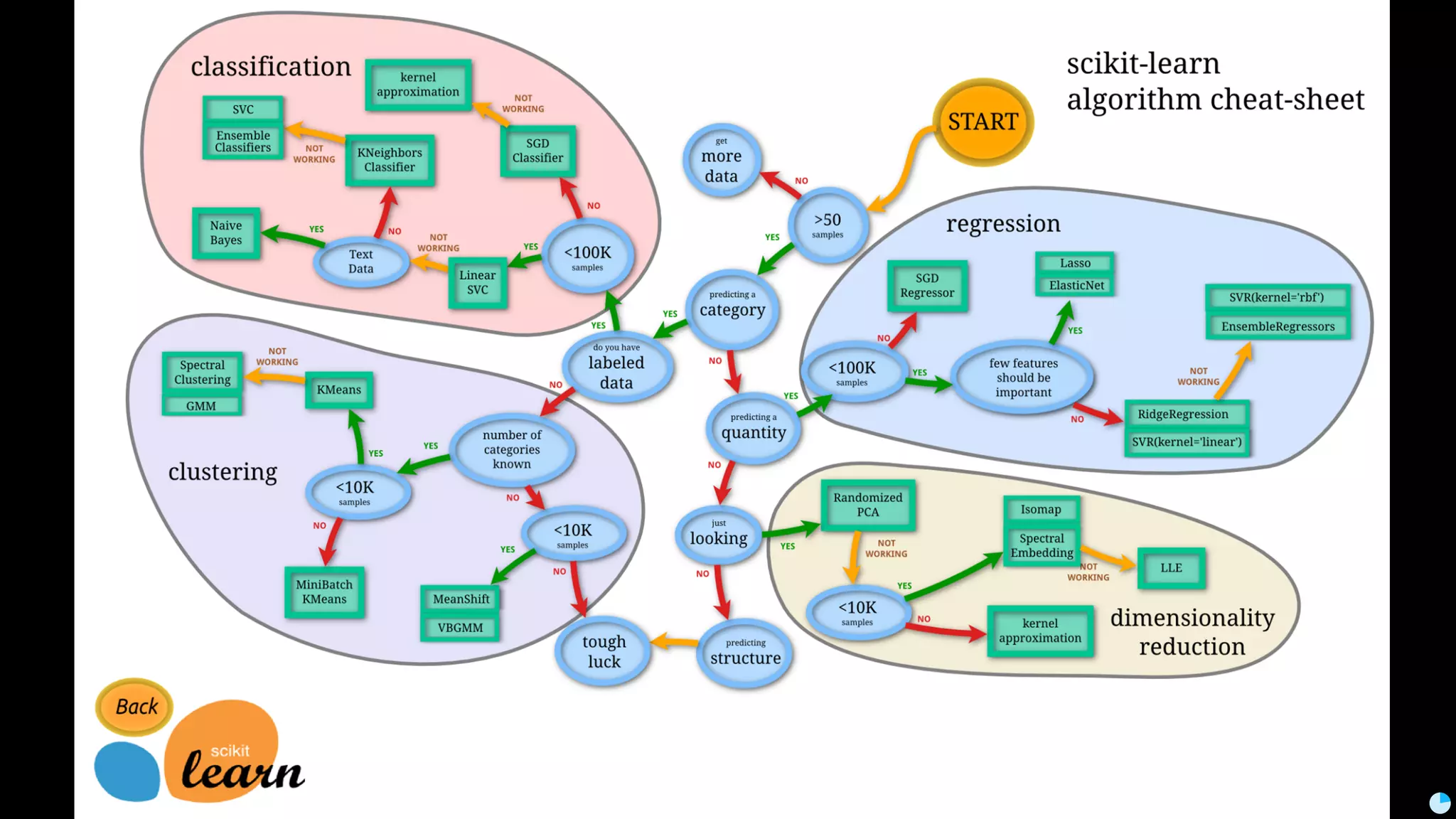
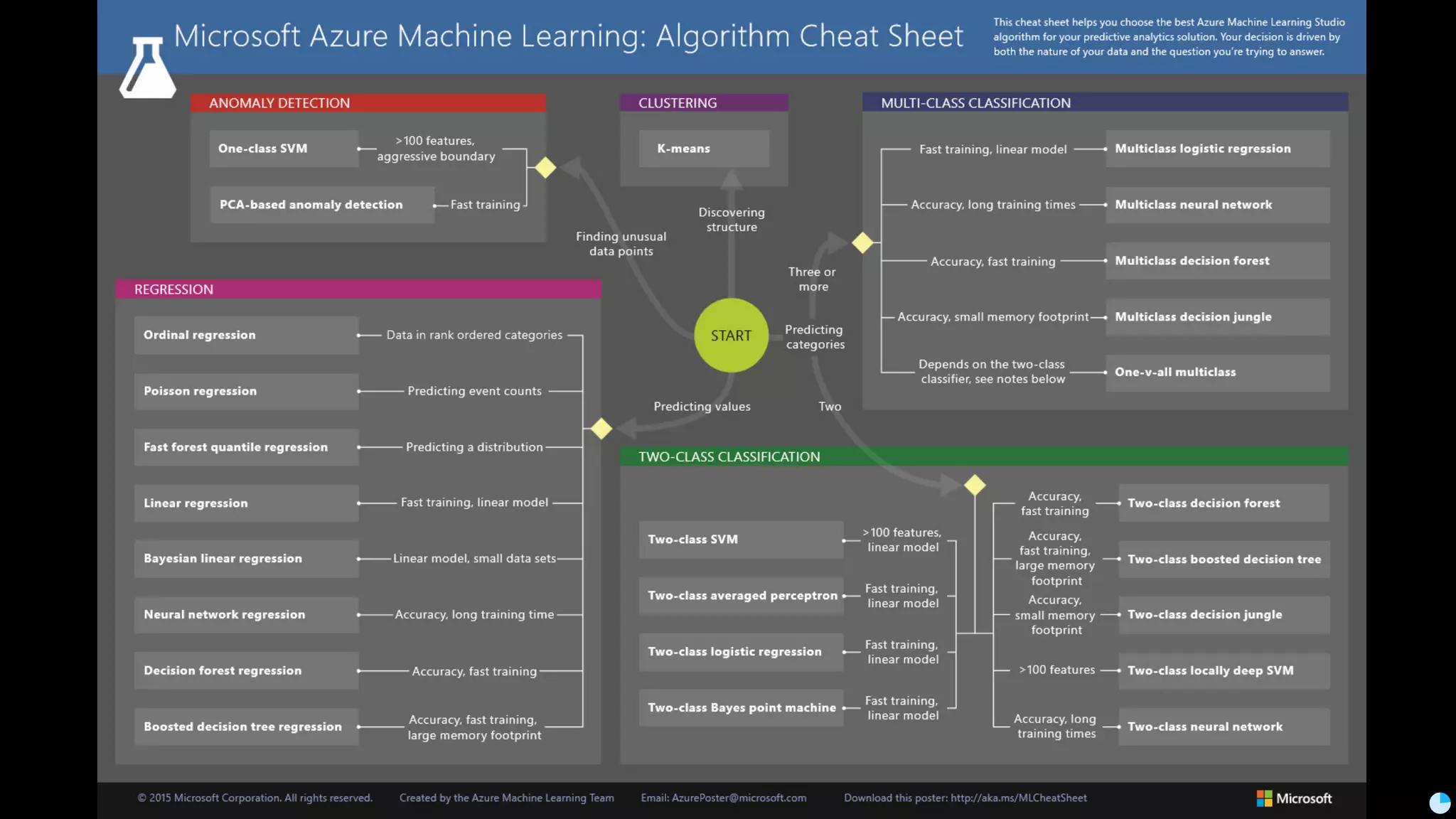

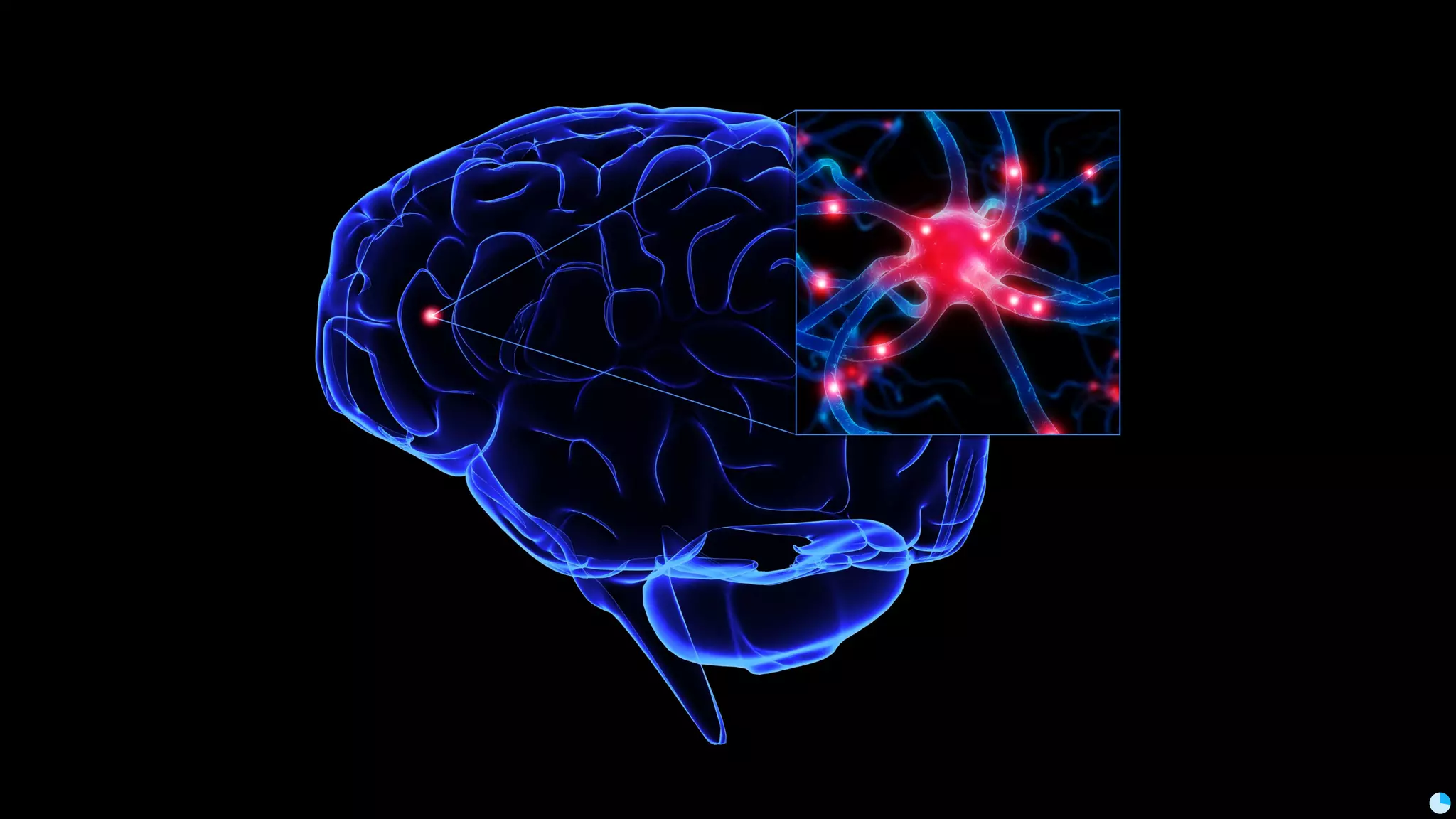

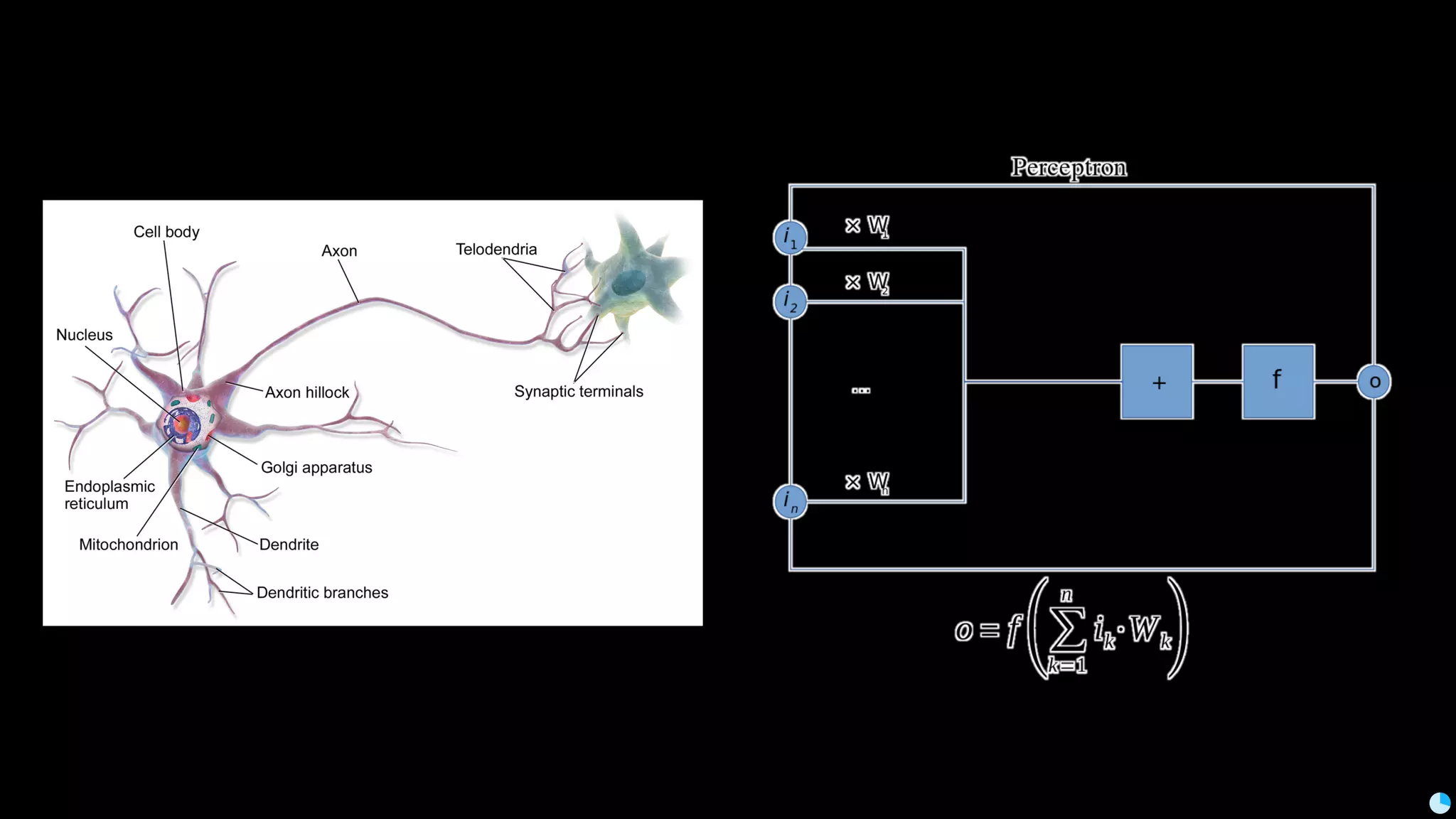













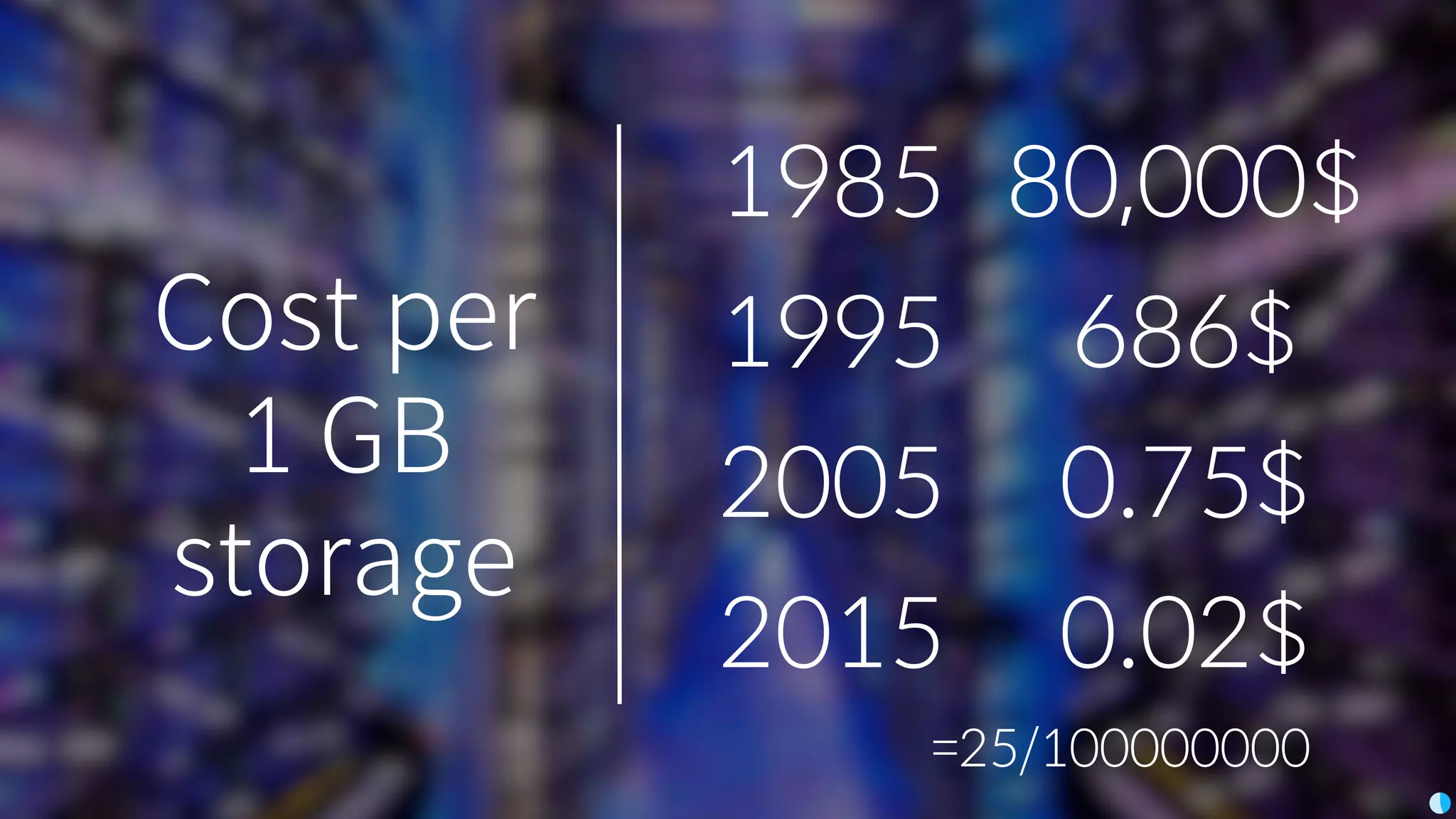










