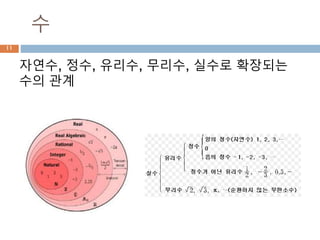
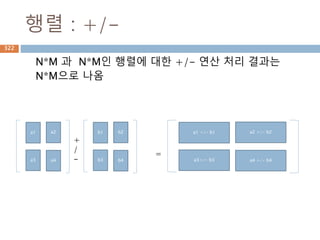
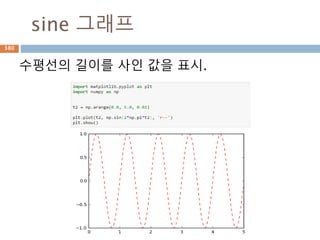
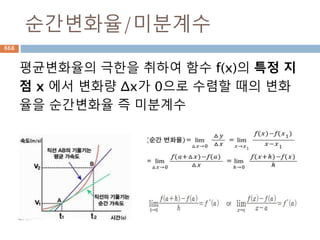
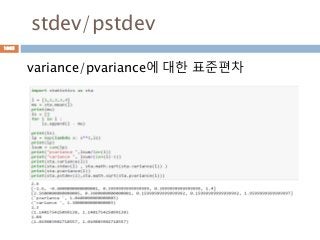
유리수
유리수(有理數, rational number)는두 정수의
분수 형태(단 분모는 반드시 0이 아니다)로 나타
낼 수 있는 실수를 말한다.
유리수는 (0으로 나누는 것을 제외한) 사칙연산
(덧셈, 뺄셈, 곱셈, 나눗셈)에 대해 닫혀있는 '최소
의' 집합이기도 하다
16
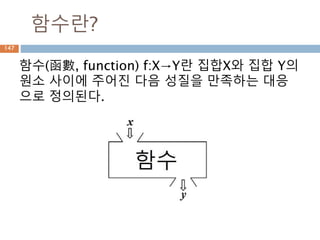
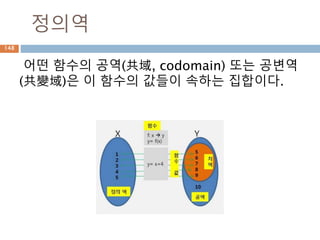
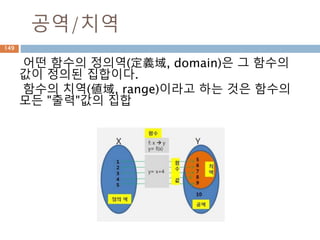
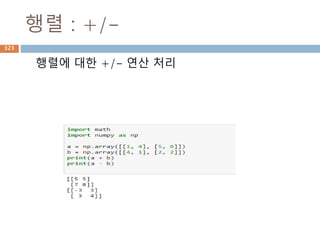
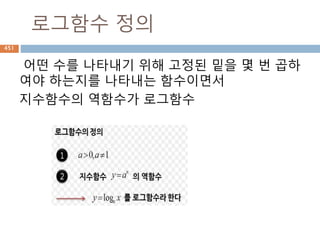
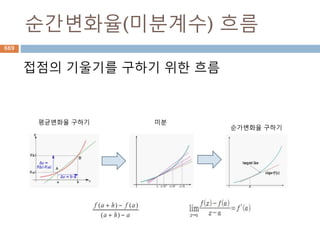
실수
실수 [實數, realnumber] 정수의 몫으로 정의되
는 유리수의 범위에서는 대소의 순서를 정할 수
있으며, 사칙연산을 자유로이 할 수 있다.
그러나 이 범위에서는 역시 불완전한 점이 많다.
이를테면, 단위의 길이를 가지는 정사각형의 대
각선의 길이(x=2의 근)는 유리수로 나타낼 수 없
다.
이와 같은 결함을 보완하기 위하여 유리수에 무
리수를 첨가하여 수의 범위를 실수까지 확장한
것이다.
20
복소수
복소수(複素數, complex number)는다음 꼴로
나타낼 수 있는 수 이다.
a+bi
이 때 a, b는 실수이고 i는 허수단위로 i2=-1을
만족한다. 실수 a를 그 복소수의 실수부, 실수 b
를 복소수의 허수부라고 부른다.
모든 실수는 복소수에 포함된다. 왜냐하면 모든
실수는 허수부가 0인 복소수로 표시할 수 있기 때
문이다.
22
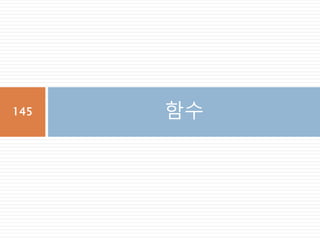
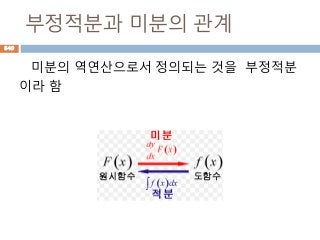
항등원
항등원(恒等元)은 집합의 어떤원소와 연산을 취
해도, 자기 자신이 되는 원소를 말한다. 쉽게 말해
서, 1개의 양을 전혀 달라 보이는 다른 양과 같게
만드는 수학적 관계를 말한다고 생각하면 된다.
25
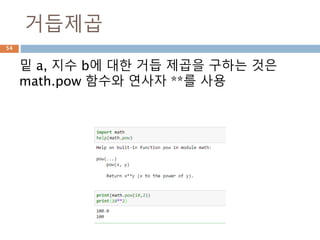
26.
반수: 덧셈
반수(反數)는 그수를 더했을 때 0이 되는 수를 말
한다. 예를 들면 7의 경우 -7에 7을 더하면 0이
되므로 7의 반수는 -7이다.
다르게 말하면 어떤 양수 n의 반수는 그와 절댓값
이 같은 음수라고 할 수 있으며 그 역도 성립한다.
정수, 유리수, 실수, 복소수는 음수가 있기 때문에
모두 반수가 있다.
26
27.
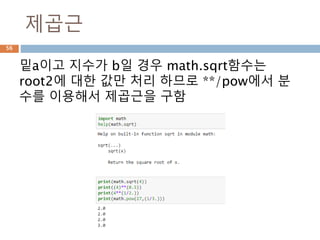
역수 : 곱셈
어떤수의 역수(逆數,reciprocal) 또는 곱셈 역원
(-逆元, 영어: multiplicative inverse)은 그 수와
곱해서 1, 즉 곱셈 항등원이 되는 수를 말한다.
x의 역수는 1/x 또는 x -1로 표기한다.
곱해서 1이 되는 두 수를 서로 역수
27
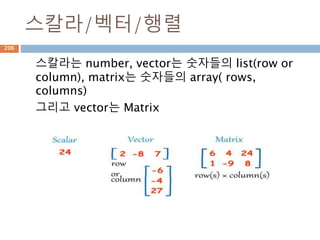
절댓값은 거리의 개념이므로반드시 0또는 양수이어야하며, 만약
실수 a가 음수라면, a에 (-1)을 곱해 양수화
절대값 absolute value
어떤 실수 a를 수직선에 대응시켰을 때, 수직선의
원점에서 실수 a까지의 거리를 의미한다. 이것을
기호로 |a|로 표시.
29
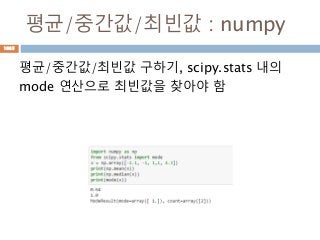
sympy 모듈 이란
SymPy는symbolic mathematics을위한
python 라이브러리입니다.
SymPy는 가능한 한 간단하게 코드를 유지하는
것은 이해하기 쉽게 확장 할 수있는 a full-
featured computer algebra system (CAS)처리
34
35.
sympy 구조
SymPy는 symbolicmathematics를 처리하기 위
해 다양한 객체들로 구성해서 평가해 수학처럼
문제를 푸는 체계
35
Sympy는 정의한 것은 pi도
하나의 인스턴스 객체 이므
로 이 값을 처리를 위해서는
평가(evalf)를 해야 함
36.
sympy 객체
Sympy객체를 변수에할당해서 사용하지만 별도
의 객체로 역할 함
36
Symbol로 정의할 때
들어간 문자열의 실
제 name이고 할당
된 참조변수는
symbol 객체가 할당
된 변수라 이름이 달
라도 됨
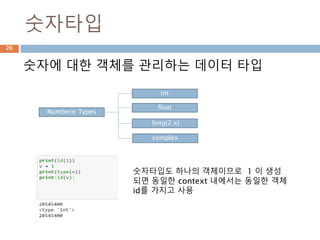
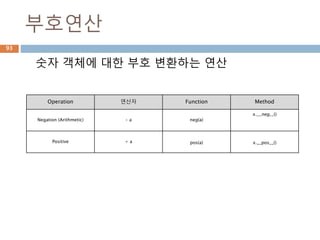
숫자타입
숫자에 대한 객체를관리하는 데이터 타입
Numberic Types
int
float
long(2.x)
complex
숫자타입도 하나의 객체이므로 1 이 생성
되면 동일한 context 내에서는 동일한 객체
id를 가지고 사용
58
59.
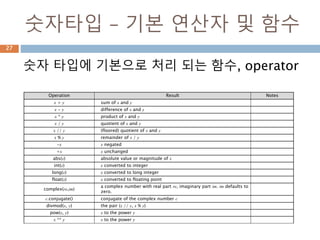
숫자타입 – 기본연산자 및 함수
숫자 타입에 기본으로 처리 되는 함수, operator
Operation Result Notes
x + y sum of x and y
x - y difference of x and y
x * y product of x and y
x / y quotient of x and y
x // y (floored) quotient of x and y
x % y remainder of x / y
-x x negated
+x x unchanged
abs(x) absolute value or magnitude of x
int(x) x converted to integer
long(x) x converted to long integer
float(x) x converted to floating point
complex(re,im)
a complex number with real part re, imaginary part im. im defaults to
zero.
c.conjugate() conjugate of the complex number c
divmod(x, y) the pair (x // y, x % y)
pow(x, y) x to the power y
x ** y x to the power y
59
숫자타입 – int예시
int 내부 속성에 대한 처리
real : int는 숫자를 관리하고
bit_length() : 이진수로 변환시
bit 길이
denominator : 분모
numerator : 분자
62
63.
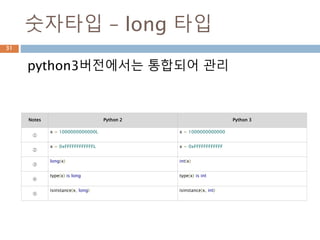
숫자타입 – long타입
python3버전에서는 통합되어 관리
Notes Python 2 Python 3
①
x = 1000000000000L x = 1000000000000
②
x = 0xFFFFFFFFFFFFL x = 0xFFFFFFFFFFFF
③
long(x) int(x)
④
type(x) is long type(x) is int
⑤
isinstance(x, long) isinstance(x, int)
63
숫자타입 – float예시
float 내부 속성에 대한 처리
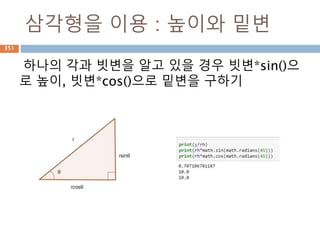
• real : float는 숫자를 관리하고
• hex() : 16진수로 변환
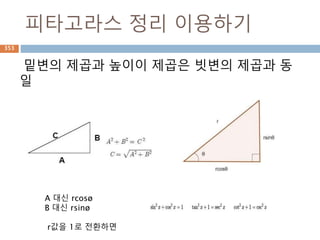
• fromhex() : hex() 결과의 문자
열을 float로 전환
• is_integer() : 실수 중 소수점 이
하 값이 0일 경우 true
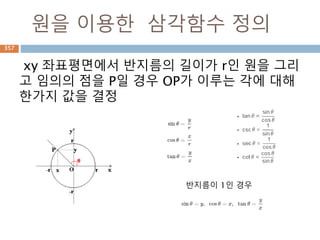
• as_integer_ratio() : 현재 값을
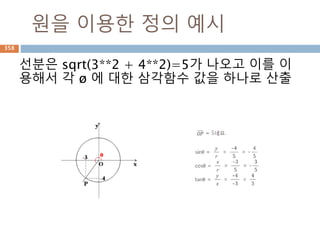
denominator : 분모,
numerator : 분자로 표시
66
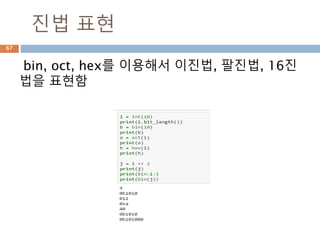
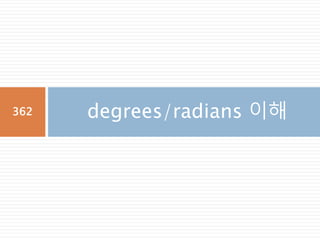
십육진법
십육진법(十六進法, hexadecimal)은 16을밑으로
하는 기수법이다. 보통 0부터 9까지의 수와 A에서 F
까지의 로마 문자를 사용하고, 이때 대소문자는 구별
하지 않는다. 이진법 표기의 4자리와 십육진법 한 자
리가 일대일 대응하며, 2진수가 많이 쓰이는 컴퓨터
에서 2진수를 대신해 많이 쓰이고 있다.
96
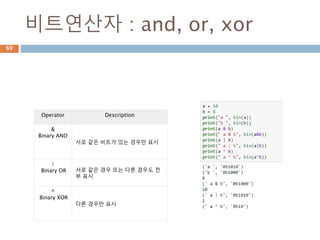
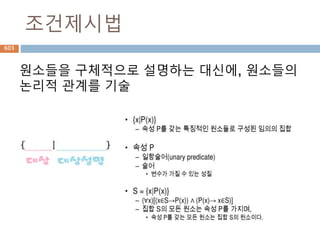
수학에서, 집합 S에 이항연산 * 이 정의되어 있을 때, S의 임의의
두 원소 a, b 에 대해
a * b = b * a가 성립하면, 이 연산은 교환법칙(交換法則,
commutative law)을 만족한다고 한다
교환법칙을 만족하는 연산의 예를 들어보면 다음과 같다.
유리수, 실수, 복소수에서 덧셈과 곱셈.
행렬, 벡터의 덧셈
집합의 교집합, 합집합 연산
교환법칙
수학에서 순서와 상관없이 다른 항을 바꿔 계산
해도 동일한 값이 나오는 법칙
107
108.
교환법칙 : 덧셈과곱셈
수학에서 순서와 상관없이 다른 항을 바꿔 계산
해도 동일한 값이 나오는 법칙
108
수학에서 결합법칙(結合 法則,associated law)은 한 식에서 연산
이 두 번 이상 연속될 때, 앞쪽의 연산을 먼저 계산한 값과 뒤쪽의
연산을 먼저 계산한 결과가 항상 같을 경우 그 연산은 결합법칙을
만족한다고 한다.
결합법칙을 만족하는 연산의 예를 들어보면 다음과 같다.
실수와 복소수, 사원수의 덧셈과 곱셈은 결합법칙이 성립한
다.
최대공약수와 최소공배수 함수는 결합법칙을 만족한다.
행렬 곱셈은 결합법칙을 만족한다.
결합법칙
연산이 두 번 이상 연속될 때 연산을 묶어서 처리
110
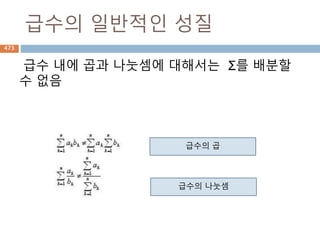
집합 S와 S에대해 닫혀있는 이항 연산 *가 정의되어 있을 때, S의
임의의 원소 a, b, c에 대해 a * (b + c) = (a * b) + (a * c)가 성립
하면 좌분배법칙이, (b + c) * a = (b * a) + (c * a)가 성립하면 우
분배법칙이 성립한다고 하며 양쪽모두 성립할 경우 집합 S에서 연
산 *에 대해 분배법칙이 성립한다고 한다.
분배법칙을 만족하는 연산의 예를 들어보면 다음과 같다.
임의의 자연수, 정수, 유리수, 실수, 복소수의 곱셈 ×은 덧
셈 +에 대해 분배법칙이 성립한다.
합집합 연산 ∪은 교집합 연산 ∩에 대해 분배법칙이 성립하
고, 교집합 연산 ∩은 합집합 연산 ∪에 대해 분배법칙이 성
립한다. 또한, 교집합 연산은 대칭자 연산에 대해 분배법칙
이 성립한다.
분배법칙
수학에서 이항연산 *와 묶음이 있을 경우 분배하
면 동일한 처리값이 나오는 법칙
113
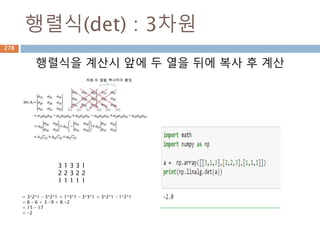
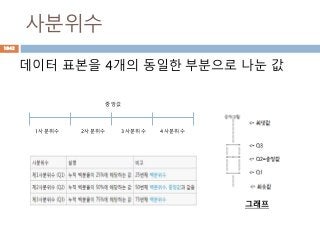
공약수/최대공약수
공약수, 최대공약수, 서로소용어 정의
공약수 두 개 또는 그 이상의 자연수가 있을 때 그 자연수들의 공통인 약수.
최대공약수 공약수들 중에서 가장 큰 수.12의 약수={1,2,3,6,12}
16의 약수={1,2,4,8,16}
18의 약수={1,2,3,6,9,18} 에서
12와 16의 공약수 → 1,2,4 → 최대공약수는 4
12, 16, 18의 공약수 → 1,2 → 최대공약수는 2
서로소 공약수가 1 하나 뿐인 두 자연수 사이의 관계
(예) 8의 약수={1,2,4,8}, 9의 약수={1,3,9}에서 8과 9의 공약수는 1 한 개
뿐이므로 8과 9는 서로소
116
117.
서로소
최대공약수가 1인, 둘이상의 양의 정수들은 서로
소(relatively prime)이라고 불린다.
두 정수가 1 이외에 양의 공약수를 가지지 않으면
서로소이다.
117
연산자와 special method
python문법의 연산자는 각 type class 내부에 대
응하믄 special method가 존재
연산자
Special
Method
각 타입별로 연산자는
special method와 매칭
124
125.
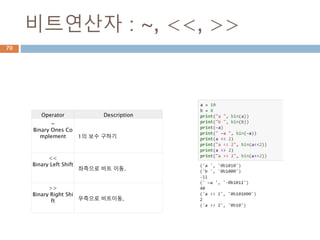
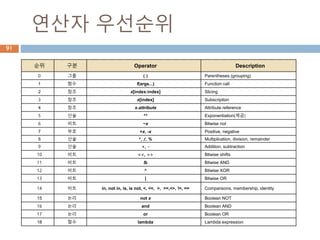
연산자 우선순위
순위 구분Operator Description
0 그룹 ( ) Parentheses (grouping)
1 함수 f(args...) Function call
2 참조 x[index:index] Slicing
3 참조 x[index] Subscription
4 참조 x.attribute Attribute reference
5 산술 ** Exponentiation(제곱)
6 비트 ~x Bitwise not
7 부호 +x, -x Positive, negative
8 산술 *, /, % Multiplication, division, remainder
9 산술 +, - Addition, subtraction
10 비트 <<, >> Bitwise shifts
11 비트 & Bitwise AND
12 비트 ^ Bitwise XOR
13 비트 | Bitwise OR
14 비트 in, not in, is, is not, <, <=, >, >=,<>, !=, == Comparisons, membership, identity
15 논리 not x Boolean NOT
16 논리 and Boolean AND
17 논리 or Boolean OR
18 함수 lambda Lambda expression
125
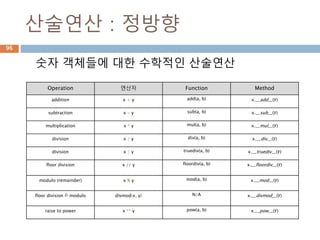
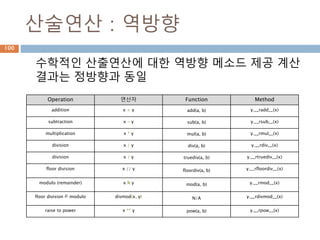
산술연산 : 정방향
숫자객체들에 대한 수학적인 산술연산
Operation 연산자 Function Method
addition x + y add(a, b) x.__add__(y)
subtraction x - y sub(a, b) x.__sub__(y)
multiplication x * y mul(a, b) x.__mul__(y)
division x / y div(a, b) x.__div__(y)
division x / y truediv(a, b) x.__truediv__(y)
floor division x // y floordiv(a, b) x.__floordiv__(y)
modulo (remainder) x % y mod(a, b) x.__mod__(y)
floor division & modulo divmod(x, y) N/A x.__divmod__(y)
raise to power x ** y pow(a, b) x.__pow__(y)
130
산술연산 : 역방향
수학적인산출연산에 대한 역방향 메소드 제공 계산
결과는 정방향과 동일
Operation 연산자 Function Method
addition x + y add(a, b) y.__radd__(x)
subtraction x - y sub(a, b) y.__rsub__(x)
multiplication x * y mul(a, b) y.__rmul__(x)
division x / y div(a, b) y.__rdiv__(x)
division x / y truediv(a, b) y.__rtruediv__(x)
floor division x // y floordiv(a, b) y.__rfloordiv__(x)
modulo (remainder) x % y mod(a, b) y.__rmod__(x)
floor division & modulo divmod(x, y) N/A y.__rdivmod__(x)
raise to power x ** y pow(a, b) y.__rpow__(x)
134
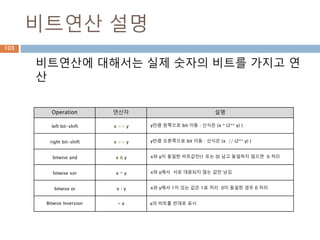
비트연산 설명
비트연산에 대해서는실제 숫자의 비트를 가지고 연
산
Operation 연산자 설명
left bit-shift x << y y만큼 왼쪽으로 bit 이동 : 산식은 (x * (2** y) )
right bit-shift x >> y y만큼 오른쪽으로 bit 이동 : 산식은 (x // (2** y) )
bitwise and x & y x와 y이 동일한 비트값만(1 또는 0) 남고 동일하지 않으면 0 처리
bitwise xor x ^ y x와 y에서 서로 대응되지 않는 값만 남김
bitwise or x | y x와 y에서 1이 있는 값은 1로 처리 0이 동일한 경우 0 처리
Bitwise Inversion ~ a a의 비트를 반대로 표시
137
138.
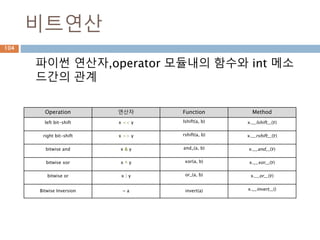
비트연산
python 연산자,operator 모듈내의함수와 int 메소
드간의 관계
Operation 연산자 Function Method
left bit-shift x << y lshift(a, b) x.__lshift__(y)
right bit-shift x >> y rshift(a, b) x.__rshift__(y)
bitwise and x & y and_(a, b) x.__and__(y)
bitwise xor x ^ y xor(a, b) x.__xor__(y)
bitwise or x | y or_(a, b) x.__or__(y)
Bitwise Inversion ~ a invert(a) x.__invert__()
138
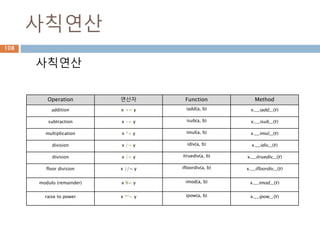
사칙연산
사칙연산
Operation 연산자 FunctionMethod
addition x += y iadd(a, b) x.__iadd__(y)
subtraction x -= y isub(a, b) x.__isub__(y)
multiplication x *= y imul(a, b) x.__imul__(y)
division x /= y idiv(a, b) x.__idiv__(y)
division x /= y itruediv(a, b) x.__itruediv__(y)
floor division x //= y ifloordiv(a, b) x.__ifloordiv__(y)
modulo (remainder) x %= y imod(a, b) x.__imod__(y)
raise to power x **= y ipow(a, b) x.__ipow__(y)
142
143.
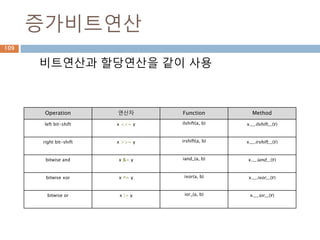
증가비트연산
비트연산과 할당연산을 같이사용
Operation 연산자 Function Method
left bit-shift x <<= y ilshift(a, b) x.__ilshift__(y)
right bit-shift x >>= y irshift(a, b) x.__irshift__(y)
bitwise and x &= y iand_(a, b) x.__iand__(y)
bitwise xor x ^= y ixor(a, b) x.__ixor__(y)
bitwise or x |= y ior_(a, b) x.__ior__(y)
143
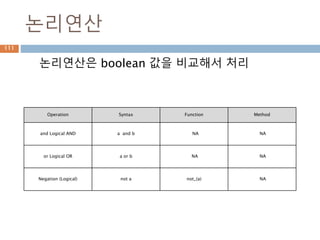
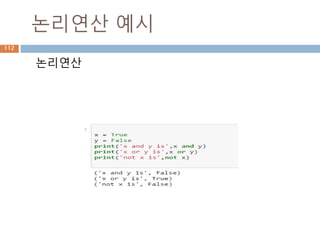
논리연산
논리연산은 boolean 값을비교해서 처리
Operation Syntax Function Method
and Logical AND a and b NA NA
or Logical OR a or b NA NA
Negation (Logical) not a not_(a) NA
145
방정식
방정식(方程式, equation)은 식에있는 특정한 문
자의 값에 따라 참/거짓이 결정되는 등식이다.
이때, 방정식을 참이 되게 하는 특정 문자의 값을
해 또는 근이라 한다.
149
항등식
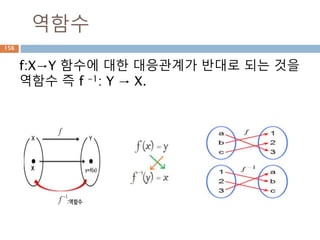
방정식 X의 해는 2,3
150.
상수항
상수항은 다항식이나 방정식에서변수 또는 미지
수를 포함하지 않은 항이다.
예를 들면, 다항식 a0xn+a1xn-1+…+an-1x+an
에서는 변수 x를 포함하지 않은 항 an을, 또 방정
식 a0xn+a1xn-1+…+an-1x+an=0에서는 미지
수 x를 포함하지 않은 항 an을 상수항이라 한다.
150
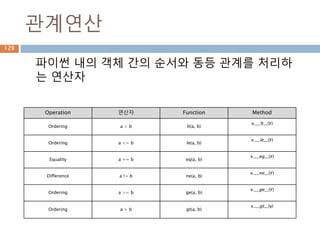
관계연산
python 내의 객체간의 순서와 동등 관계를 처리하
는 연산자
Operation 연산자 Function Method
Ordering a < b lt(a, b)
x.__lt__(y)
Ordering a <= b le(a, b)
x.__le__(y)
Equality a == b eq(a, b)
x.__eq__(y)
Difference a != b ne(a, b)
x.__ne__(y)
Ordering a >= b ge(a, b)
x.__ge__(y)
Ordering a > b gt(a, b)
x.__gt__(y)
169
이항정리 : 전개
다항식(a+b)3의 전개식에서 각 항의 계수를 조
합의 수를 이용하여 나타내는 방법
(a+b)3=(a+b)(a+b)(a+b)
=aaa+aab+aba+abb+baa+bab+bba+bbb
=a3+3a2b+3ab2+b3
=a3+3C1a2b+3C2ab2+b3
3C1 = 3P1/1! = 3!/2!/1! = 3
3C2 = 3P2/2! = 3!/1!/2! = 3
181
182.
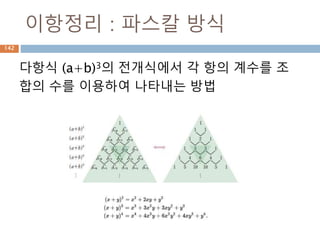
이항정리 : 파스칼방식
다항식 (a+b)3의 전개식에서 각 항의 계수를 조
합의 수를 이용하여 나타내는 방법
182
factor 함수 :modulus
인수분해를 위한 파라미터를 modulus로 사용하
면 인수분해 불가함 방정식을 조건에 따라 인수
분해 함
188
189.
factor 함수 :가우시안정수
가우스정수(Gauß整數, Gaussian integer)는 실
수부와 허수부가 모두 정수인 수이다.
(a+bi)(a-bi)=a2+b2 로 표현이 가능한 수
189
= (0+i)(0 –i)
= -i*I
= -(i)**2
= 1
X**2+1은 인수분
해가 안되어서 가
우시안 수로 인수
분해
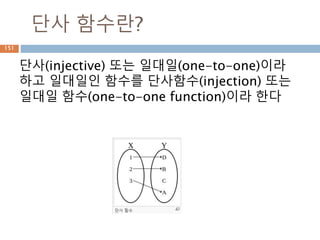
단사 함수란?
단사(injective) 또는일대일(one-to-one)이라
하고 일대일인 함수를 단사함수(injection) 또는
일대일 함수(one-to-one function)이라 한다
199
200.
전사 함수란?
공역의 모든원소에게 정의역의 적어도 하나의 원소
를 대응시킨다면(즉, 치역이 공역과 같다면) 전사
(surjective) 또는 X에서 Y 로(onto)의 함수라 한다.
전사인 함수를 전사함수(surjection)이라 한다.
200
201.
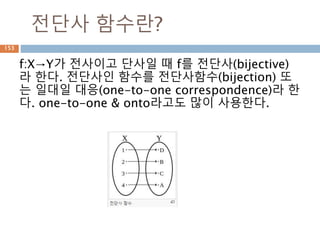
전단사 함수란?
f:X→Y가 전사이고단사일 때 f를 전단사(bijective)
라 한다. 전단사인 함수를 전단사함수(bijection) 또
