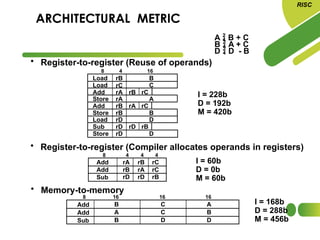
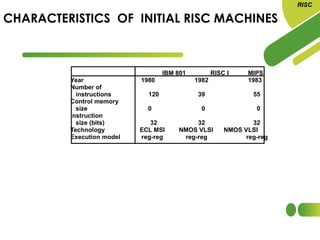
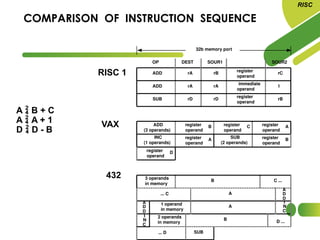
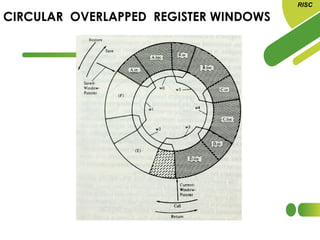
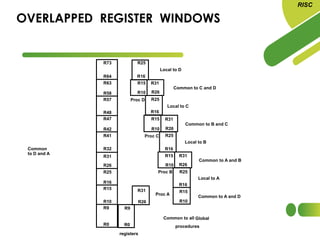
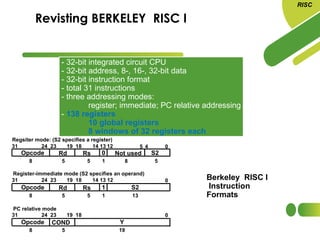
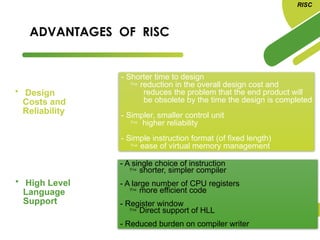
The document discusses the evolution and features of Reduced Instruction Set Computer (RISC) architecture, highlighting its simplification of instruction sets and focus on register-based operations. RISC processors utilize a fixed instruction length and hardwired control units, which enhance speed and efficiency through pipelining and minimize memory access latency. Additionally, register window techniques are proposed to optimize function calls and improve performance by reducing the need for stack operations.