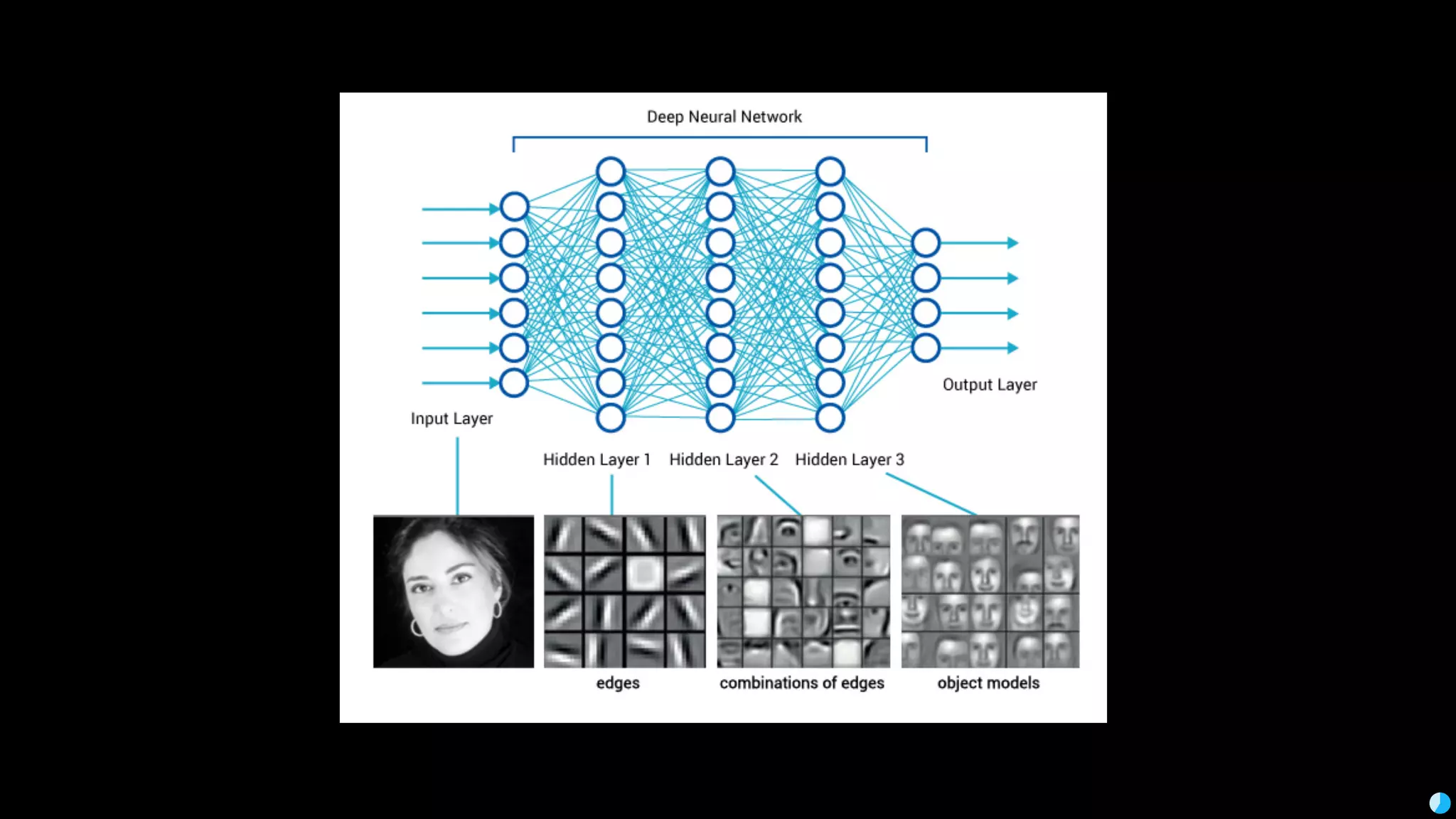













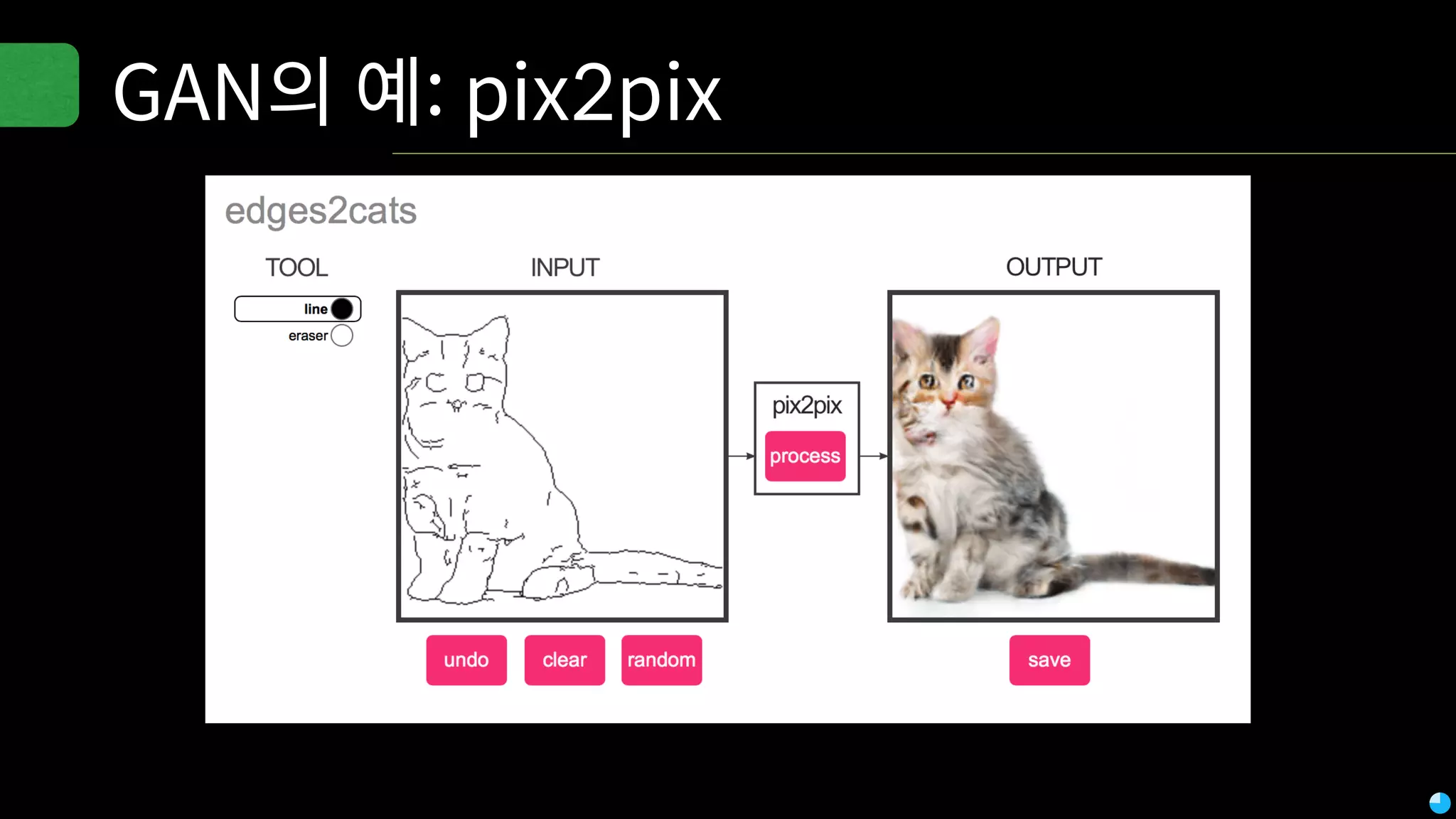





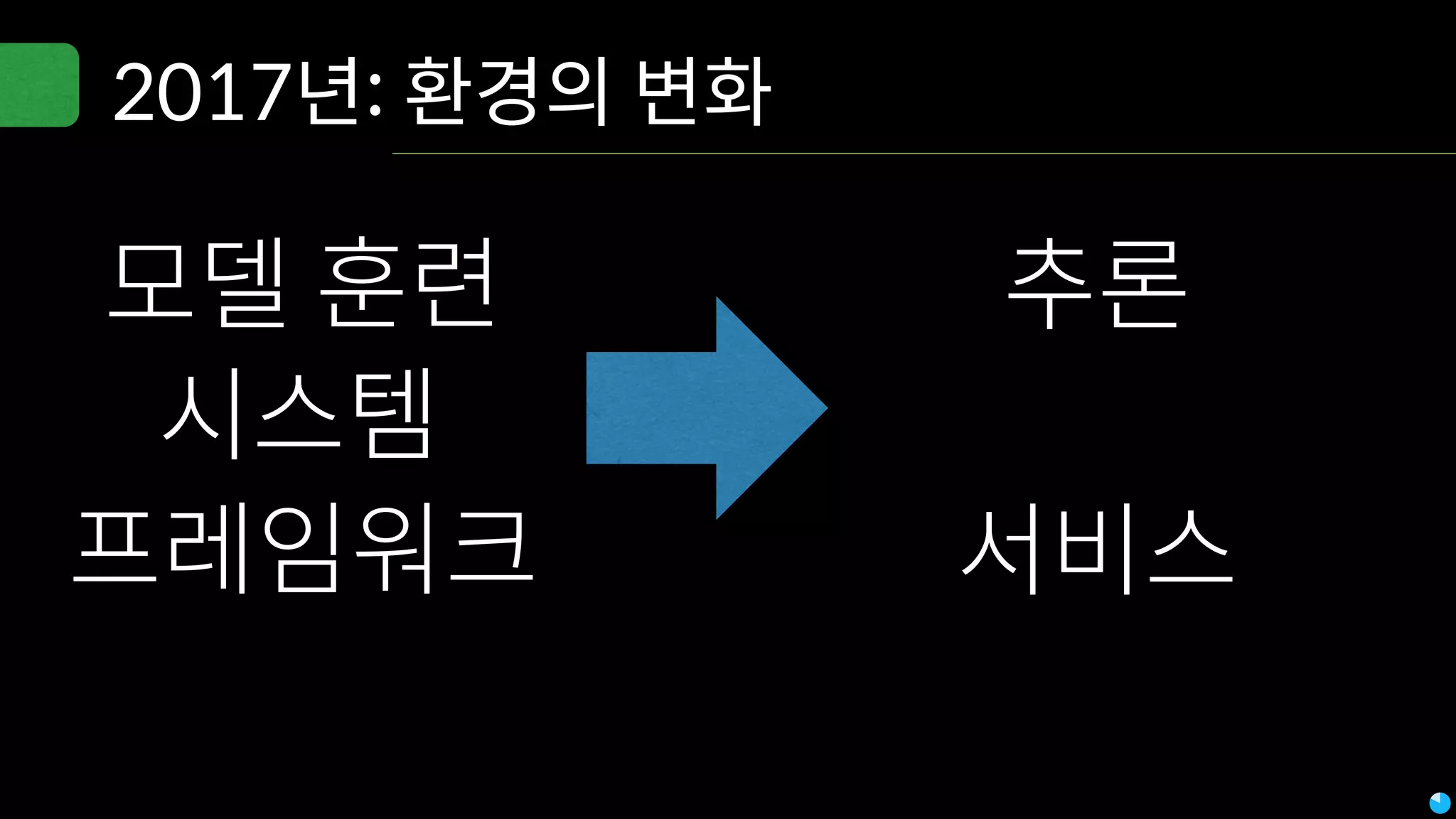
















Video (Korean): https://www.youtube.com/watch?v=r64_PeoZvao 기계학습은 최근의 연구 성과 및 기술의 발전에 힘입어 다양한 분야에 본격적으로 적용되기 시작했습니다. 