는 일대일 대응(one-to-one correspondence)라 한
다. one-to-one & onto라고도 많이 사용한다.
201
202.
초월함수
초월함수(超越函數)란 대수함수와 대조적으로,
계수만으로이루어진 다항식을 만족시키지 않는
함수이다.
초월함수란 유한한 가감승제의 대수 연산으로 표
현할 수 없기 때문에 대수적인 것을 초월하는 함
수이다.
초월함수의 예로 로그함수, 삼각함수 등이 있다.
202
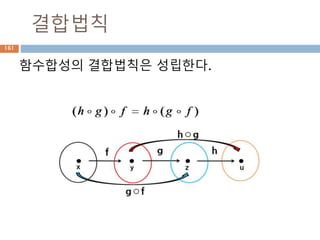
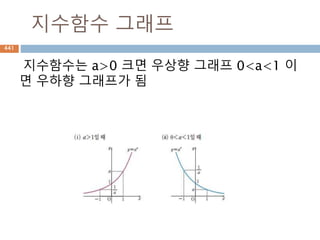
함수합성 function composition
함수의합성(函數의合成, function composition)은
한 함수의 공역이 다른 함수의 정의역과 일치하는 경
우 두 함수를 이어 하나의 함수로 만드는 연산이다.
이렇게 얻어진 함수를 합성 함수(合成函數
composite function)라고 한다.
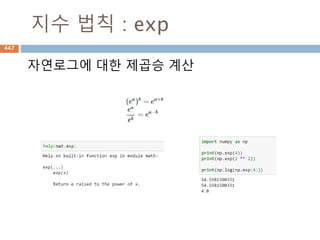
207
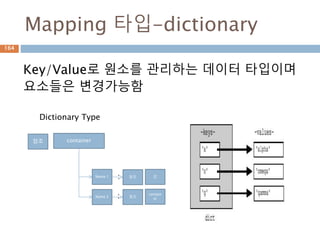
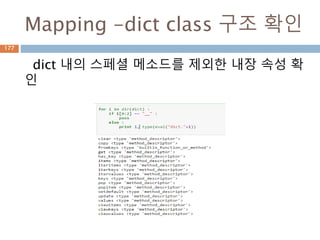
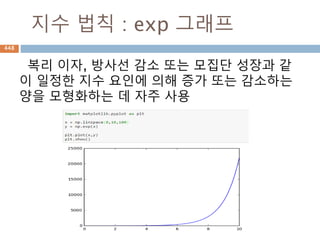
Mapping– dict 지원내장함수
Dictionary 타입에 원소 하나만 삭제, 원소들을
삭제, dictionary instance 삭제
Function Description
cmp(dict1, dict2) Compares elements of both dict.
len(dict) Gives the total length of the dictionary. This would be equal
to the number of items in the dictionary.
str(dict) Produces a printable string representation of a dictionary
type(dict) Returns the type of the passed variable. If passed variable is
dictionary, then it would return a dictionary type.
dict(mapping) Converts a map into list.
224
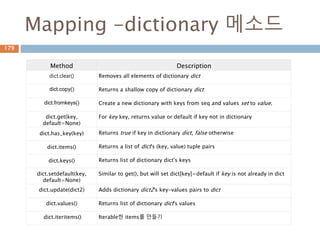
Mapping -dictionary 메소드
MethodDescription
dict.clear() Removes all elements of dictionary dict
dict.copy() Returns a shallow copy of dictionary dict
dict.fromkeys() Create a new dictionary with keys from seq and values set to value.
dict.get(key,
default=None)
For key key, returns value or default if key not in dictionary
dict.has_key(key) Returns true if key in dictionary dict, false otherwise
dict.items() Returns a list of dict's (key, value) tuple pairs
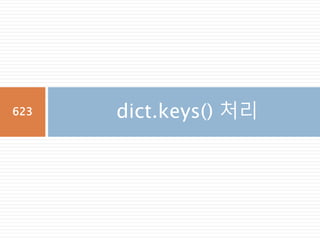
dict.keys() Returns list of dictionary dict's keys
dict.setdefault(key,
default=None)
Similar to get(), but will set dict[key]=default if key is not already in dict
dict.update(dict2) Adds dictionary dict2's key-values pairs to dict
dict.values() Returns list of dictionary dict's values
dict.iteritems() Iterable한 items를 만들기
227
228.
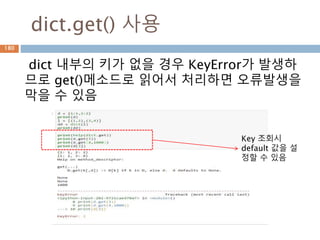
dict.get() 사용
dict 내부의키가 없을 경우 KeyError가 발생하
므로 get()메소드로 읽어서 처리하면 오류발생을
막을 수 있음
Key 조회시
default 값을 설
정할 수 있음
228
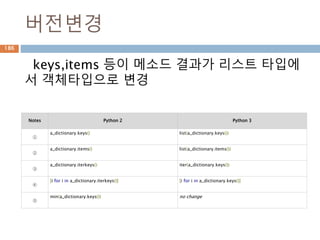
버전변경
keys,items 등이 메소드결과가 리스트 타입에
서 객체타입으로 변경
Notes Python 2 Python 3
①
a_dictionary.keys() list(a_dictionary.keys())
②
a_dictionary.items() list(a_dictionary.items())
③
a_dictionary.iterkeys() iter(a_dictionary.keys())
④
[i for i in a_dictionary.iterkeys()] [i for i in a_dictionary.keys()]
⑤
min(a_dictionary.keys()) no change
234
235.
메소드 결과 타입변경
keys, values, items 메소드 리턴타입이 list에
서 dict 타입으로 변경
235
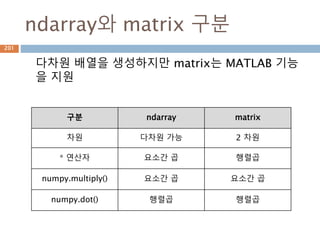
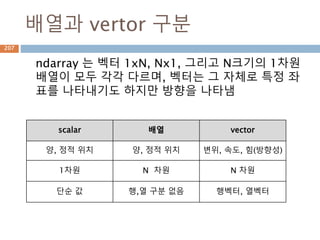
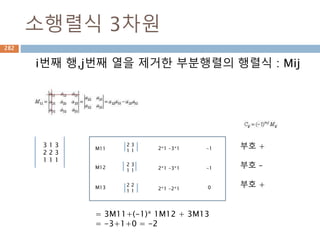
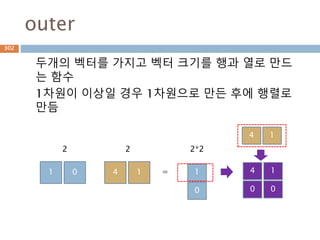
배열과 vertor 구분
ndarray는 벡터 1xN, Nx1, 그리고 N크기의 1차원
배열이 모두 각각 다르며, 벡터는 그 자체로 특정 좌
표를 나타내기도 하지만 방향을 나타냄
scalar 배열 vector
양, 정적 위치 양, 정적 위치 변위, 속도, 힘(방향성)
1차원 N 차원 N 차원
단순 값 행,열 구분 없음 행벡터, 열벡터
282
벡터: +
The vector(8,13) and the vector (26,7) add up to
the vector (34,20)
Example: add the vectors a = (8,13) and b = (26,7)
c = a + b
c = (8,13) + (26,7) = (8+26,13+7) = (34,20)
a
b
a
b
c
292
293.
Vector 연산: +
두벡터 평행 이동해 평행사변형을 만든 후 가운데
벡터가 실제 덧셈한 벡터를 표시
e
d
f
e
d
293
294.
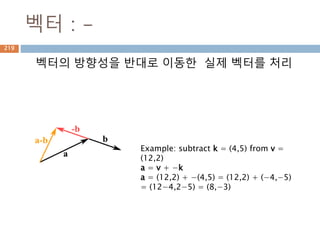
벡터 : -
벡터의방향성을 반대로 이동한 실제 벡터를 처리
Example: subtract k = (4,5) from v =
(12,2)
a = v + −k
a = (12,2) + −(4,5) = (12,2) + (−4,−5)
= (12−4,2−5) = (8,−3)
294
295.
Vector 연산: -
두벡터 반대 방향으로 평행 이동해 평행사변형을
만든 후 가운데 벡터가 실제 덧셈한 벡터를 표시
e
d
g
-e
-e
295
296.
벡터: 스칼라곱
벡터의 각원소에 스칼라값만큼 곱하여 표시
벡터 m = [7,3]
A = 3m= [21,9]
296
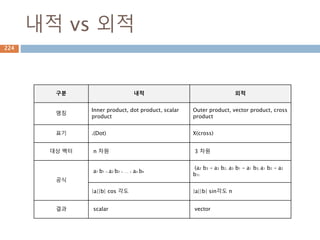
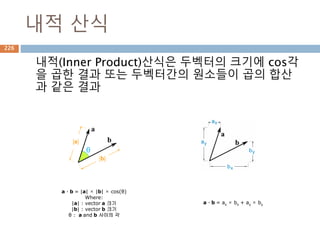
내적 산식
내적(Inner Product)산식은두벡터의 크기에 cos각
을 곱한 결과 또는 두벡터간의 원소들이 곱의 합산
과 같은 결과
a · b = |a| × |b| × cos(θ)
Where:
|a| : vector a 크기
|b| : vector b 크기
θ : a and b 사이의 각
a · b = ax × bx + ay × by
302
303.
내적 수학적 예시: 2 차원
두벡터에 내적 연산에 대한 수학적 처리 예시
a · b = |a| × |b| × cos(θ)
a · b = 10 × 13 × cos(59.5°)
a · b = 10 × 13 × 0.5075...
a · b = 65.98... = 66 (rounded)
a · b = ax × bx + ay × by
a · b = -6 × 5 + 8 × 12
a · b = -30 + 96
a · b = 66
303
304.
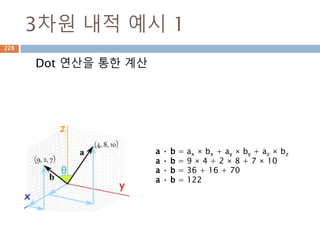
3차원 내적 예시1
Dot 연산을 통한 계산
a · b = ax × bx + ay × by + az × bz
a · b = 9 × 4 + 2 × 8 + 7 × 10
a · b = 36 + 16 + 70
a · b = 122
304
305.
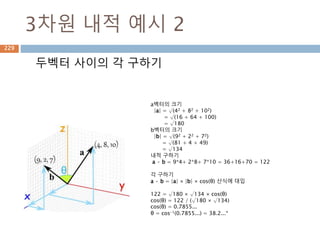
3차원 내적 예시2
두벡터 사이의 각 구하기
a벡터의 크기
|a| = √(42 + 82 + 102)
= √(16 + 64 + 100)
= √180
b벡터의 크기
|b| = √(92 + 22 + 72)
= √(81 + 4 + 49)
= √134
내적 구하기
a · b = 9*4+ 2*8+ 7*10 = 36+16+70 = 122
각 구하기
a · b = |a| × |b| × cos(θ) 산식에 대입
122 = √180 × √134 × cos(θ)
cos(θ) = 122 / (√180 × √134)
cos(θ) = 0.7855...
θ = cos-1(0.7855...) = 38.2...°
305
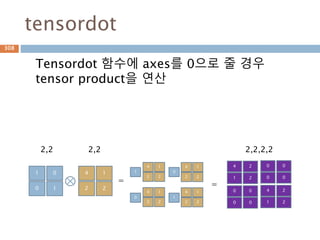
306.
내적(dot) 예시
두벡터에 대한내적(dot) 연산은 같은 위치의 원
소를 곱해서 합산함
두벡터의 곱셈은 단순히 원소를 곱해서 벡터를
유지
306
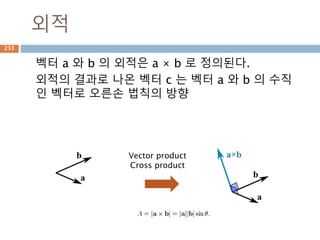
외적
벡터 a 와b 의 외적은 a × b 로 정의된다.
외적의 결과로 나온 벡터 c 는 벡터 a 와 b 의 수직
인 벡터로 오른손 법칙의 방향
Vector product
Cross product
309
310.
외적 산식 :2차원
벡터의 원소간의 cross 적을 처리
v = [a1,a2]
u = [b1,b2]
a1 a2
b1 b2
a1*b2 – a2*b1 Example: The cross product of a = (2,3) and b = (5,6)
c = a1b2 − a2b1 = 2×6− 3×5 = −3
Answer: a × b = -3
310
311.
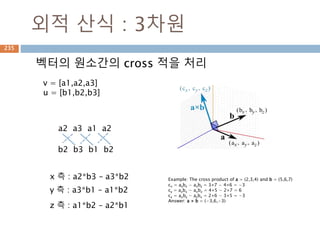
외적 산식 :3차원
벡터의 원소간의 cross 적을 처리
v = [a1,a2,a3]
u = [b1,b2,b3]
a2 a3 a1 a2
b2 b3 b1 b2
x 축 : a2*b3 – a3*b2
y 축 : a3*b1 – a1*b2
z 축 : a1*b2 – a2*b1
Example: The cross product of a = (2,3,4) and b = (5,6,7)
cx = aybz − azby = 3×7 − 4×6 = −3
cy = azbx − axbz = 4×5 − 2×7 = 6
cz = axby − aybx = 2×6 − 3×5 = −3
Answer: a × b = (−3,6,−3)
311
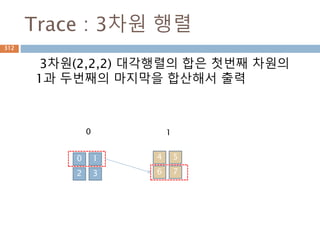
312.
외적 산식예시
두벡터에 대한외적(cross) 연산은 다른 위치의
원소를 곱해서 뺄셈
2차원 벡터는 스칼라 값으로 나옴 3차원 벡터이
상 표시 됨
312
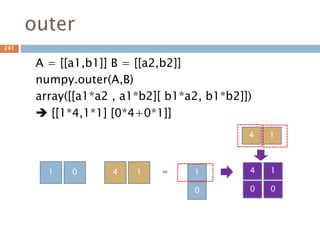
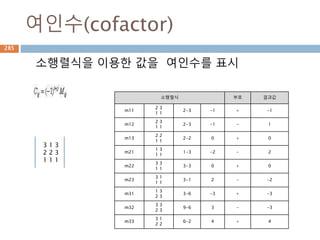
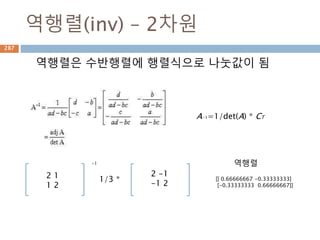
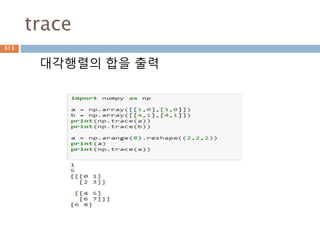
항등행렬
모든 행렬과 닷연산시 자기 자신이 나오게 하는
단위행렬
import numpy as np
a = np.array([[1,0],[0,1]])
b = np.array([[4,1],[3,2]])
print(np.dot(b,a))
print(np.dot(a,b))
[[4 1]
[3 2]]
[[4 1]
[3 2]]
336
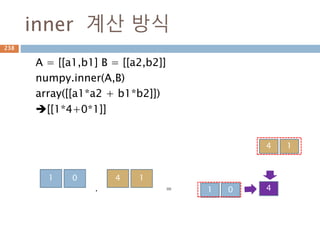
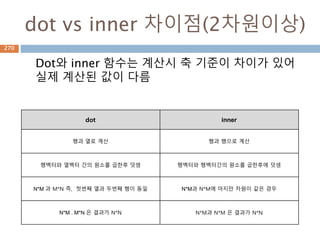
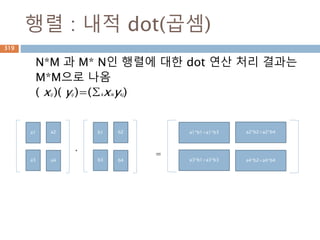
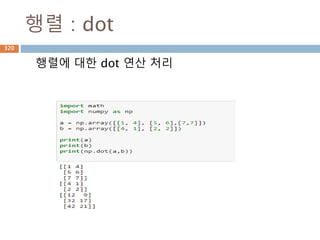
dot vs inner차이점(2차원이상)
Dot와 inner 함수는 계산시 축 기준이 차이가 있어
실제 계산된 값이 다름
dot inner
행과 열로 계산 행과 행으로 계산
행벡터와 열벡터 간의 원소를 곱한후 덧셈 행벡터와 행벡터간의 원소를 곱한후에 덧셈
N*M 과 M*N 즉, 첫번째 열과 두번째 행이 동일 N*M과 N*M에 마지만 차원이 같은 경우
N*M . M*N 은 결과가 N*N N*M과 N*M 은 결과가 N*N
346
347.
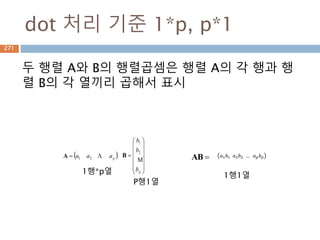
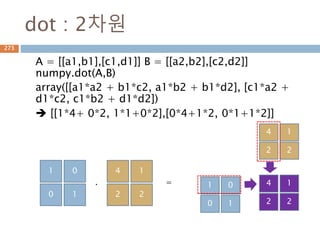
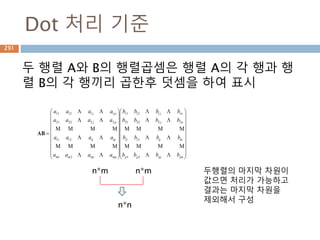
dot 처리 기준1*p, p*1
두 행렬 A와 B의 행렬곱셈은 행렬 A의 각 행과 행
렬 B의 각 열끼리 곱해서 표시
AB 𝑎1 𝑏1 𝑎2 𝑏2 … 𝑎 𝑝 𝑏 𝑝 paaa 21A
pb
b
b
2
1
B
1행*p열
P행1열
1행1열
347
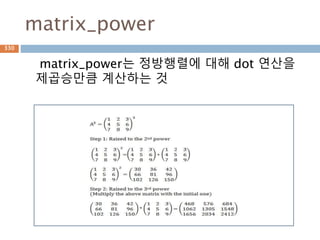
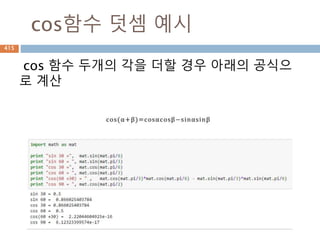
주요 함수
선형대수에 대한함수들
함수 설명
dot(a, b[, out]) n차원 행렬 n*m m*l에 대한 production(결과는 n*l)
vdot(a, b) Vector에 대한 prodution
inner(a, b) N 차원 행렬에 대한 Inner product (행렬이 동일해야 함).
outer(a, b[, out]) 2개 벡터에 대해 계산 후 행렬로 표시.
matmul(a, b[, out]) 두 행렬에 대한 Matrix product (dot과 동일한 결과)
tensordot(a, b[, axes]) Compute tensor dot product along specified axes for arrays >= 1-D.
linalg.matrix_power(M, n) Raise a square matrix to the (integer) power n.
cross(a, b, axisa=-1, axisb=-1, axisc=-1, axis=None) 행렬에 대한 외적을 구함
einsum(subscripts, *operands[, out, dtype, ...]) Evaluates the Einstein summation convention on the operands.
kron(a, b) Kronecker product of two arrays.
410
주요 함수
선형대수에 대한함수들
함수 설명
linalg.cholesky(a) Cholesky decomposition.
linalg.qr(a[, mode]) Compute the qr factorization of a matrix.
linalg.svd(a[, full_matrices, compute_uv]) Singular Value Decomposition.
412
주요 함수
선형대수에 대한함수들
함수 설명
linalg.eig(a) Compute the eigenvalues and right eigenvectors of a square array.
linalg.eigh(a[, UPLO]) Return the eigenvalues and eigenvectors of a Hermitian or symmetric matrix.
linalg.eigvals(a) Compute the eigenvalues of a general matrix.
linalg.eigvalsh(a[, UPLO]) Compute the eigenvalues of a Hermitian or real symmetric matrix.
linalg.eig(a) Compute the eigenvalues and right eigenvectors of a square array.
414
주요 함수
선형대수에 대한함수들
함수 설명
linalg.norm(x[, ord, axis, keepdims]) Matrix or vector norm.
linalg.cond(x[, p]) Compute the condition number of a matrix.
linalg.det(a) Compute the determinant of an array.
linalg.matrix_rank(M[, tol])
Return matrix rank of array using SVD method Rank of the array is the number of SVD sing
ular values of the array that are greater than tol.
linalg.slogdet(a) Compute the sign and (natural) logarithm of the determinant of an array.
trace(a[, offset, axis1, axis2, dtype, out]) Return the sum along diagonals of the array.
416
주요 함수
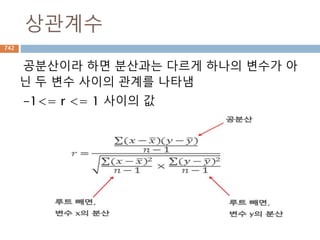
선형대수에 대한함수들
함수 설명
linalg.solve(a, b) Solve a linear matrix equation, or system of linear scalar equations.
linalg.tensorsolve(a, b[, axes]) Solve the tensor equation a x = b for x.
linalg.lstsq(a, b[, rcond]) Return the least-squares solution to a linear matrix equation.
linalg.inv(a) Compute the (multiplicative) inverse of a matrix.
linalg.pinv(a[, rcond]) Compute the (Moore-Penrose) pseudo-inverse of a matrix.
linalg.tensorinv(a[, ind]) Compute the ‘inverse’ of an N-dimensional array.
418
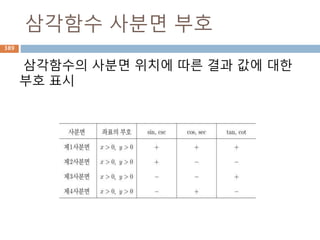
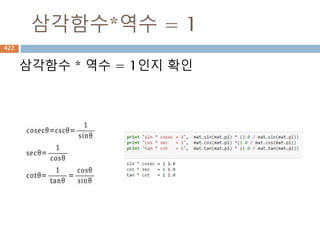
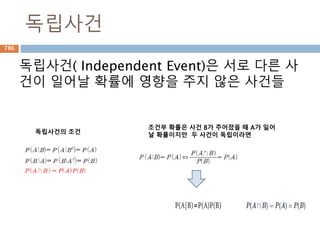
관계
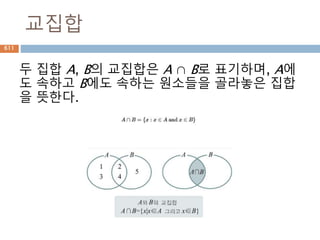
집합론에서 관계(關係)는 "자연수a가 b보다 작
다"와 같이 두 개의 대상으로 이루어진 튜플 사이
에 정의된 이항관계를 일반화한 것으로, 주어진
n-튜플에 대해 진리값을 부여한다.
앞의 경우와 같이 두 대상 사이에 주어지는 관계
는 이항관계라 하고, "점 a, b, c가 한 직선상에 놓
여있다"와 같이 세 대상 사이에 정의된 관계는 삼
항관계라 한다.
422
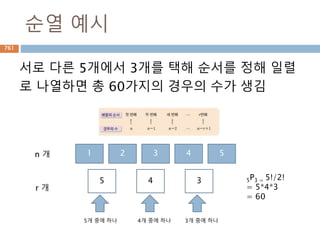
423.
관계 정의
a 는b 에 대해 R 의 관계가 있음은 두 집합 A, B 에
대하여 A 에서 B 로의 이항관계(binary relation)가
AxB의 부분집합일 때 a∈A 이고 b∈B 인 (a, b)∈R ,
a Rb 로 나타내기도 함
(a, b)R 일 경우 또는 로 나타내기도 함
정의역(domain)
관계 R 의 순서쌍에서 모든 첫 번째 원소의 집합: dom(R)
치역(range)
모든 두 번째 원소의 집합: ran(R)
423
관계 종류: 1
1)반사적 관계: 관계 R을 구성하는 집합 A에 대
해서 a ∈ A에 대해 (a,a) ∈ R이라면 관계 R은 반
사적 관계가 된다.
예) A = {a, b, c}
R은 (a,a), (b,b), (c,c)의 원소를 모두 포함해야
지 반사적 관계가 성립된다.
2) 비반사적 관계: R을 집합 X에서의 어떤 이항
관계라고 하자. 만일 모든 x ∈ X에 대해 (x,x) !∈
R이면 R은 비반사적이라고 한다.
430
431.
관계 종류: 2
3)대칭적 관계: 관계 R을 구성하는 집합 A에 대
해서 a, b ∈ A에 대해 (a,b) ∈ R이고 (b,a) ∈ R
이라면 관계 R은 대칭적 관계가 된다.
예) A = {a, b, c}
R에 (a,b)의 원소를 포함하고 있다면 (b,a)의
원소를 가지고 있어야 대칭적 관계가 성립된다.
431
432.
관계 종류: 3
4)반대칭적 관계: 관계 R을 구성하는 집합 A에 대해서 a,
b ∈ A에 대해 (a,b) ∈ R, (b,a) ∈ R이고 a와 b가 같지 않
은 쌍이 한개이상 존재 하지 않을 경우
예) A = {a, b, c}
R1 = { (a,b), (b,a) } 반대칭 관계가 아니다.
R2 = { (a,b), (c,a) } 반대칭 관계이다.
5) 추이적 관계: 관계 R을 구성하는 집합 A에 대해서 a, b,
c ∈ A에 대해 (a,b) ∈ R 그리고 (b,c) ∈ R 일때 (a,c) ∈ R
이라면 관계 R은 추이적 관계가 된다.
예) A = {a, b, c}
R에 (a,b), (b,c)가 있다면 (a,c)가 R에 존재해야 추이적
관계가 된다.
432
433.
관계 종류: 4
6)동치 관계: 반사적, 대칭적, 추이적인 이항 관
계를 뜻한다. 즉, 어떤 집합 X과 관계 ~이 있을 때,
임의의 원소 a, b, c에 대해
반사관계: a ~ a
대칭관계: a ~ b => b ~ a
추이관계: a ~ b, b ~ c => a ~ c가 성립한다는
것을 의미한다.
433
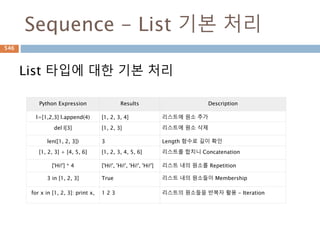
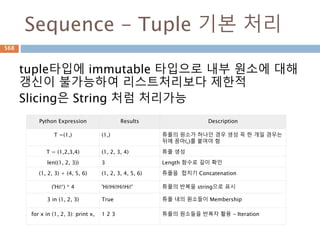
Sequence - Tuple기본 처리
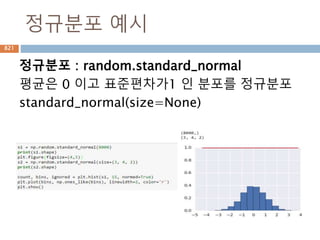
tuple타입에 immutable 타입으로 내부 원소에 대해
갱신이 불가능하여 리스트처리보다 제한적
Slicing은 String 처럼 처리가능
Python Expression Results Description
T =(1,) (1,) 튜플의 원소가 하나인 경우 생성 꼭 한 개일 경우는
뒤에 꼼마(,)를 붙여야 함
T = (1,2,3,4) (1, 2, 3, 4) 튜플 생성
len((1, 2, 3)) 3 Length 함수로 길이 확인
(1, 2, 3) + (4, 5, 6) (1, 2, 3, 4, 5, 6) 튜플을 합치기 Concatenation
('Hi!‘) * 4 'Hi!Hi!Hi!Hi!' 튜플의 반복을 string으로 표시
3 in (1, 2, 3) True 튜플 내의 원소들이 Membership
for x in (1, 2, 3): print x, 1 2 3 튜플의 원소들을 반복자 활용 - Iteration
