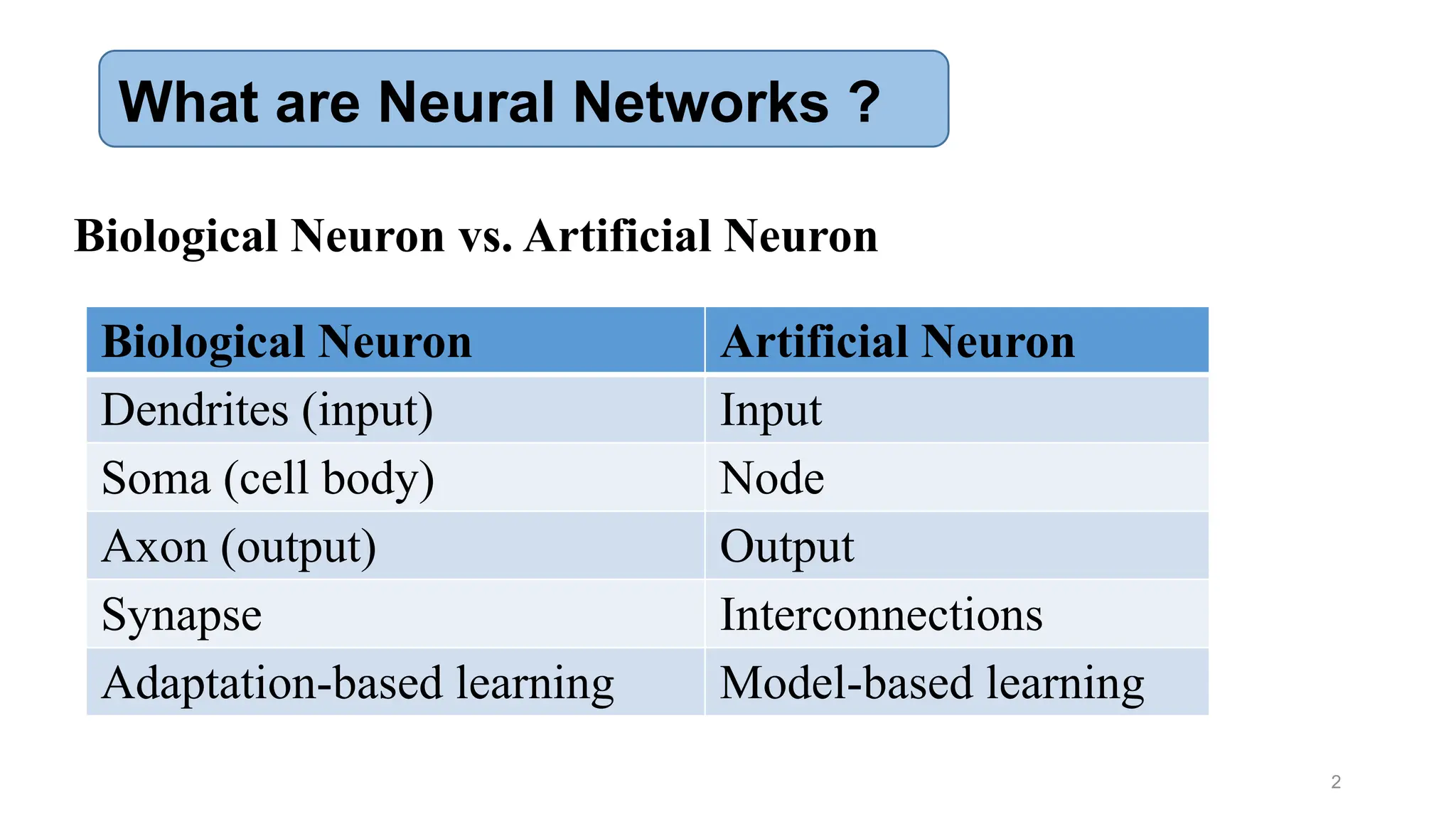
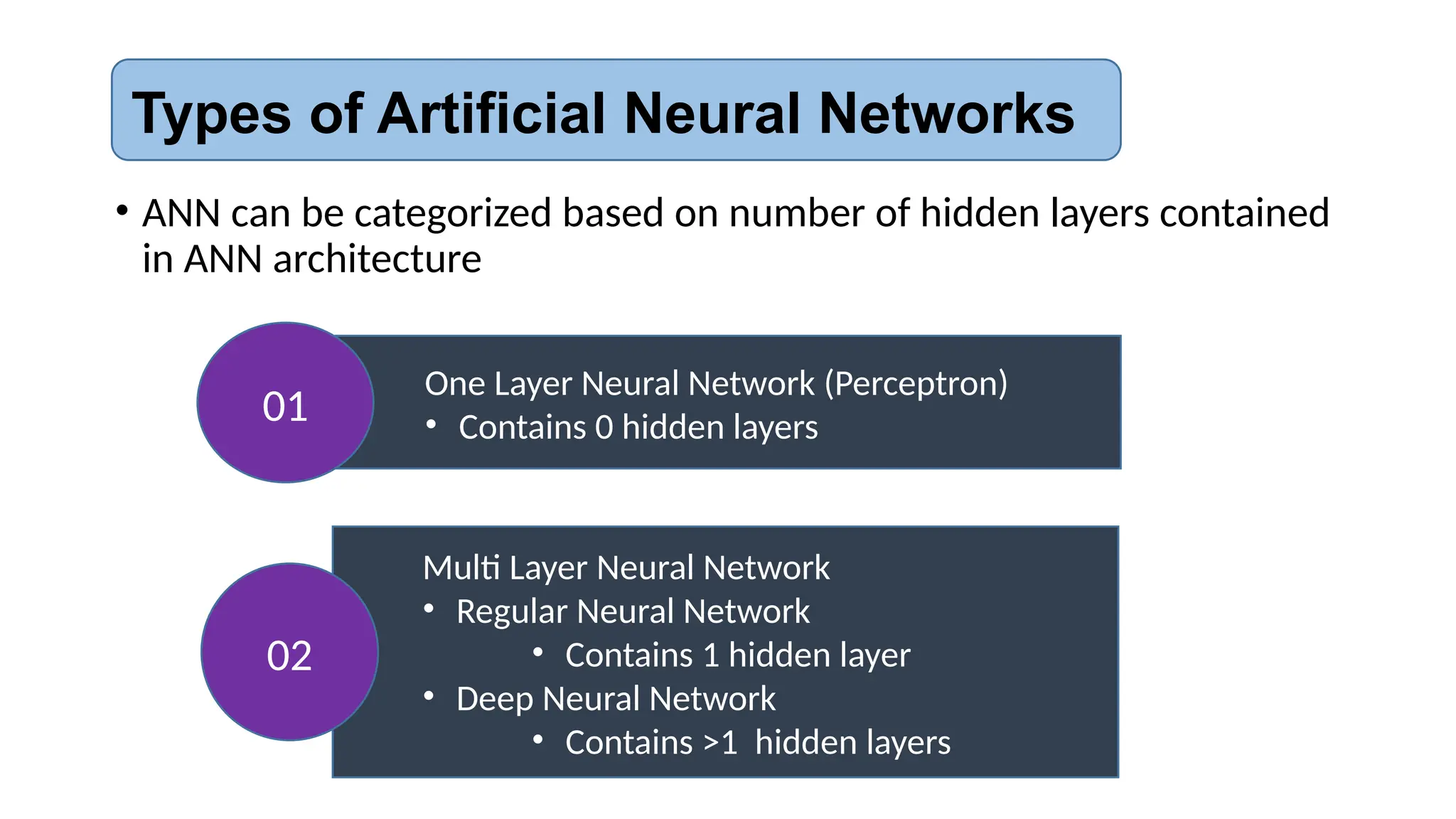
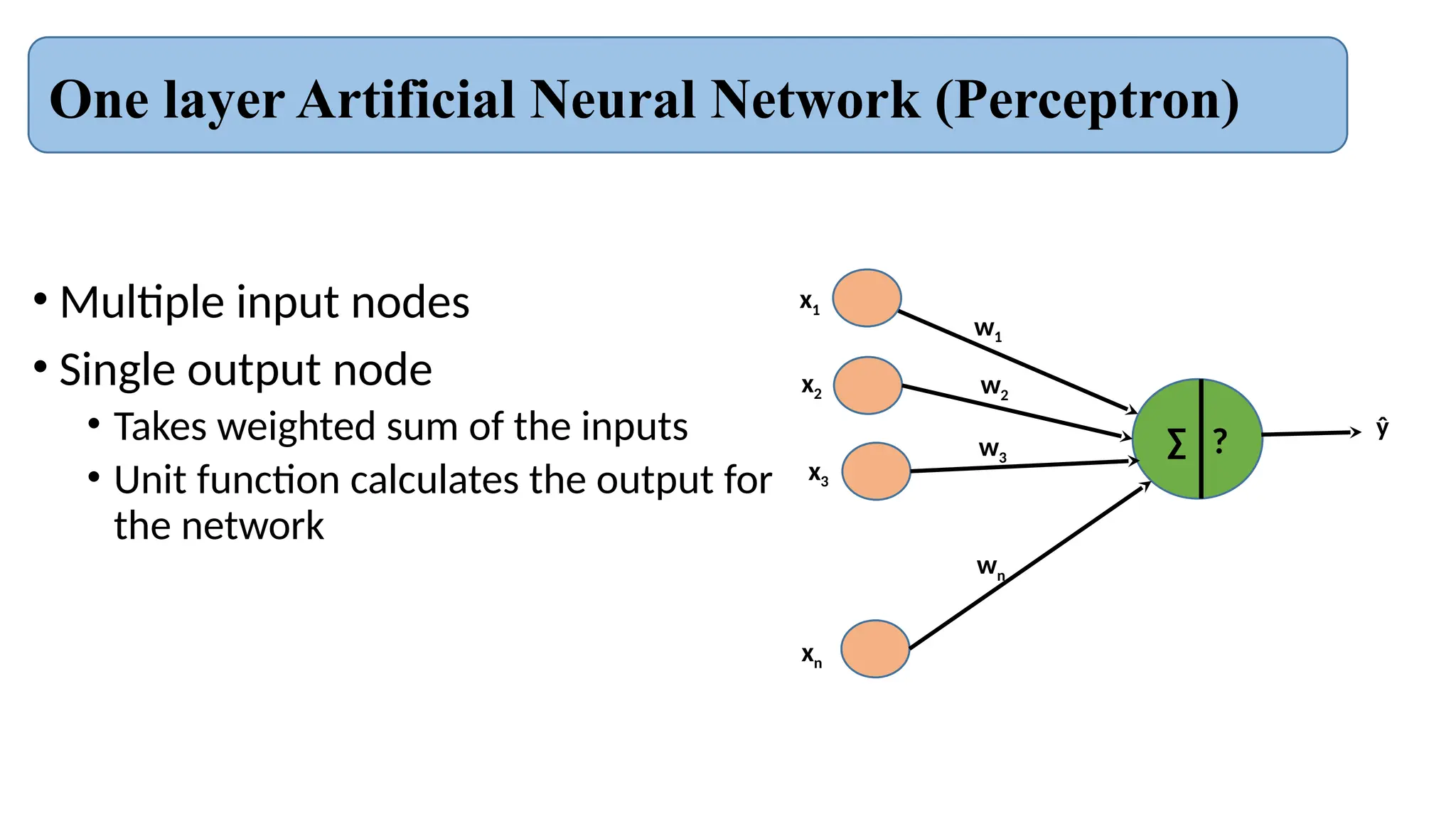