2017년은 응용분야의 확장에 힘입어 기계학습 응용이 대중화되는 한 해가 될 것입니다. 이 발표에서는 기계학습이 해결한 기술적인 문제와, 현재 해결하려고 하는 난제들을 다룹니다. 또한 2017년 현재 기계학습이 응용되고 있는 분야들과 응용 방법 및, 이후 기계학습 적용을 통해 발전할 수 있는 분야들과 적용 아이디어를 이야기합니다. Machine learning has been applied to various areas in earnest owing to recent research results and technological advancements. In 2017, machine learning application will be popular with the expansion of the application area. This talk covers technical issues solved by machine learning, and difficult problems that should be solved now. It also covers the areas that apply machine learning in 2017, application methods, area that can develop by application machine learning, and application ideas.

















![[한국어] Neural Architecture Search with Reinforcement Learning](https://cdn.slidesharecdn.com/ss_thumbnails/nas-170612232020-thumbnail.jpg?width=640&height=640&fit=bounds)








![[Tf2017] day1 jwkang_pub](https://cdn.slidesharecdn.com/ss_thumbnails/tf2017day1jwkangpub-171028123944-thumbnail.jpg?width=640&height=640&fit=bounds)


![[WeFocus] 인공지능_딥러닝_특허 확보 전략_김성현_201902_v1](https://cdn.slidesharecdn.com/ss_thumbnails/aa-190217131507-thumbnail.jpg?width=640&height=640&fit=bounds)













![[오컴 Clip IT 세미나] 머신러닝과 인공지능의 현재와 미래](https://cdn.slidesharecdn.com/ss_thumbnails/kthoccamseminar-180416013406-thumbnail.jpg?width=640&height=640&fit=bounds)