436
437.
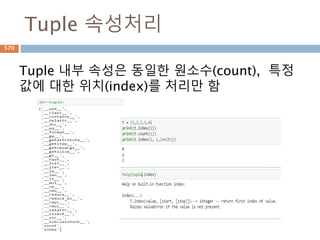
Sequence- Tuple 용내장함수
내장함수 중에 tuple 타입을 처리
Function Description
cmp(tuple1, tuple2) Compares elements of both tuples.
len(tuple) Gives the total length of the tuple.
max(tuple) Returns item from the tuple with max value.
min(tuple) Returns item from the tuple with min value.
tuple(seq) Converts a list into a tuple.
str(tuple) Produces a printable string representation of a tuple
type(tuple) Returns the type of the passed variable. If passed variable is
tuple, then it would return a tuple type.
437
유향변(arc)
유향그래프란 V라는 유한집합과 원소들이 V의 원
소들로 이루어진 순서쌍들인 집합 A로 이루어진 순
서쌍 (V,A)를 의미한다. V의 원소들을 꼭지점
(vertex)이라 부르고 A의 원소들을 유향변(arc)이
라고 부른다. 유향변 (a,b)이 주어졌을 때 a를 그 유
향변의 시작점(initial vertex), b를 종착점
(terminal vertex)이라고 부른다.
461
유도된 그래프
부분그래프가 주어질경우 정점집합과 간선집합이
주어졌을 때 그 그래프 내에서 유도된 그래프
468
G1, G2, G3 모두 G의 부분 그래프이다.
G1 은 변 26을 포함하지 않으므로 유도 부분 그래프가 아니다.
반면, G2, G3 는 유도 부분 그래프이다.
G3 는 G2, 의 유도 부분 그래프이다.
인접행렬
인접 행렬(adjacency matrix)은그래프 G = (V,E),
|V| = n(≥1)일 때 그래프를 이차원 행열에 다음과
같이 저장하는 방법이다.
adj_mat[i][j] =
“1” if (vi, vj)가 인접할 때(adjacent)
“0” 인접하지 않을 경우
470
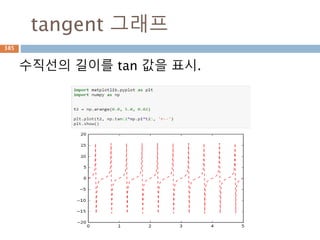
각의 변화를 알아보기
각은n*π/2 + θ 또는 90n + θ으로 변환해서
각의 위치에 따라 삼각함수를 변환
1. 나오는 각을 n*π/2 + θ 또는 90n + θ, 이때 n은
정수 이면 0< θ < π/2 , 0 < θ <90
2. n이 짝수이면 변하지 않지만 홀수이면
sin-> cos, cos-> sin, tan-> cot로 변환
3. 몇 사분면의 각이냐 에 따라 부호가(+,-)로 변환됨
1사분면 2사분면 3사분면 4사분면
sin + + - -
cos + - - +
tan + - + -
518
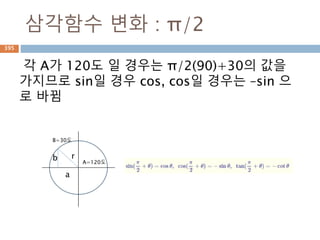
삼각함수 변화 :π/2
각 A가 120도 일 경우는 π/2(90)+30의 값을
가지므로 sin일 경우 cos, cos일 경우는 –sin 으
로 바뀜
r
a
b A=120도
B=30도
525
526.
삼각함수의 변형 :90도 이내
직각 삼각형의 성질을 이용하면 직각을 빼면 나머지
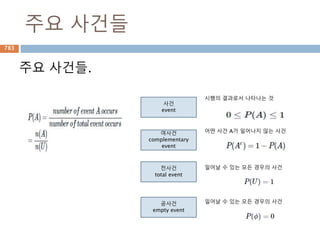
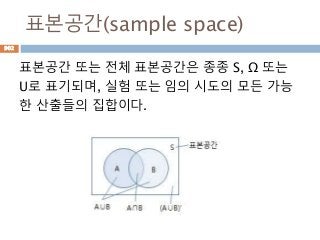
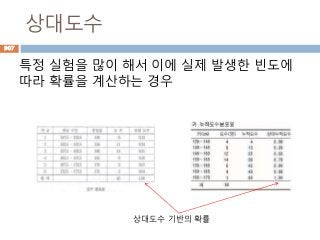
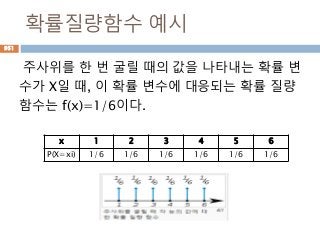
각이 90도인 것을 감안하면, 각 B를 기준을 sin 함수
의 결과는 각 A를 기준으로 cos 함수 결과와 동일
A
B
cos(A) = sin(B), sin(B) = cos(A) , tan(B) = cot(A) 와 동일
각 A + 각 B = 90도
각 B로 삼각함수 처리
526
삼각함수의 변형 :180도 이내
180도 이내의 각으로 삼각함수를 계산할 경우
90도 + 나머지 각으로 삼각함수를 계산할 수 있
음
r
a
b A=120도
B=30도
sin(A) = cos(B) = b/r
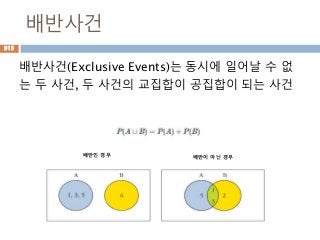
cos(A) = - sin(B) = - a/r
tan(A) = - cot(B) = -b/a
528
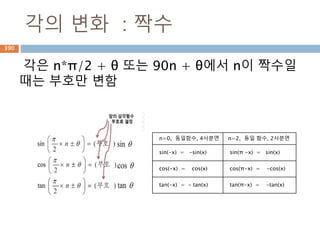
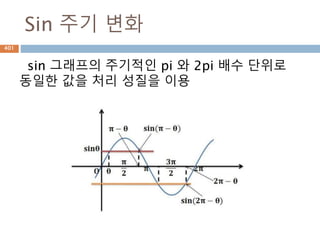
Sin 주기 변화
sin그래프의 주기적인 pi 와 2pi 배수 단위로
동일한 값을 처리 성질을 이용
531
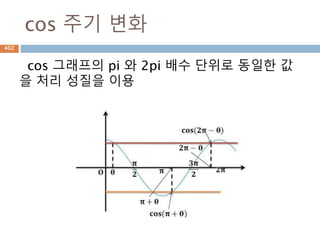
532.
cos 주기 변화
cos그래프의 pi 와 2pi 배수 단위로 동일한 값
을 처리 성질을 이용
532
533.
삼각함수 변화 :π - 예각
180도 이내의 각으로 삼각함수를 계산할 경우
각 B에 대해 계산하는 것과 동일
r
a
b
B=30도
sin(π-B) = sin(B) = b/r
cos(π-B) = - cos(B) = - a/r
tan(π-B) = - tan(B) = -b/a
533
534.
삼각함수 변화 :π + 예각
각 A가 120도 일 경우는 π(180)+30의 값을 가
지므로 sin일 경우 sin, cos일 경우는 –cos 으로
바뀜
r
a
b
A=210도
B=30도
534
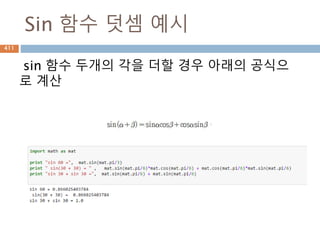
Sin 함수 덧셈
두개의각을 sin으로 덧셈을 할 경우 sin함수별
로 덧셈과는 차이가 발생
r
a
b
t
s
sin(α+ β) = sin(α) cos(β) + cos(α) sin(β)
= a/r * b/s + b/r * t/s
sin(α) cos(β) = a/r * b/s
cos(α) sin(β) = b/r * t/s
sin(α) = a/r , sin(β) = t/s
540
역수
어떤 수의 역수(逆數,영어: reciprocal) 또는 곱셈 역원(-
逆元, 영어: multiplicative inverse)은 그 수와 곱해서 1,
즉 곱셈 항등원이 되는 수를 말한다. x의 역수는 1/x
또는 x -1로 표기한다. 곱해서 1이 되는 두 수를 서로 역
수
549
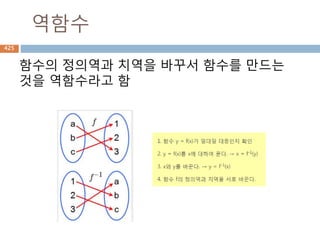
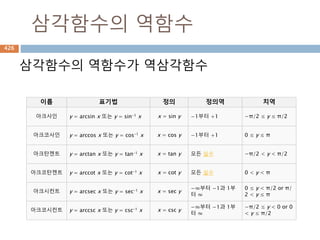
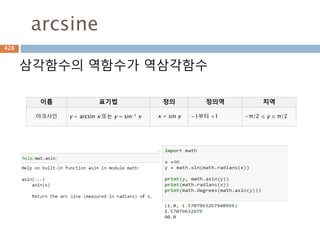
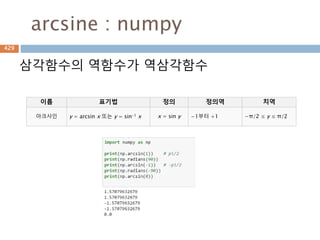
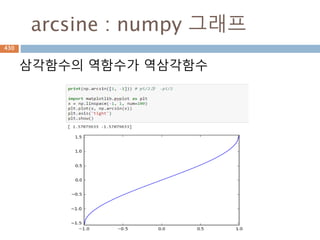
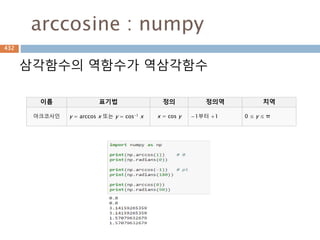
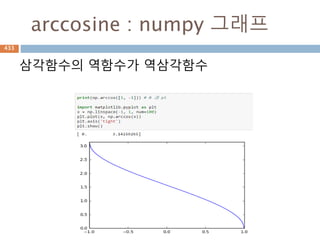
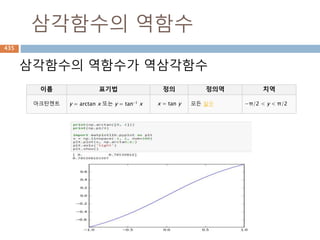
삼각함수의 역함수
삼각함수의 역함수가역삼각함수
이름 표기법 정의 정의역 치역
아크사인 y = arcsin x 또는 y = sin-1 x x = sin y −1부터 +1 −π/2 ≤ y ≤ π/2
아크코사인 y = arccos x 또는 y = cos-1 x x = cos y −1부터 +1 0 ≤ y ≤ π
아크탄젠트 y = arctan x 또는 y = tan-1 x x = tan y 모든 실수 −π/2 < y < π/2
아크코탄젠트 y = arccot x 또는 y = cot-1 x x = cot y 모든 실수 0 < y < π
아크시컨트 y = arcsec x 또는 y = sec-1 x x = sec y
−∞부터 −1과 1부
터 ∞
0 ≤ y < π/2 or π/
2 < y ≤ π
아크코시컨트 y = arccsc x 또는 y = csc-1 x x = csc y
−∞부터 −1과 1부
터 ∞
−π/2 ≤ y < 0 or 0
< y ≤ π/2
556
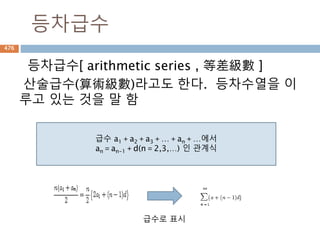
급수(級數,series, ∑an)
수학에서의 급수는수열 a_1, a_2, a_3, ... ,
a_na1,a2,a3,...,an까지 주어졌을 때 이것들을 다 더
해 a_1+a_2+a_3+...+a_n, a1+a2+a3+...+an로
나타낸 것, 즉 수열의 합을 의미한다.
급수의 예는 등차수열, 등비수열의 합, 자연수의 거
듭제곱의 합 등이 있다
602
603.
급수의 표현 1
Σ는 일반항 식을 가지고 시작항과 마지막 항까
지의 합을 표시하는 수학식
603
등차 수열의 합: 등차급수
등차급수( arithmetic series)는 등차수열의 합이
다. 초항부터 n번째 항까지의 합Sn는 다음과 같은
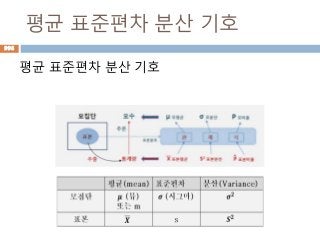
공식으로 나타난다
620
621.
등차 수열의 합의산식
하나의 등차수열과 이 등차수열을 역으로 변환해
서 더하며 동일한 패턴이 값이 나오고 이를 다시
하나(2로 나눔)로 만들면 합산 값이 됨
등차수열을 역순으로 만들고 합산
하면 동일한 결과를 가진 패턴이
나옴
패턴 찾을 것을 2로 나누면 수열
의 합이 계산됨
621
수열의 극한
수열의 극한(數列-極限,limit of a sequence)
은 수열이 한없이 가까워지는 값이다.
직관적으로, 수열 (an)이 수렴(收斂, convergent)
한다는 것은 n이 커짐에 따라 an이 어떤 고정된
값 a에 한없이 가까워지는 것을 뜻한다. 이때 a를
수열 {an}의 극한이라고 한다.
수열이 수렴하지 않으면 발산(發散, divergent)한
다고 한다.
635
수렴
한 점으로 모인다는뜻. 보통 의견 수렴이라든지
여론 수렴 등등으로 해서 한 점에 모인다는 의미
로 사용하는 경우가 많은데, 이 뜻을 수학으로 빌
려와서 여러 값이 기어코야 한 값으로 모이게 되
었다는 의미로 사용한다.
즉 x가 a에 한없이 가까워지거나 한없이 커지거
나 작아지면 f(x)도 어디로 한없이 가까워진다는
뜻.
639
640.
발산
수렴하지 않으면 발산한다.수열이 계속 커지는
양의 무한대로 발산, 수열이 계속 작아지는 음의
무한대로 발산이 있다.
640
String 갱신: 새로만들기
문자열은 immutable이지만 + 연산자는 새로운
문자열 객체를 만들어 결과를 제공
646
647.
String-operator
Operator Description Example
+
Concatenation- Adds values on either side of the operato
r
a + b will give HelloPython
*
Repetition - Creates new strings, concatenating multiple c
opies of the same string
a*2 will give -HelloHello
[]
Slice - Gives the character from the given index a[1] will give e
[ : ]
Range Slice - Gives the characters from the given range a[1:4] will give ell
in
Membership - Returns true if a character exists in the giv
en string
H in a will give 1
not in
Membership - Returns true if a character does not exist in
the given string
M not in a will give 1
r/R
Raw String
print r'n' prints n and print R'n'prints
n
%
Format - Performs String formatting See at next section
647
648.
Operator+ 함수 처리예시
Sequence 타입에 기본으로 처리 되는 함수,
operator
+ : str, list, tuple만 처리 가능하
지만 str, tuple은 별도의 객체로 제
동
min(), max() : 문자열은 숫자값을
기준, list일 경우는 내부 list를 확인
해서 처리
648
649.
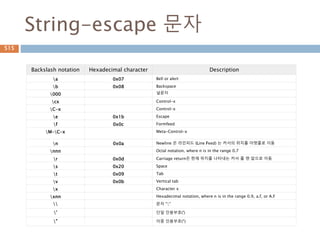
String-escape 문자
Backslash notationHexadecimal character Description
a 0x07 Bell or alert
b 0x08 Backspace
000 널문자
cx Control-x
C-x Control-x
e 0x1b Escape
f 0x0c Formfeed
M-C-x Meta-Control-x
n 0x0a Newline 은 라인피드 (Line Feed) 는 커서의 위치를 아랫줄로 이동
nnn Octal notation, where n is in the range 0.7
r 0x0d Carriage return은 현재 위치를 나타내는 커서 를 맨 앞으로 이동
s 0x20 Space
t 0x09 Tab
v 0x0b Vertical tab
x Character x
xnn Hexadecimal notation, where n is in the range 0.9, a.f, or A.F
문자 ""
' 단일 인용부호(')
" 이중 인용부호(")
649
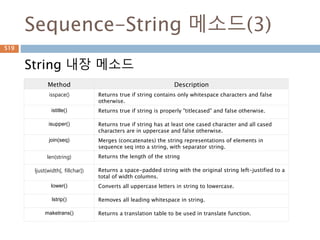
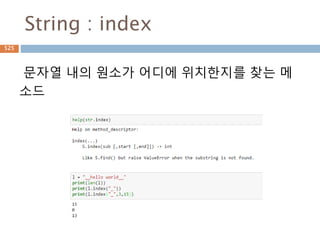
Sequence-String 메소드(1)
String 내장메소드
Method Description
capitalize() Capitalizes first letter of string
center(width, fillchar) Returns a space-padded string with the original string centered to a
total of width columns.
count(str, beg=
0,end=len(string))
Counts how many times str occurs in string or in a substring of string if
starting index beg and ending index end are given.
decode(encoding='UTF-
8',errors='strict')
Decodes the string using the codec registered for encoding. encoding
defaults to the default string encoding.
encode(encoding='UTF-
8',errors='strict')
Returns encoded string version of string; on error, default is to raise a
ValueError unless errors is given with 'ignore' or 'replace'.
endswith(suffix, beg=0,
end=len(string))
Determines if string or a substring of string (if starting index beg and
ending index end are given) ends with suffix; returns true if so and false
otherwise.
expandtabs(tabsize=8) Expands tabs in string to multiple spaces; defaults to 8 spaces per tab if
tabsize not provided.
651
652.
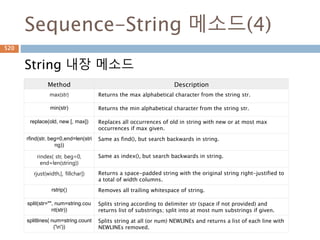
Sequence-String 메소드(2)
String 내장메소드
Method Description
find(str, beg=0
end=len(string))
Determine if str occurs in string or in a substring of string if starting
index beg and ending index end are given returns index if found and -1
otherwise.
index(str, beg=0, end=len(st
ring))
Same as find(), but raises an exception if str not found.
isalnum() Returns true if string has at least 1 character and all characters are
alphanumeric and false otherwise.
isalpha() Returns true if string has at least 1 character and all characters are
alphabetic and false otherwise.
isdigit() Returns true if string contains only digits and false otherwise.
islower() Returns true if string has at least 1 cased character and all cased
characters are in lowercase and false otherwise.
partition () Split the string at the first occurrence of sep, and return a 3-tuple
containing the part before the separator, the separator itself, and the
part after the separator.
652
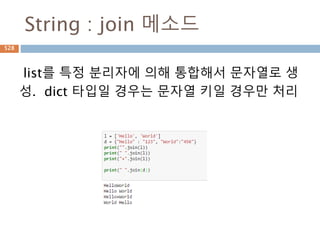
653.
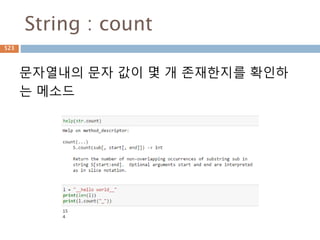
Sequence-String 메소드(3)
String 내장메소드
Method Description
isspace() Returns true if string contains only whitespace characters and false
otherwise.
istitle() Returns true if string is properly "titlecased" and false otherwise.
isupper() Returns true if string has at least one cased character and all cased
characters are in uppercase and false otherwise.
join(seq) Merges (concatenates) the string representations of elements in
sequence seq into a string, with separator string.
len(string) Returns the length of the string
ljust(width[, fillchar]) Returns a space-padded string with the original string left-justified to a
total of width columns.
lower() Converts all uppercase letters in string to lowercase.
lstrip() Removes all leading whitespace in string.
maketrans() Returns a translation table to be used in translate function.
653
654.
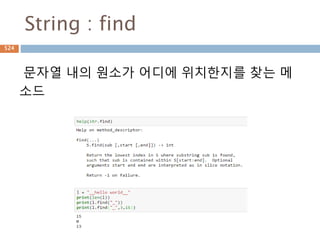
Sequence-String 메소드(4)
String 내장메소드
Method Description
max(str) Returns the max alphabetical character from the string str.
min(str) Returns the min alphabetical character from the string str.
replace(old, new [, max]) Replaces all occurrences of old in string with new or at most max
occurrences if max given.
rfind(str, beg=0,end=len(stri
ng))
Same as find(), but search backwards in string.
rindex( str, beg=0,
end=len(string))
Same as index(), but search backwards in string.
rjust(width,[, fillchar]) Returns a space-padded string with the original string right-justified to
a total of width columns.
rstrip() Removes all trailing whitespace of string.
split(str="", num=string.cou
nt(str))
Splits string according to delimiter str (space if not provided) and
returns list of substrings; split into at most num substrings if given.
splitlines( num=string.count
('n'))
Splits string at all (or num) NEWLINEs and returns a list of each line with
NEWLINEs removed.
654
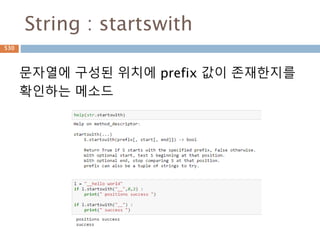
655.
Sequence-String 메소드(5)
String 내장메소드
Method Description
startswith(str,
beg=0,end=len(string))
Determines if string or a substring of string (if starting index beg and
ending index end are given) starts with substring str; returns true if so
and false otherwise.
strip([chars]) Performs both lstrip() and rstrip() on string
swapcase() Inverts case for all letters in string.
title() Returns "titlecased" version of string, that is, all words begin with
uppercase and the rest are lowercase.
translate(table, deletechars
="")
Translates string according to translation table str(256 chars), removing
those in the del string.
upper() Converts lowercase letters in string to uppercase.
zfill (width) Returns original string leftpadded with zeros to a total of width
characters; intended for numbers, zfill() retains any sign given (less one