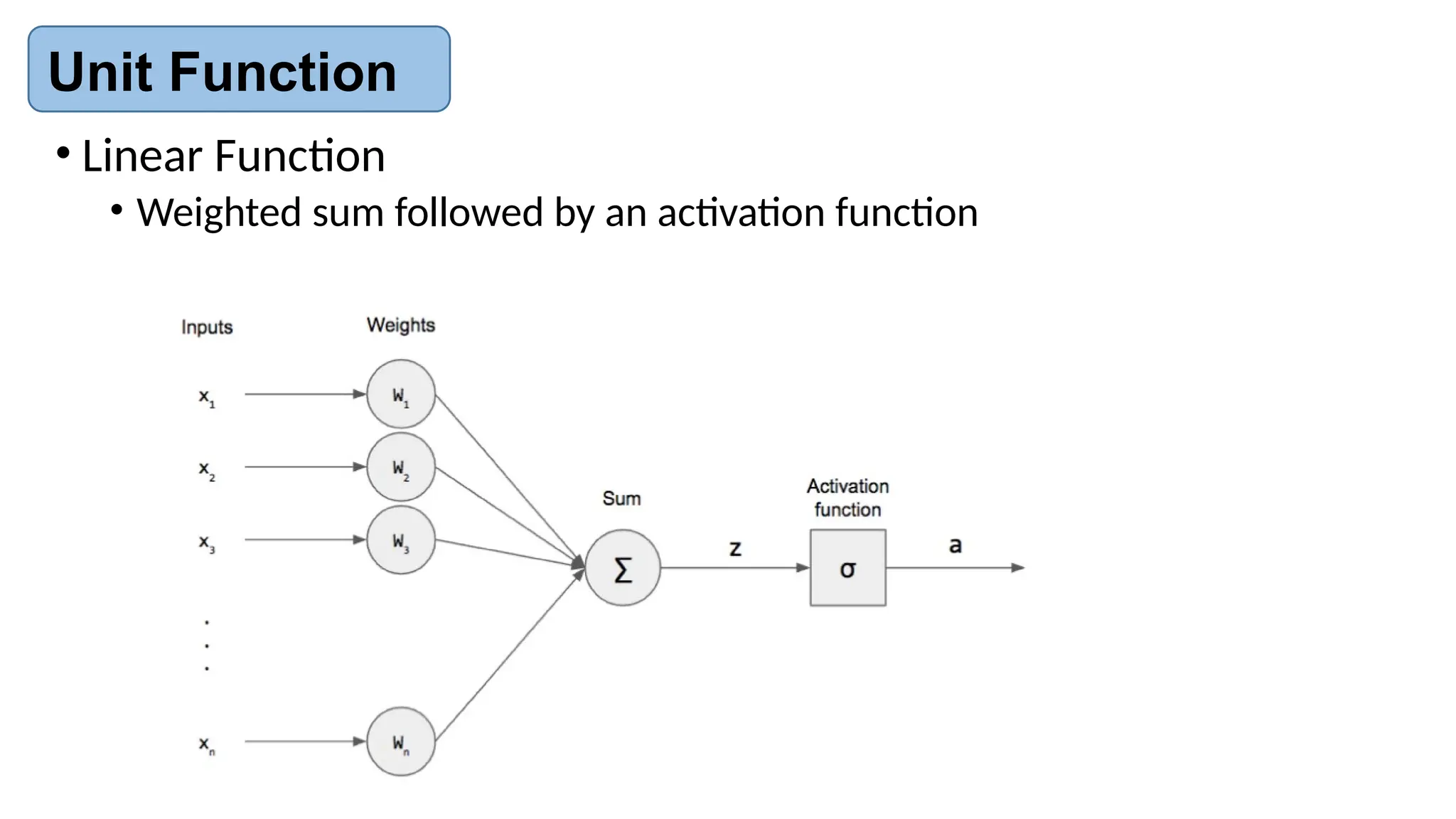
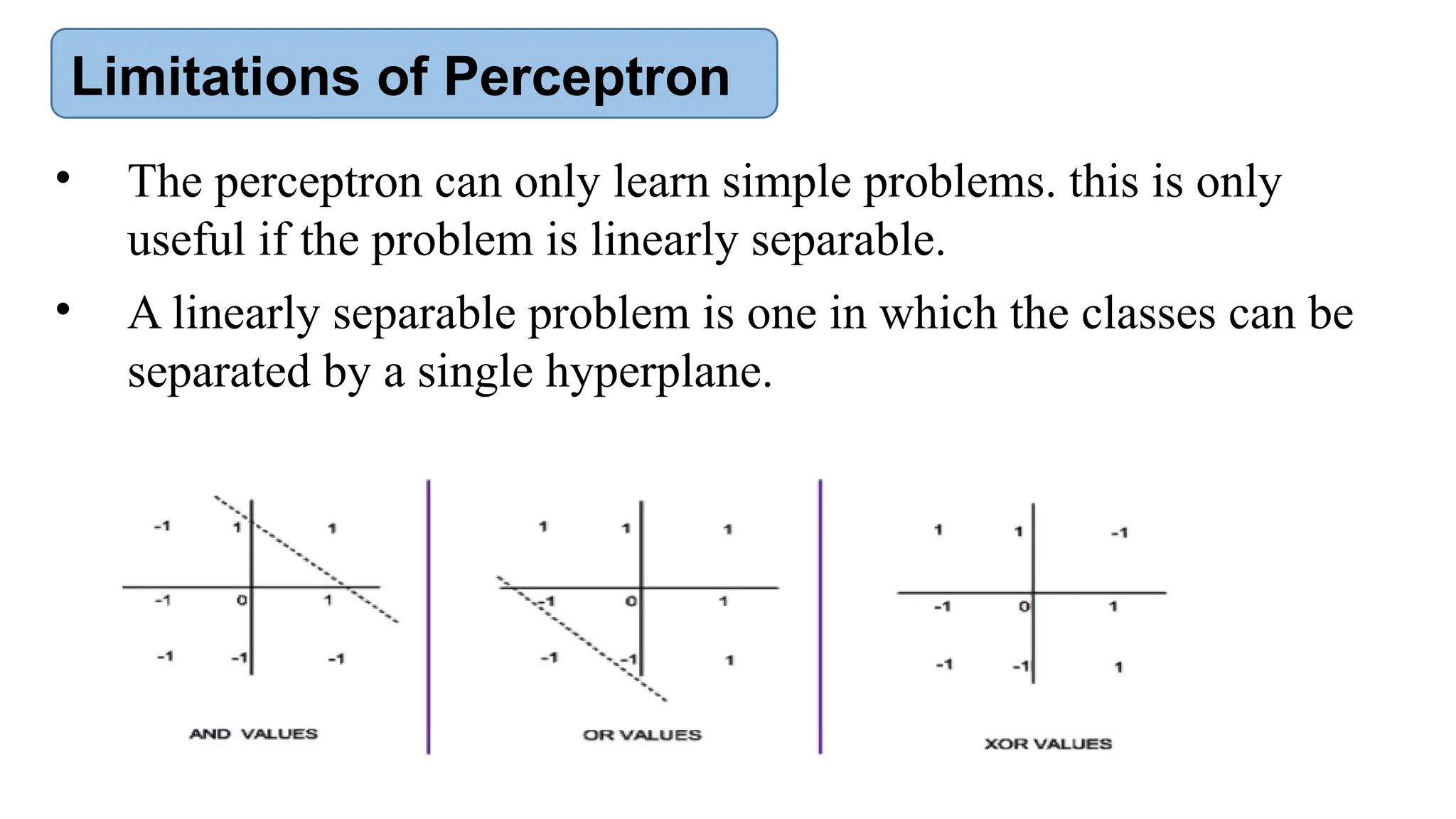
The document provides an introduction to neural networks, contrasting