zero).
isdecimal() Returns true if a unicode string contains only decimal characters and
false otherwise.
655
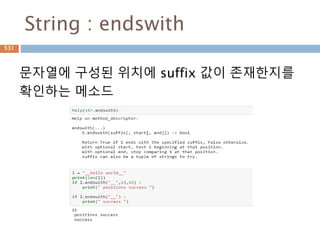
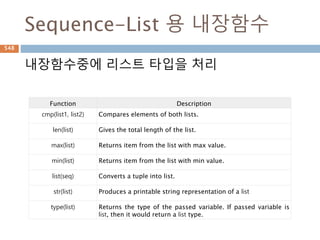
Sequence-List 용 내장함수
내장함수중에리스트 타입을 처리
Function Description
cmp(list1, list2) Compares elements of both lists.
len(list) Gives the total length of the list.
max(list) Returns item from the list with max value.
min(list) Returns item from the list with min value.
list(seq) Converts a tuple into list.
str(list) Produces a printable string representation of a list
type(list) Returns the type of the passed variable. If passed variable is
list, then it would return a list type.
682
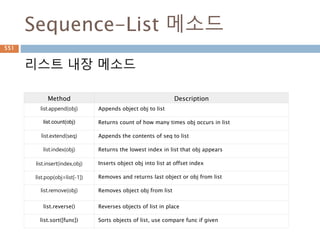
Sequence-List 메소드
리스트 내장메소드
Method Description
list.append(obj) Appends object obj to list
list.count(obj) Returns count of how many times obj occurs in list
list.extend(seq) Appends the contents of seq to list
list.index(obj) Returns the lowest index in list that obj appears
list.insert(index,obj) Inserts object obj into list at offset index
list.pop(obj=list[-1]) Removes and returns last object or obj from list
list.remove(obj) Removes object obj from list
list.reverse() Reverses objects of list in place
list.sort([func]) Sorts objects of list, use compare func if given
685
slicing 내부 조회/갱신/삭제
Sequence타입 에 대한 원소를 조회, 갱신, 삭제를
추가하는 메소드, 갱신과 삭제는 list 타입만 가능
(python 2.x에만 있음)
object.__getslice__(self, i, j)
object.__setslice__(self, i, j, sequence)
object.__delslice__(self, i, j)
검색
생성/변경
삭제
716
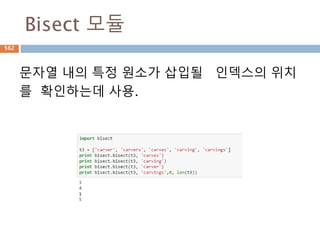
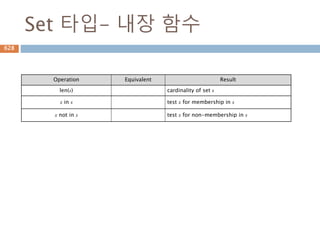
Set 타입- 내장함수
Operation Equivalent Result
len(s) cardinality of set s
x in s test x for membership in s
x not in s test x for non-membership in s
756
757.
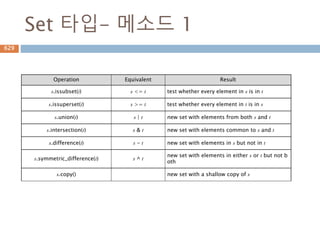
Set 타입- 메소드1
Operation Equivalent Result
s.issubset(t) s <= t test whether every element in s is in t
s.issuperset(t) s >= t test whether every element in t is in s
s.union(t) s | t new set with elements from both s and t
s.intersection(t) s & t new set with elements common to s and t
s.difference(t) s - t new set with elements in s but not in t
s.symmetric_difference(t) s ^ t
new set with elements in either s or t but not b
oth
s.copy() new set with a shallow copy of s
757
758.
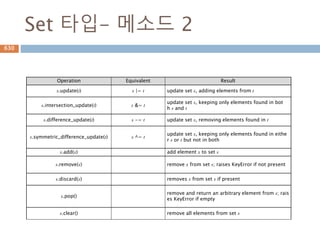
Set 타입- 메소드2
Operation Equivalent Result
s.update(t) s |= t update set s, adding elements from t
s.intersection_update(t) s &= t
update set s, keeping only elements found in bot
h s and t
s.difference_update(t) s -= t update set s, removing elements found in t
s.symmetric_difference_update(t) s ^= t
update set s, keeping only elements found in eithe
r s or t but not in both
s.add(x) add element x to set s
s.remove(x) remove x from set s; raises KeyError if not present
s.discard(x) removes x from set s if present
s.pop()
remove and return an arbitrary element from s; rais
es KeyError if empty
s.clear() remove all elements from set s
758
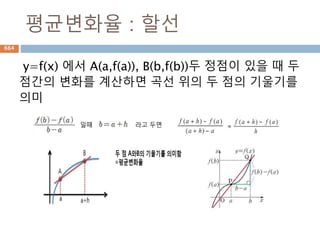
미분가능한 함수 :differentiable function
미분은 함수 f(x)의 순간변화율을 계산하는 과정
이다.
f(x)에서 미분계수 f'(a) 가 존재할 때 미분 가능이
라고 한다.
정의역의 모든 점에서 미분가능한 함수이다.
즉, 모든 곳에서 수직이 아닌 접선을 그릴 수 있다
는 것이다
803
804.
미분가능
함수 f가 점x0에서 미분가능하다는 건 그 점에서
의 미분, 즉 평균변화율의 극한이 존재하는 것으
로 정의된다
804
기울기(gradient)
기울기(gradient 그래디언트)란 벡터미적분학에
서 스칼라장의 최대의 증가율을 나타내는 벡터장
을 뜻한다.
기울기를 나타내는 벡터장을 화살표로 표시할 때
화살표의 방향은 증가율이 최대가 되는 방향이며,
화살표의 크기는 증가율이 최대일 때의 증가율의
크기를 나타낸다.
837
838.
기울기(gradient)의 의미
어느 방안의공간 온도 분포가 스칼라장 φ로 주어졌다고 가정한
다. 이 때, 방안의 어느 한 점(x,y,z)에서의 온도는 φ(x,y,z)로 표
시할 수 있다. (온도는 시간에 의해 변화하지 않는다고 가정) 이
경우에 어느 한 지점에서의 기울기는 온도가 가장 빨리 증가하는
방향과 그 증가율을 나타낸다.
이번에는 산이나 언덕을 가정해보자. 어떤 지점(x,y)에서의 높이
를 H(x,y)로 표현하는 경우, 기울기는 가장 (위를 바라보는)경사
가 가파른 방향과 그 경사의 크기를 나타낸다.
기울기를 이용해 다른 방향의 증가율을 구하려면 기울기와 그 방
향의 단위 벡터의 내적을 취하면 된다.
기울기는 무회전성 벡터계이다. 즉, 기울기 벡터계에 대해 선적
분을 구하면 결과값은 경로와 상관없이 시작점과 끝점에 따라서
만 변화함을 뜻한다.
838
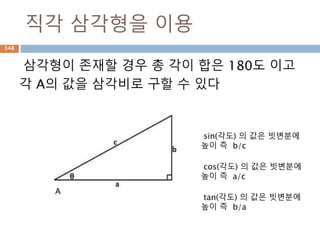
정적분: definite integral
리만적분에서 다루는 고전적인 정의에 따르면 실수
의 척도를 사용하는 축도 공간에 나타낼 수 있는 연
속인 함수 f(x)에 대하여 그 함수의 정의역의 부분 집
합을 이루는 구간 [a, b] 에 대응하는 치역으로 이루
어진 곡선의 리만 합의 극한을 구하는 것이다. 이를
정적분(定積分, definite integral)이라 한다.
851
852.
정적분: 식의 이해
x를a부터 b까지 변화시키면서 f(x)에 dx를 곱한
것을 전부 합쳐라
852
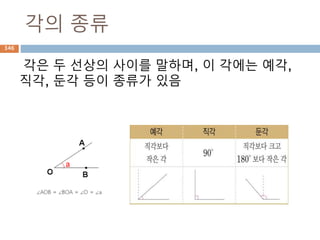
경우의 수 (numberof cases)
경우는 수는 사건에서 일어날 수 있는 경우의 가
짓수(원소의 개수)를 말하며, 합의 법칙과 곱의
법칙에 따라 경우의 수를 계산
같은 조건에서 여러 번 할 수 있는 실험이나
관찰로 얻어진 결과를 말한다.
즉, 어떤 실험이나 관찰에서 주어진 경우를
만족하는 경우의 집합
사건
시행 실험이나 관찰을 하는 행위
869
합/곱의 법칙 구별
동시에일어나는 사건을 경우 별개의 두 사건이 모두 발
생하는 것(곱의 법칙)이고, 별개의 두 사건이 있는 경우
둘다 일어나지 않아도 상관없는 것(합의 법칙)임
독립사건 A 또는 B가 일어나는 경우의 수를
구할 때에는 합의 법칙이 이용된다.
독립사건 A와 B가 동시에 일어나는 경우의 수
를 구할 때에는 곱의 법칙이 이용된다
878
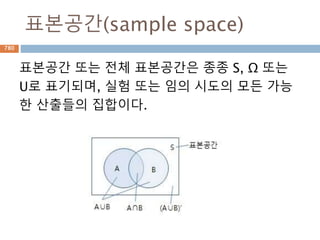
확률
확률현상은 불확실성에 대해좌우되는 현상이다.
확률현상에 대해 현실에서 실험하는 것을 확률실
험(ε)이라고 한다.
확률현상에서 얻어질 수 있는 모든 결과를 표본
공간(Ω) 이라고 한다.
또한 표본공간의 부분집합을 확률사건(E,Event)
라고 한다. 한 확률실험에서 ‘어떤 사건이 일어나
리라고 예축되는 정도를 나태내는 수치'를 그 사
건이 일어날 확률이라고 한다.
895
896.
통계적 확률
시행횟수 n이커짐에 따라 사건 A가 일어나는 횟
수를 r이라 하면 상대도수 r/n이 일정한 값 p에
가까워질 때, 이 일정한 p를 구함
896
897.
수학적 확률
어떤 시행의표본공간 S가 n개의 근원사건으로
이뤄져 있고 각 근원사건이 일어날 가능성이 모
두 똑같이 기대될 때, 사건 A가 r개의 근원사건으
로 이루어져 있으면 사건 r이 일어날 확률 P(A)를
P(A) = r/n으로 정의
897
898.
확률의 기본 특성
서로배타적인 결과를 갖는 실험에서 어떤 사상
이 일어날 확률은 음수가 아닌 숫자로 표시
898
실험
실험(實驗)은 가설이나 이론이실제로 들어맞는
지를 확인하기 위해 다양한 조건 아래에서 여러
가지 축정을 실시하는 일이다. 지식을 얻기 위한
방법의 하나이다. 실험은 관찰(축정도 포함)과 함
께 과학의 기본적인 방법의 하나이다. 다만 관찰
이 대상 그 자체를 있는 그대로 알려보는 일이라
면, 실험은 어떤 조작을 가해 그에 따라 일어나는
변화를 조사하고 결론을 내는 일이다.
900
901.
시행(trial)
모든 결과가 우연에의해서 지배가 되고 반복가
능하며 모든 결과가 예축이 가능한 실험이나 관
찰
확률실험(random experiment)즉 시행은 결과
가 우연에 좌우되는 현상을 실현시키는 행위는
실험, 관 찰, 조사 등으로써 몇 가지 특징을 가지
는 것을 시행 또는 확률실험이라고 한다.
901
사건
확률에서는 실험에서 발생할수 있는 결과들이 기본 사건
(elementary event) 이라고 불리는데 이것의 모음은 그
냥 사건이라고 일컫는다.
어떤 실험의 표본공간 S에 관한 사건(event)이란 S의 부
분 집 합을 뜻함. 즉, 실험의 가능한 결과로 이루어진 집
합을 사건 (event)이라 함
909
근원사건
사건 중에 표본공간의 전체집합에서
원소가 1개인 부분집합
독립
두 사건이 독립(獨立,independent)이라는 것은,
둘 중 하나의 사건이 일어날 확률이 다른 사건이
일어날 확률에 영향을 미치지 않는다는 것을 의
미한다.
예를 들어서, 주사위를 두 번 던지는 경우 첫 번째
에 1이 나오는 사건은 두 번째에 1이 나올 확률에
독립적이다.
912
913.
독립사건
독립사건( Independent Event)은서로 다른 사
건이 일어날 확률에 영향을 주지 않은 사건들
913
조건부 확률은 사건 B가 주어졌을 때 A가 일어
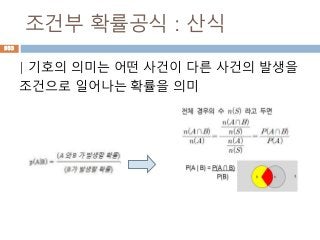
날 확률이지만 두 사건이 독립이라면독립사건의 조건
기본
1) A의 여사건A'의 확률은
P(A')=1-P(A)
2) 덧셈정리 : 두 사건 A, B에 대하여,
P(A∪B)=P(A)+P(B)-P(A∩B)
3) 임의의 두 사건 A, B가 주어졌을 때,
A와 B의 여사건이면
P(A∩B')= P(A)-P(A∩B)
4) 특히, A와 B가 서로 배반사건이면,
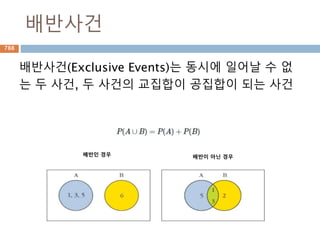
P(A∪B)= P(A)+P(B) .
920
921.
확률의 덧셈정리 조건
•두 사건 중 적어도 하나의 사건이 일어날 확률
과 관련
• 좁은 의미의 덧셈법칙은 상호배반일 경우만 가
능
• 배반이 아닌 경우 중복 계산되는 부분을 제거해
야 한다.
921
922.
확률의 덧셈정리 식
사건A 또는 사건 B가 일어날 확률은 사건A가 일
어날 확률 과 사건 B가 일어날 확률을 더해서 구
함
922
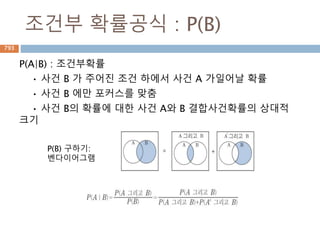
기본
P(A and B):결합확률 (joint probability)
• 두 사건이 함께 일어날 확률
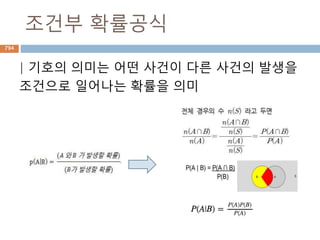
P(A | B): 조건부확률 (conditional probability)
• 사건 B가 주어진 조건 하에서 사건 A가
일어날 확률
P(A), P(B): 주변확률 (marginal probability)
• 비조건부 확률
924
925.
곱셈법칙 조건
• 두사건이 함께 일어날 확률과 관련
• 좁은 의미의 곱셈법칙은 상호독립일 경우만 가
능
• 독립이 아닌 (종속의) 경우 하나의 주변확률과
다른 하나의 조건부확률을 곱해야 한다
925
926.
확률의 곱셈정리식 :조건부
사건 A 와 사건 B가 동시에 일어날 확률은 사건
A가 일어날 확률 과 사건 B가 일어날 결합확률은
확률의 곱으로 구함
926
927.
확률의 곱셈정리 :독립사건
두 사건이 서로 독립일 때, 두 사건이 모두 일어
날 확률은 각각의 비조건부 확률을 곱하여 얻는
다. 이를 좁은 의미의 곱셈법칙이라고 부른다.
927
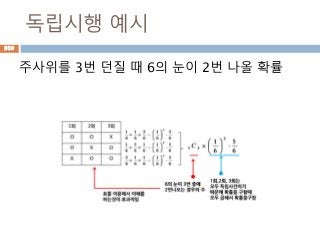
독립시행 예시
주사위를 6번던질 때 1 또는 2의 눈이 2번 나올
확률을 구하여라.
940
1 2 3 4 5 6
1 or 2 o o x x x x
1 or 2 o o x x x x
1 or 2 o o x x x x
1 or 2 o o x x x x
1 or 2 o o x x x x
1 or 2 o o x x x x
1or 2 확률 = 2/6 = 1/3
= 6C2(1/3)2(1-1/3) 6-2
= 6!/2!4! (1/9)(4/81)
= 15*(16/729)
= 80/243
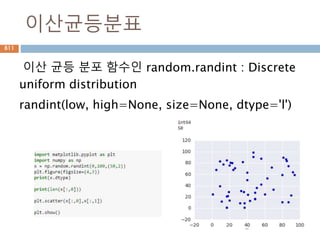
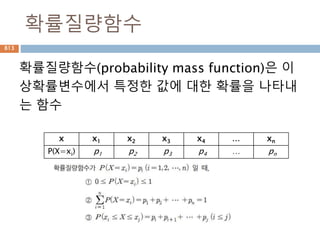
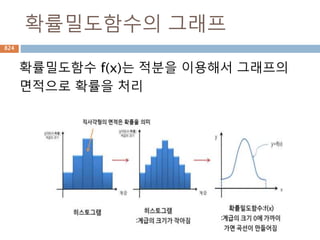
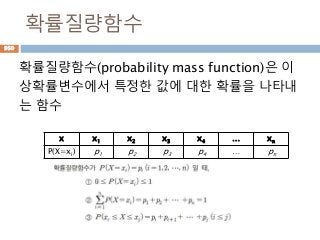
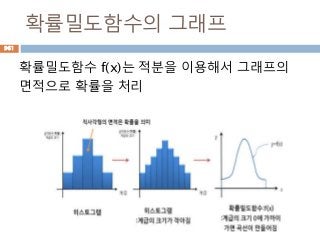
확률밀도함수
확률밀도함수(probability density function약
자 PDF )f(x)는 일정한 값들의 범위를 포괄하는
연속확률변수의 확률을 찾는데 사용하고 연속데
이터에서의 확률을 구하기 위해서 확률밀도함수
의 면적을 구함
960
확률 밀도함수 f(x)와 구간[a,b] 에
대해 확률변수 X가 구간에 포함될
확률 P(a<= X<=b)는
확률변수의 분산
분산(Variance)은 각확률변수들이 기대값(=확
률사건 평균)으로부터 얼마나 떨어져서 분산되어
있는지 가늠할 수 있는 하나의 척도, 즉 하나의 값
을 말한다. 사실 분산은 표준편차를 구하기 위한
과정이라고 보면 된다. 분산을 구하는 방법은 아
래와 같다.
분산은 소문자 시그마의 제곱으로 표현 σ2 한다
973
확률변수의 공분산
공분산은 두확률변수의 상관관계를 나타내는 것
이다. 만약 두 확률 변수중 하나의 변수 값이 상승
하는 경향을 보일 때, 다른 확률변수 값도 상승하
는 상관관계에 있다면, 공분산의 값은 양수가 된
다. 반대로 두 개의 확률 변수중 하나의 변수 값이
상승하는 경향을 보일 때, 다른 확률변수 값이 하
강하는 경향을 보인다면 공분산의 값은 음수가
된다.
공분산이 0에 가까우면 상관관계가 적다는 것을
의미한다. Xi와 Xj의 공분산 σij = 0 이면 Xi와 Xj
는 독립이다.
985
986.
확률변수의 공분산 식
공분산은하나의 사건에 대하여 발생하는 두 확
률변수의 각 기대값과의 차이를 곱한 것들의 합
이라고 보면 된다.
986
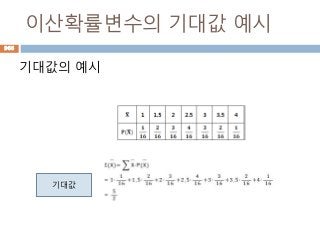
통계학의 종류
기술통계학(descriptive statistics)는모집단 전체
혹은 표본으로부터 얻은 데이터에 대한 숫자 요약9
평균, 분산 등)이나 그래표 요약을 통해 데이터가 가
진 정보를 정리하는 이론이나 방법론
추론통계학(inferential statistics)는 표본으로부터
얻은 정보를 이용해서 모집단의 특성(모
수:parameter)을 추론(추정, 검정)하거나 변수들간
의 적절한 함수관계(modeling)의 진위 여부를 판단
하는 일련의 과정에 관한 이론과 방법론
992
993.
확률과 통계 비교
확률적관점 : 이미 알고 있는 모집단에서 어떤 사
건이 일어날 확률에 관심이 있다.
통계적 관점 : 표본에서 얻은 정보를 이용하여 미
지의 모집단을 미루어 짐작하는 추론에 관심이
있다.
993
통계 분석
연구 목적이설정되면 그에 맞는 통계적 가설이나 모형을
설정하고, 관련 데이터 수집하여 정리하고 분석하여, 가
설 혹은 모형의 유의성을 검정하는게 통계 분석
995
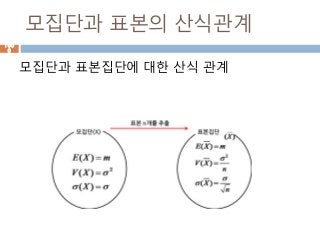
통계 (Statistics)의 역할
모집단
);( xf
표본
1X
2X
nX
1x
2x
nx
),,,(ˆ
211 nxxx
데이터 수집 ; sampling
확률이론
확률
확률변수
확률분포
통계적 추론 데이터 처리
척도 계산, 분포 유추모수 추정, 가설검정
기술 통계학추리 통계학
기초
제공
Θ =μ,σ,‥
p, ‥
),,,(ˆ 212 nxxxp
:
?0
?0pp
:
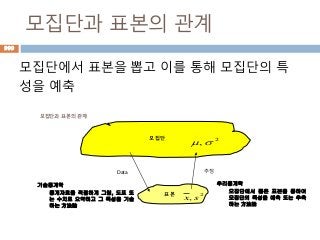
모집단과 표본의 관계
모집단에서표본을 뽑고 이를 통해 모집단의 특
성을 예축
999
모집단과 표본의 관계
모집단
표본
Data 추정
2
,
2
, sx
기술통계학
통계자료를 적절하게 그림, 도표 또
는 수치로 요약하고 그 특성을 기술
하는 方法論
추리통계학
모집단에서 뽑은 표본을 통하여
모집단의 특성을 예축 또는 추축
하는 方法論
표집 :sampling
표본은 다룰수 있을만한 크기의 부분 집합을 나
타낸다. 표본이 얻어지면 모집단으로부터 얻은
표본에 대해 추론(inference) 또는 외삽법
(extrapolation)을 하기 위하여 통계적 계산이 수
행된다. 표본으로부터 이러한 정보를 얻기 위한
과정(process)을 표집(sampling)이라고 한다.
1006
가설검증
가설의 검정(test ofhypotheses) : 모수의 값의 범
위를 규정하는 두개의 가설을 세우고, 이들 중 어느
것이 참인지를 표본의 결과로 부터 판단하는 것
1. 자연, 사회 현상을 관찰하여 이론을 세운다.(가설)
2. 실험, 조사를 통해 실제 현상을 관찰한다. (표본 추출)
3. 실제 관찰 결과가 이론에서 예축되는 것과 부합하는지
판단한다.(가설 검정)
4. 부합되면 1번의 이론을 사실로 판단하고, 아니면 탐구
를 반복한다.
101
4
수리적 통계 변수
이산형변수 (discrete variable) : 남/녀, 자동차
종류 등과 같이 연속성이 없는 변수
연속형 변수 (continuous variable) : 키, 몸무게
등 실수와 같이 쪼게면 쪼겔수록 무한히 쪼게지
는 연속된 변수
101
6
1017.
데이터 분석적 통계변수
축정형변수(metric) : 셀 수 있거나 축정 가능한
특성을 축정한 변수
분류형/범부형 변수(non-metric) : 개체를 분류
하기 위해 축정된 변수
명목형(nominal) : 범주의 크기 순서가 없는 경우
순서형(ordinal) : 범주의 크기 순서가 있는 경우
1017
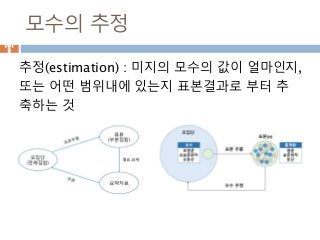
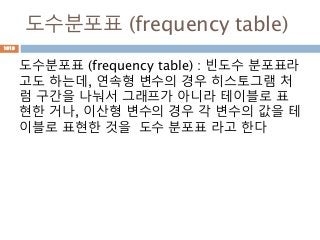
도수분포표 (frequency table)
도수분포표(frequency table) : 빈도수 분포표라
고도 하는데, 연속형 변수의 경우 히스토그램 처
럼 구간을 나눠서 그래프가 아니라 테이블로 표
현한 거나, 이산형 변수의 경우 각 변수의 값을 테
이블로 표현한 것을 도수 분포표 라고 한다
1019
1020.
도수분포표 : 그리는단계
1. 관축치 중 최대값과 최소값을 찾는다.
2. 최대값과 최소값의 차이, 즉 범위를 구한다.
3. 몇 개의 구간으로 나눌 것이지 결정한다
(대략 6개-14개).
4. 구간이 중복되지 않도록 범위를 정한다.
5. 각 구간에 속하는 관축치의 수를 세어
도수를 구한다.
1020
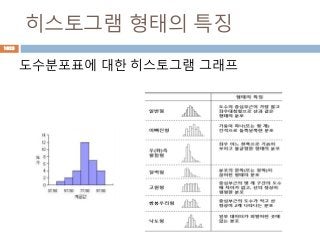
히스토그램
히스토 그램 :연속형 변수는 히스토그램을 이용
하여 표현이 가능하다. 히스토그램이란, 연속된
변수의 X축을 일정 구간으로 나눠서, (5씩) 그 구
간에 들어가는 데이터를 표현하는 방법으로, 키
를 예를 들면 160~170,170~180에 각각 몇 명
이 있는지 그래프로 나타내면 히스토 그램이라고
한다.
1022
편차
통계학에서 편차(deviation)는 관축값과평균의 차이
를 말한다. 편차점수라고도 한다.
어떤 변인 y에서 특정 사례의 편차 d를 다음과 같이
나타낼 수 있다.
편차는 양수일수도 있고 음수일 수 있으며, 이는 평
균보다 크거나 작음을 나타낸다. 값의 크기는 관축값
이 평균으로부터 얼마나 떨어져 있는가를 나타낸다.
편차는 오류 또는 잔차라고 할 수 있다. 모집단 평균
에서의 편차는 오류이며, 표집 평균에서의 편차는 잔
차이다..
1058
왜도
왜도(歪度; skewness)란, 데이터의 분포형태가
기울어진 정도를 의미한다.
분포의 형태는 좌우대칭이면 왜도는 0이 되고, 왜
도가 + 의 값을 가지면 오른쪽으로 긴 꼬리를 가
지는 형태, -의 값을 가지면 왼쪽으로 긴 꼬리를
가지는 형태를 보인다.
1073
1074.
첨도
첨도(尖度;kurtosis)란 분포가 평균치주변에 몰
려 있는 형태인지 멀리 퍼져 있는 형태인지 그 뾰
족한 정도를 의미한다.
표준정규분포의 첨도계수는 0이며, 0보다 크면
표준정규분포에 비해 더 뾰족하게 몰려 있는 형
태를 가지고, 0보다 작으면 보다 넓게 퍼져 있는
형태의 데이터라고 할 수 있다.
1074


















![실수
실수 [實數, real number] 정수의 몫으로 정의되
는 유리수의 범위에서는 대소의 순서를 정할 수
있으며, 사칙연산을 자유로이 할 수 있다.
그러나 이 범위에서는 역시 불완전한 점이 많다.
이를테면, 단위의 길이를 가지는 정사각형의 대
각선의 길이(x=2의 근)는 유리수로 나타낼 수 없
다.
이와 같은 결함을 보완하기 위하여 유리수에 무
리수를 첨가하여 수의 범위를 실수까지 확장한
것이다.
20](https://image.slidesharecdn.com/20160730-160726074138/85/python-20-320.jpg)

















![실수 1 : sympy
실수 [實數, real number]
42](https://image.slidesharecdn.com/20160730-160726074138/85/python-42-320.jpg)
























































![연산자 우선순위
순위 구분 Operator Description
0 그룹 ( ) Parentheses (grouping)
1 함수 f(args...) Function call
2 참조 x[index:index] Slicing
3 참조 x[index] Subscription
4 참조 x.attribute Attribute reference
5 산술 ** Exponentiation(제곱)
6 비트 ~x Bitwise not
7 부호 +x, -x Positive, negative
8 산술 *, /, % Multiplication, division, remainder
9 산술 +, - Addition, subtraction
10 비트 <<, >> Bitwise shifts
11 비트 & Bitwise AND
12 비트 ^ Bitwise XOR
13 비트 | Bitwise OR
14 비트 in, not in, is, is not, <, <=, >, >=,<>, !=, == Comparisons, membership, identity
15 논리 not x Boolean NOT
16 논리 and Boolean AND
17 논리 or Boolean OR
18 함수 lambda Lambda expression
125](https://image.slidesharecdn.com/20160730-160726074138/85/python-125-320.jpg)








































