biological and artificial neurons and explaining key algorithms such as perceptron and backpropagation. It details the structure and functioning of single-layer and multi-layer neural networks, highlighting how weights are adjusted during training to improve predictions. The text also addresses the limitations of perceptrons, particularly their ability to only solve linearly separable problems.







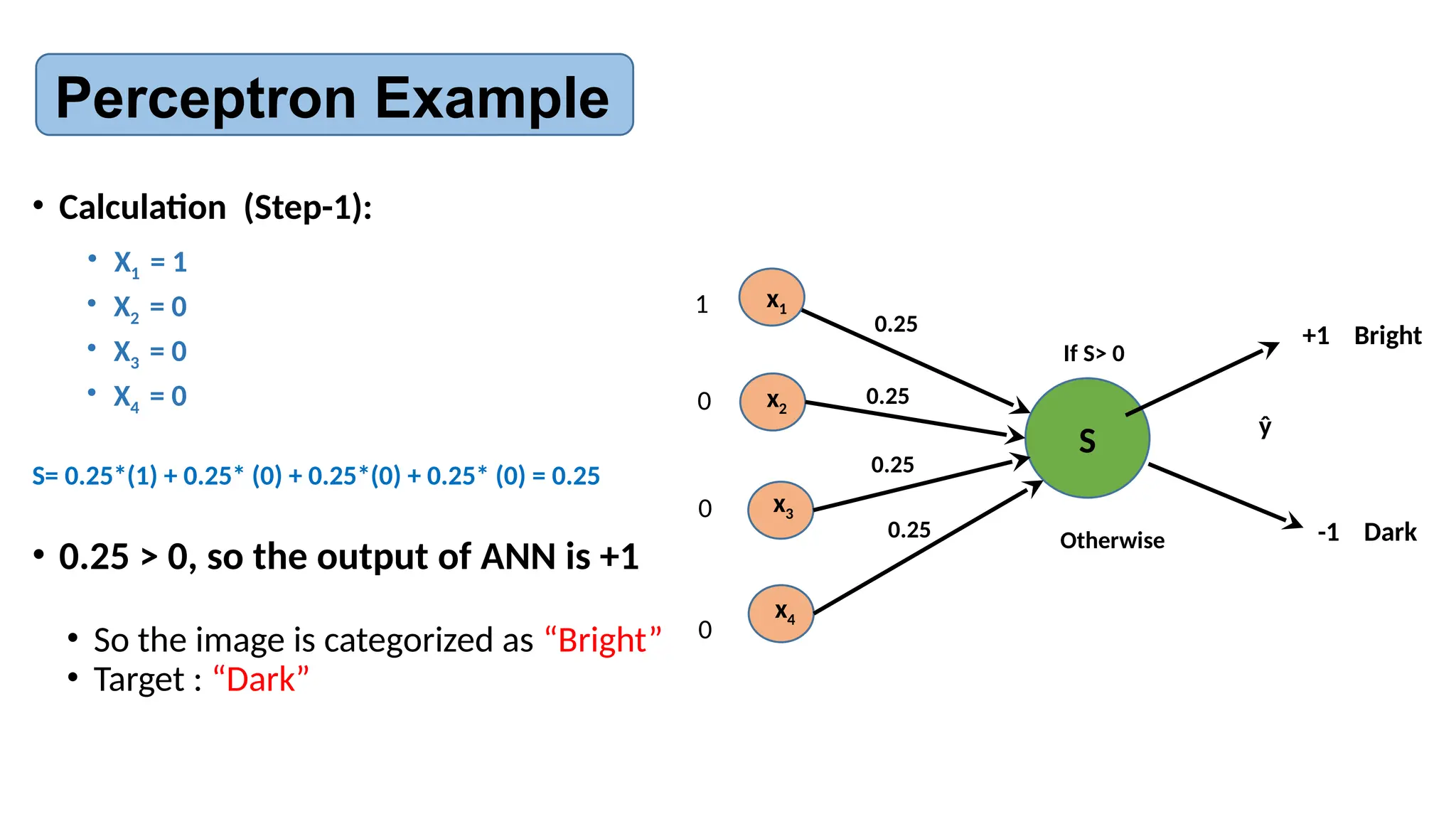






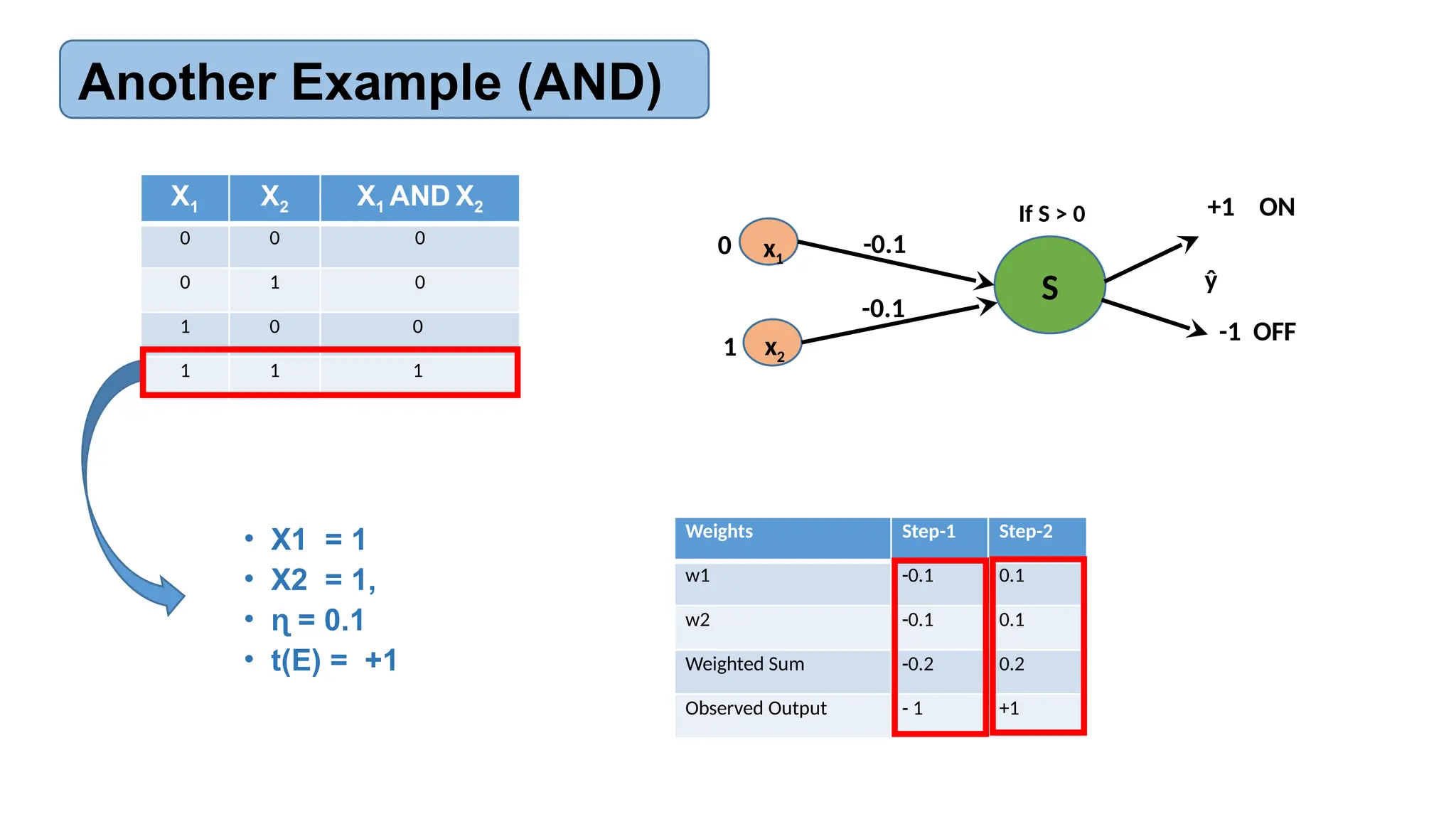
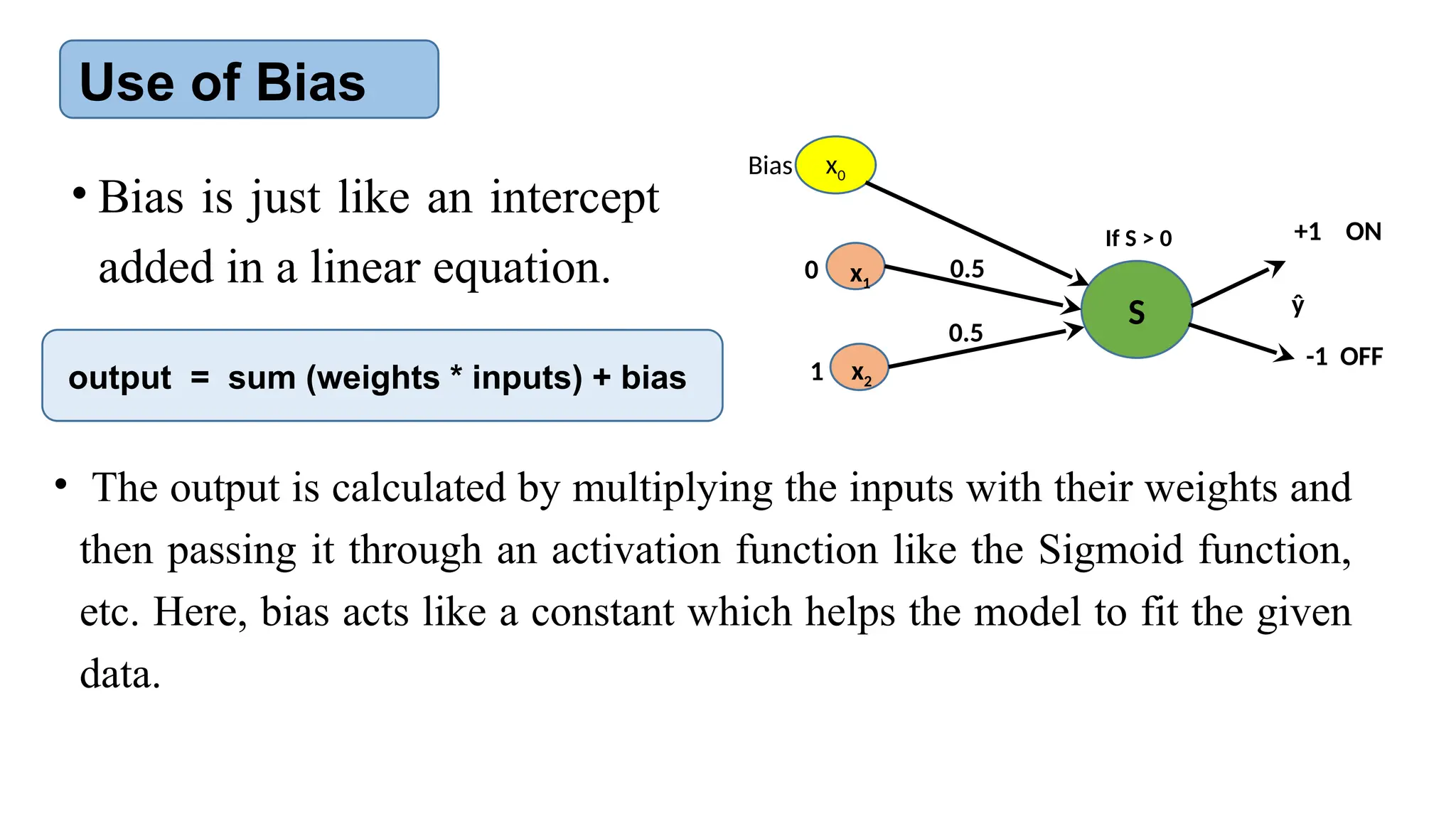

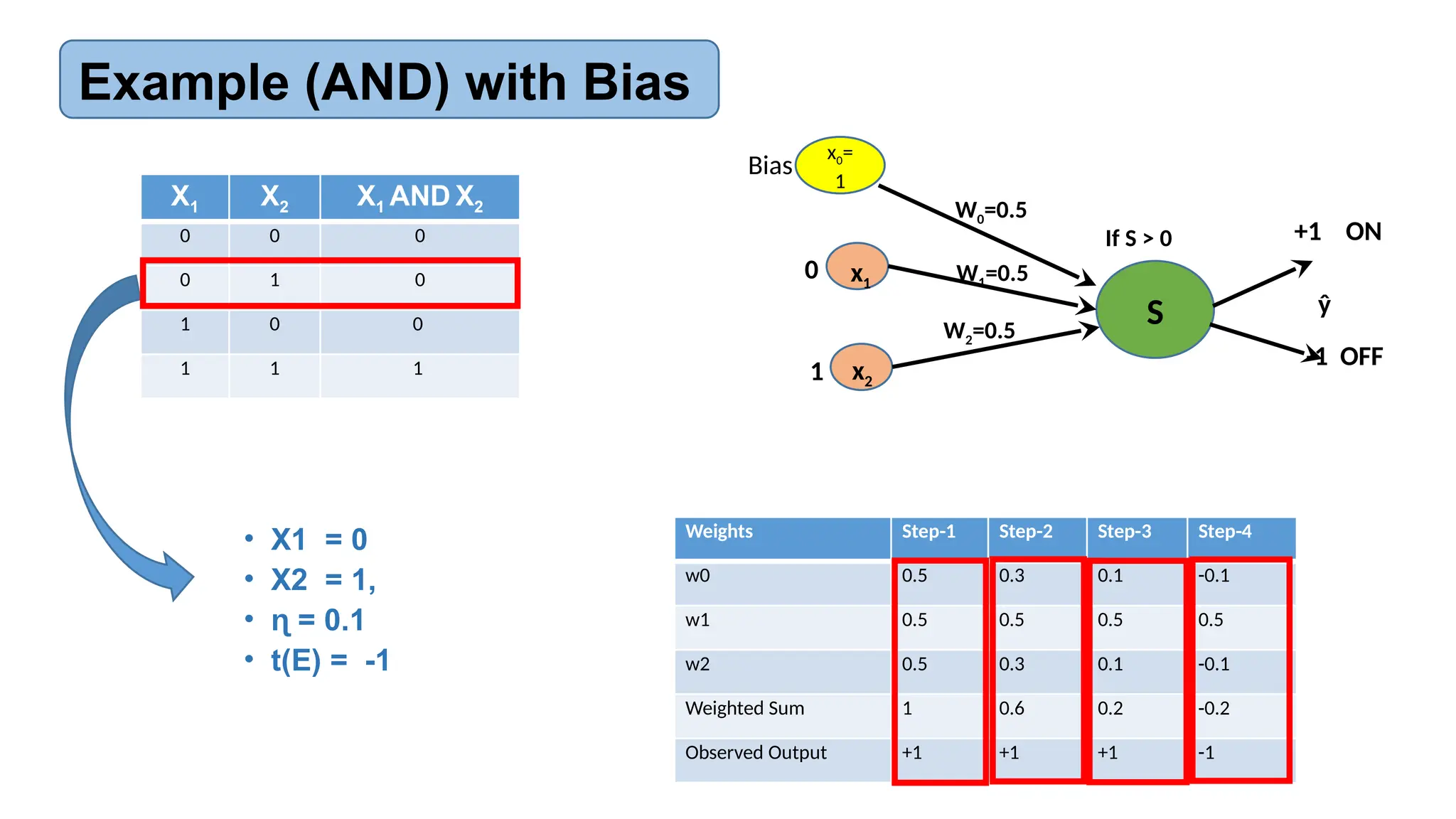

































![AI-Lecture-11[Neural Network] updated.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/ai-lecture-11neuralnetworkupdated-251220065329-186ba89b-thumbnail.jpg?width=640&height=640&fit=bounds)




