![Mapping -dictionary 메소드
Method Description
dict.clear() Removes all elements of dictionary dict
dict.copy() Returns a shallow copy of dictionary dict
dict.fromkeys() Create a new dictionary with keys from seq and values set to value.
dict.get(key,
default=None)
For key key, returns value or default if key not in dictionary
dict.has_key(key) Returns true if key in dictionary dict, false otherwise
dict.items() Returns a list of dict's (key, value) tuple pairs
dict.keys() Returns list of dictionary dict's keys
dict.setdefault(key,
default=None)
Similar to get(), but will set dict[key]=default if key is not already in dict
dict.update(dict2) Adds dictionary dict2's key-values pairs to dict
dict.values() Returns list of dictionary dict's values
dict.iteritems() Iterable한 items를 만들기
227](https://image.slidesharecdn.com/20160730-160726074138/85/python-227-320.jpg)
![dict.get/setdefault()사용
dict에 내의 원소를 추가하거나 갱신하고 이를 []
연산자나 get 메소드로 호출해서 처리
230](https://image.slidesharecdn.com/20160730-160726074138/85/python-230-320.jpg)


![버전변경
keys,items 등이 메소드 결과가 리스트 타입에
서 객체타입으로 변경
Notes Python 2 Python 3
①
a_dictionary.keys() list(a_dictionary.keys())
②
a_dictionary.items() list(a_dictionary.items())
③
a_dictionary.iterkeys() iter(a_dictionary.keys())
④
[i for i in a_dictionary.iterkeys()] [i for i in a_dictionary.keys()]
⑤
min(a_dictionary.keys()) no change
234](https://image.slidesharecdn.com/20160730-160726074138/85/python-234-320.jpg)







































![벡터: 스칼라곱
벡터의 각 원소에 스칼라값만큼 곱하여 표시
벡터 m = [7,3]
A = 3m= [21,9]
296](https://image.slidesharecdn.com/20160730-160726074138/85/python-296-320.jpg)








![외적 산식 : 2차원
벡터의 원소간의 cross 적을 처리
v = [a1,a2]
u = [b1,b2]
a1 a2
b1 b2
a1*b2 – a2*b1 Example: The cross product of a = (2,3) and b = (5,6)
c = a1b2 − a2b1 = 2×6− 3×5 = −3
Answer: a × b = -3
310](https://image.slidesharecdn.com/20160730-160726074138/85/python-310-320.jpg)
![외적 산식 : 3차원
벡터의 원소간의 cross 적을 처리
v = [a1,a2,a3]
u = [b1,b2,b3]
a2 a3 a1 a2
b2 b3 b1 b2
x 축 : a2*b3 – a3*b2
y 축 : a3*b1 – a1*b2
z 축 : a1*b2 – a2*b1
Example: The cross product of a = (2,3,4) and b = (5,6,7)
cx = aybz − azby = 3×7 − 4×6 = −3
cy = azbx − axbz = 4×5 − 2×7 = 6
cz = axby − aybx = 2×6 − 3×5 = −3
Answer: a × b = (−3,6,−3)
311](https://image.slidesharecdn.com/20160730-160726074138/85/python-311-320.jpg)
![inner 계산 방식
A = [[a1,b1] B = [[a2,b2]]
numpy.inner(A,B)
array([[a1*a2 + b1*b2]])
[[1*4+0*1]]
1 0 4 1
1 0
4 1
4=.
314](https://image.slidesharecdn.com/20160730-160726074138/85/python-314-320.jpg)


![outer
A = [[a1,b1]] B = [[a2,b2]]
numpy.outer(A,B)
array([[a1*a2 , a1*b2][ b1*a2, b1*b2]])
[[1*4,1*1] [0*4+0*1]]
1 0 4 1 1
0
4 1
4 1
0 0
=
317](https://image.slidesharecdn.com/20160730-160726074138/85/python-317-320.jpg)










![항등행렬
모든 행렬과 닷 연산시 자기 자신이 나오게 하는
단위행렬
import numpy as np
a = np.array([[1,0],[0,1]])
b = np.array([[4,1],[3,2]])
print(np.dot(b,a))
print(np.dot(a,b))
[[4 1]
[3 2]]
[[4 1]
[3 2]]
336](https://image.slidesharecdn.com/20160730-160726074138/85/python-336-320.jpg)










![dot : 2차원
A = [[a1,b1],[c1,d1]] B = [[a2,b2],[c2,d2]]
numpy.dot(A,B)
array([[a1*a2 + b1*c2, a1*b2 + b1*d2], [c1*a2 +
d1*c2, c1*b2 + d1*d2])
[[1*4+ 0*2, 1*1+0*2],[0*4+1*2, 0*1+1*2]]
1 0
0 1
4 1
2 2
1 0
0 1
4 1
2 2
4 1
2 2
=.
349](https://image.slidesharecdn.com/20160730-160726074138/85/python-349-320.jpg)








![역행렬(inv) – 2차원
역행렬은 수반행렬에 행렬식으로 나눗값이 됨
[[ 0.66666667 -0.33333333]
[-0.33333333 0.66666667]]
1/3 *
2 -1
-1 2
역행렬
2 1
1 2
-1
A−1=1/det(A) * CT
363](https://image.slidesharecdn.com/20160730-160726074138/85/python-363-320.jpg)
![역행렬(inv) – 3차원
역행렬은 수반행렬에 행렬식으로 나눗값이 됨
[[ 0.5 -1. 1.5]
[-0.5 0. 1.5]
[ 0. 1. -2. ]]
- 0.5 *
-1 2 -3
1 0 -3
0 -2 4
역행렬3 1 3
2 2 3
1 1 1
-1
A−1=1/det(A) * CT
364](https://image.slidesharecdn.com/20160730-160726074138/85/python-364-320.jpg)





![cross 계산 방식
A = [[a1,b1],[c1,d1]] B = [[a2,b2],[c2,d2]]
numpy.cross(A,B) = A.T * B
array([[a1*b2 - c1*a2 , b1*d2 – d1*c2])
[[1*1- 0*4,0*2-1*2]]
1 0
0 1
4 2
1 2
1 -2=
371](https://image.slidesharecdn.com/20160730-160726074138/85/python-371-320.jpg)
![inner 계산 방식
A = [[a1,b1],[c1,d1]] B = [[a2,b2],[c2,d2]]
numpy.inner(A,B)
array([[a1*a2 + b1*b2, a1*c2 + b1*d2], [c1*a2 +
d1*b2, c1*c2 + d1*d2])
[[1*4+0*1,1*2+0*2],[0*4+1*1, 0*2+1*2]]
1 0
0 1
4 1
2 2
1 0
0 1
4 1
2 2
4 2
1 2
=.
374](https://image.slidesharecdn.com/20160730-160726074138/85/python-374-320.jpg)
![Inner 예시 : 2차원
a(2,2) 행렬과 b(2,2)행렬의 마지막 차수가 같으
므로 계산결과는 out.shape = a.shape[:-1] +
b.shape[:-1]
375](https://image.slidesharecdn.com/20160730-160726074138/85/python-375-320.jpg)
![Inner 예시 : 3차원
a(2,3,2) 행렬과 b(2,2)행렬의 마지막 차수가 같
으므로 계산결과는 out.shape = a.shape[:-1] +
b.shape[:-1]
376](https://image.slidesharecdn.com/20160730-160726074138/85/python-376-320.jpg)


![outer: 1
Out는 두개의 벡터에 대한 행렬로 구성
out[i, j] = a[i] * b[j]
379](https://image.slidesharecdn.com/20160730-160726074138/85/python-379-320.jpg)




![행렬
n개의 실수의 순서쌍에 성분별로 덧셈과 실수상수
곱을 주면[2] 이는 "nn차원" 벡터공간이라 할 수 있
고(, 벡터공간에서 벡터공간으로 가는 함수 중 덧셈
과 상수배를 보존하는 함수를 선형사상을 행렬이라
함
392](https://image.slidesharecdn.com/20160730-160726074138/85/python-392-320.jpg)














![주요 함수
선형대수에 대한 함수들
함수 설명
dot(a, b[, out]) n차원 행렬 n*m m*l에 대한 production(결과는 n*l)
vdot(a, b) Vector에 대한 prodution
inner(a, b) N 차원 행렬에 대한 Inner product (행렬이 동일해야 함).
outer(a, b[, out]) 2개 벡터에 대해 계산 후 행렬로 표시.
matmul(a, b[, out]) 두 행렬에 대한 Matrix product (dot과 동일한 결과)
tensordot(a, b[, axes]) Compute tensor dot product along specified axes for arrays >= 1-D.
linalg.matrix_power(M, n) Raise a square matrix to the (integer) power n.
cross(a, b, axisa=-1, axisb=-1, axisc=-1, axis=None) 행렬에 대한 외적을 구함
einsum(subscripts, *operands[, out, dtype, ...]) Evaluates the Einstein summation convention on the operands.
kron(a, b) Kronecker product of two arrays.
410](https://image.slidesharecdn.com/20160730-160726074138/85/python-410-320.jpg)
![주요 함수
선형대수에 대한 함수들
함수 설명
linalg.cholesky(a) Cholesky decomposition.
linalg.qr(a[, mode]) Compute the qr factorization of a matrix.
linalg.svd(a[, full_matrices, compute_uv]) Singular Value Decomposition.
412](https://image.slidesharecdn.com/20160730-160726074138/85/python-412-320.jpg)

![주요 함수
선형대수에 대한 함수들
함수 설명
linalg.eig(a) Compute the eigenvalues and right eigenvectors of a square array.
linalg.eigh(a[, UPLO]) Return the eigenvalues and eigenvectors of a Hermitian or symmetric matrix.
linalg.eigvals(a) Compute the eigenvalues of a general matrix.
linalg.eigvalsh(a[, UPLO]) Compute the eigenvalues of a Hermitian or real symmetric matrix.
linalg.eig(a) Compute the eigenvalues and right eigenvectors of a square array.
414](https://image.slidesharecdn.com/20160730-160726074138/85/python-414-320.jpg)
![주요 함수
선형대수에 대한 함수들
함수 설명
linalg.norm(x[, ord, axis, keepdims]) Matrix or vector norm.
linalg.cond(x[, p]) Compute the condition number of a matrix.
linalg.det(a) Compute the determinant of an array.
linalg.matrix_rank(M[, tol])
Return matrix rank of array using SVD method Rank of the array is the number of SVD sing
ular values of the array that are greater than tol.
linalg.slogdet(a) Compute the sign and (natural) logarithm of the determinant of an array.
trace(a[, offset, axis1, axis2, dtype, out]) Return the sum along diagonals of the array.
416](https://image.slidesharecdn.com/20160730-160726074138/85/python-416-320.jpg)

![주요 함수
선형대수에 대한 함수들
함수 설명
linalg.solve(a, b) Solve a linear matrix equation, or system of linear scalar equations.
linalg.tensorsolve(a, b[, axes]) Solve the tensor equation a x = b for x.
linalg.lstsq(a, b[, rcond]) Return the least-squares solution to a linear matrix equation.
linalg.inv(a) Compute the (multiplicative) inverse of a matrix.
linalg.pinv(a[, rcond]) Compute the (Moore-Penrose) pseudo-inverse of a matrix.
linalg.tensorinv(a[, ind]) Compute the ‘inverse’ of an N-dimensional array.
418](https://image.slidesharecdn.com/20160730-160726074138/85/python-418-320.jpg)

































![인접행렬
인접 행렬(adjacency matrix)은 그래프 G = (V,E),
|V| = n(≥1)일 때 그래프를 이차원 행열에 다음과
같이 저장하는 방법이다.
adj_mat[i][j] =
“1” if (vi, vj)가 인접할 때(adjacent)
“0” 인접하지 않을 경우
470](https://image.slidesharecdn.com/20160730-160726074138/85/python-470-320.jpg)




















































































































![등차급수
등차급수[ arithmetic series , 等差級數 ]
산술급수(算術級數)라고도 한다. 등차수열을 이
루고 있는 것을 말 함
급수 a1+a2+a3+…+an+…에서
an=an-1+d(n=2,3,…) 인 관계식
급수로 표시
610](https://image.slidesharecdn.com/20160730-160726074138/85/python-610-320.jpg)






























![String-operator
Operator Description Example
+
Concatenation - Adds values on either side of the operato
r
a + b will give HelloPython
*
Repetition - Creates new strings, concatenating multiple c
opies of the same string
a*2 will give -HelloHello
[]
Slice - Gives the character from the given index a[1] will give e
[ : ]
Range Slice - Gives the characters from the given range a[1:4] will give ell
in
Membership - Returns true if a character exists in the giv
en string
H in a will give 1
not in
Membership - Returns true if a character does not exist in
the given string
M not in a will give 1
r/R
Raw String
print r'n' prints n and print R'n'prints
n
%
Format - Performs String formatting See at next section
647](https://image.slidesharecdn.com/20160730-160726074138/85/python-647-320.jpg)




![Sequence-String 메소드(3)
String 내장 메소드
Method Description
isspace() Returns true if string contains only whitespace characters and false
otherwise.
istitle() Returns true if string is properly "titlecased" and false otherwise.
isupper() Returns true if string has at least one cased character and all cased
characters are in uppercase and false otherwise.
join(seq) Merges (concatenates) the string representations of elements in
sequence seq into a string, with separator string.
len(string) Returns the length of the string
ljust(width[, fillchar]) Returns a space-padded string with the original string left-justified to a
total of width columns.
lower() Converts all uppercase letters in string to lowercase.
lstrip() Removes all leading whitespace in string.
maketrans() Returns a translation table to be used in translate function.
653](https://image.slidesharecdn.com/20160730-160726074138/85/python-653-320.jpg)
![Sequence-String 메소드(4)
String 내장 메소드
Method Description
max(str) Returns the max alphabetical character from the string str.
min(str) Returns the min alphabetical character from the string str.
replace(old, new [, max]) Replaces all occurrences of old in string with new or at most max
occurrences if max given.
rfind(str, beg=0,end=len(stri
ng))
Same as find(), but search backwards in string.
rindex( str, beg=0,
end=len(string))
Same as index(), but search backwards in string.
rjust(width,[, fillchar]) Returns a space-padded string with the original string right-justified to
a total of width columns.
rstrip() Removes all trailing whitespace of string.
split(str="", num=string.cou
nt(str))
Splits string according to delimiter str (space if not provided) and
returns list of substrings; split into at most num substrings if given.
splitlines( num=string.count
('n'))
Splits string at all (or num) NEWLINEs and returns a list of each line with
NEWLINEs removed.
654](https://image.slidesharecdn.com/20160730-160726074138/85/python-654-320.jpg)
![Sequence-String 메소드(5)
String 내장 메소드
Method Description
startswith(str,
beg=0,end=len(string))
Determines if string or a substring of string (if starting index beg and
ending index end are given) starts with substring str; returns true if so
and false otherwise.
strip([chars]) Performs both lstrip() and rstrip() on string
swapcase() Inverts case for all letters in string.
title() Returns "titlecased" version of string, that is, all words begin with
uppercase and the rest are lowercase.
translate(table, deletechars
="")
Translates string according to translation table str(256 chars), removing
those in the del string.
upper() Converts lowercase letters in string to uppercase.
zfill (width) Returns original string leftpadded with zeros to a total of width
characters; intended for numbers, zfill() retains any sign given (less one
zero).
isdecimal() Returns true if a unicode string contains only decimal characters and
false otherwise.
655](https://image.slidesharecdn.com/20160730-160726074138/85/python-655-320.jpg)
















![Sequence - List 기본 처리
List 타입에 대한 기본 처리
Python Expression Results Description
l=[1,2,3] l.append(4) [1, 2, 3, 4] 리스트에 원소 추가
del l[3] [1, 2, 3] 리스트에 원소 삭제
len([1, 2, 3]) 3 Length 함수로 길이 확인
[1, 2, 3] + [4, 5, 6] [1, 2, 3, 4, 5, 6] 리스트를 합치니 Concatenation
['Hi!'] * 4 ['Hi!', 'Hi!', 'Hi!', 'Hi!'] 리스트 내의 원소를 Repetition
3 in [1, 2, 3] True 리스트 내의 원소들이 Membership
for x in [1, 2, 3]: print x, 1 2 3 리스트의 원소들을 반복자 활용 - Iteration
680](https://image.slidesharecdn.com/20160730-160726074138/85/python-680-320.jpg)




![Sequence-List 메소드
리스트 내장 메소드
Method Description
list.append(obj) Appends object obj to list
list.count(obj) Returns count of how many times obj occurs in list
list.extend(seq) Appends the contents of seq to list
list.index(obj) Returns the lowest index in list that obj appears
list.insert(index,obj) Inserts object obj into list at offset index
list.pop(obj=list[-1]) Removes and returns last object or obj from list
list.remove(obj) Removes object obj from list
list.reverse() Reverses objects of list in place
list.sort([func]) Sorts objects of list, use compare func if given
685](https://image.slidesharecdn.com/20160730-160726074138/85/python-685-320.jpg)




![Sequence-List : insert
list 내의 위치를 지정해서 원소를 넣을 때 [index]
일 경우는 index 범위가 벗어나면 오류가 발생하지
만 insert는 벗어나면 append로 인식해서 처리
690](https://image.slidesharecdn.com/20160730-160726074138/85/python-690-320.jpg)






![List Comprehension
리스트 정의시 값을 정하지 않고 호출 시 리스트
내의 값들이 처리되도록 구성
A = [ 표현식 for i in sequence if 논리식]
698](https://image.slidesharecdn.com/20160730-160726074138/85/python-698-320.jpg)
![List Comprehension : 다중
리스트 내의 다중 for문을 이용해서 처리
A = [ 표현식 for i in sequence for j in sequence
if 논리식]
699](https://image.slidesharecdn.com/20160730-160726074138/85/python-699-320.jpg)




![Accessing Values : index
Sequence Type(String, List, Tuple)은 변수명
[index]로 값을 접근하여 가져옴
변수에는 Sequence
Instance이 참조를 가
지고 있고 [index]를
이용하여 값들의 위치
를 검색
705](https://image.slidesharecdn.com/20160730-160726074138/85/python-705-320.jpg)


![Updating Values: string
문자열은 immutable이므로 [index]로 접근해서
갱신이 불가하므로 별도 로직을 작성해서 변경
709](https://image.slidesharecdn.com/20160730-160726074138/85/python-709-320.jpg)


















































































































![정적분: definite integral
리만 적분에서 다루는 고전적인 정의에 따르면 실수
의 척도를 사용하는 축도 공간에 나타낼 수 있는 연
속인 함수 f(x)에 대하여 그 함수의 정의역의 부분 집
합을 이루는 구간 [a, b] 에 대응하는 치역으로 이루
어진 곡선의 리만 합의 극한을 구하는 것이다. 이를
정적분(定積分, definite integral)이라 한다.
851](https://image.slidesharecdn.com/20160730-160726074138/85/python-851-320.jpg)

























































































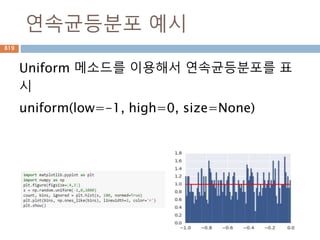
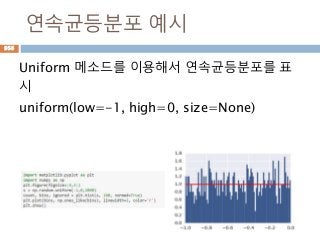
![연속균등분포
연속균등분포(continuous uniform distribution)은
연속 확률 분포로, 분포가 특정 범위 내에서 균등하
게 나타나 있을 경우를 가리킨다. 이 분포는 두 개의
매개변수 a,b를 받으며, 이때 [a,b] 범위에서 균등한
확률을 가진다.
955](https://image.slidesharecdn.com/20160730-160726074138/85/python-955-320.jpg)


![확률밀도함수
확률밀도함수(probability density function 약
자 PDF )f(x)는 일정한 값들의 범위를 포괄하는
연속확률변수의 확률을 찾는데 사용하고 연속데
이터에서의 확률을 구하기 위해서 확률밀도함수
의 면적을 구함
960
확률 밀도함수 f(x)와 구간[a,b] 에
대해 확률변수 X가 구간에 포함될
확률 P(a<= X<=b)는](https://image.slidesharecdn.com/20160730-160726074138/85/python-960-320.jpg)












![확률변수의 분산식 변형
분산식을 변형
975
분산 간편식
=-2E[XE[X]]
= -2E[X]E[X]
= -2E[X]2
를 이용해서 기대값 내의 기대값을
밖으로 배출](https://image.slidesharecdn.com/20160730-160726074138/85/python-975-320.jpg)




























































































































![[PYCON KOREA 2017] Python 입문자의 Data Science(Kaggle) 도전](https://cdn.slidesharecdn.com/ss_thumbnails/pyconkr2017fianl-170810071737-thumbnail.jpg?width=640&height=640&fit=bounds)







































