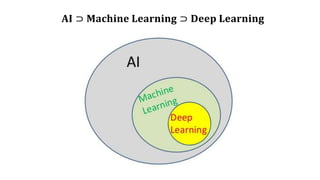
“머신 러닝 또는기계 학습은 인공 지능의 한 분야로, 컴
퓨터가 학습할 수 있도록 하는 알고리즘과 기술을 개발하
는 분야를 말한다.” - 위키피디아
“Field of study that gives computers the ability to learn
without being explicitly programmed.” - Arthur Samuel,
1959
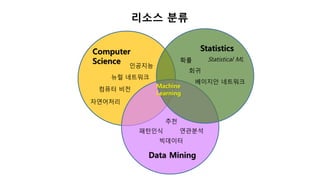
머신러닝이란
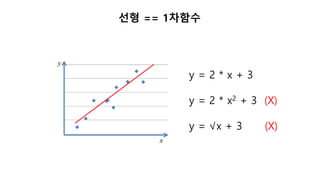
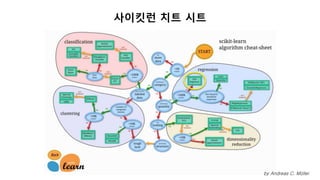
사이킷런의 내장 데이터
load_boston(): 주택가격
load_iris() : 붓꽃
load_diabetes() : 당뇨병
load_digits() : 손글씨숫자
load_linnerud() : 운동
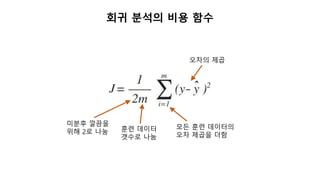
25.
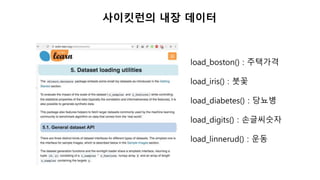
당뇨병 데이터
나이(Age), 성별(Sex),체질량(BMI), 혈압(BP), 혈액검사 데이터 6가지(S1~S6)
1년 뒤의 당뇨병 악화 지수
당뇨병 환자를 추적한 442개의 데이터셋
26.
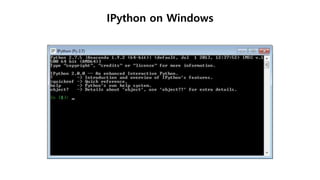
데이터 로드
$ ipython
...
In[1]: %pylab
In [2]: from sklearn import datasets
In [3]: diabetes = datasets.load_diabetes()
In [4]: print(diabetes.data.shape, diabetes.target.shape)
Out [5]: (442, 10) (442, )
27.
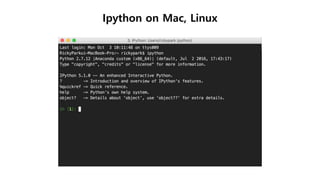
$ ipython
...
In [1]:%pylab
In [2]: from sklearn import datasets
In [3]: diabetes = datasets.load_diabetes()
In [4]: print(diabetes.data.shape, diabetes.target.shape)
Out [5]: (442, 10) (442, )
데이터 로드
넘파이, 맷플롯립 임포트
사이킷런의 데이터 패키지 임포트
데이터 로드
넘파이 변수
442개의 행
10개의 열
442개의 타겟
(병의 악화도)
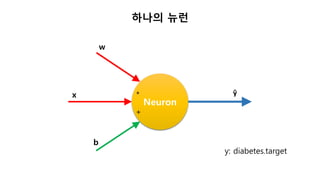
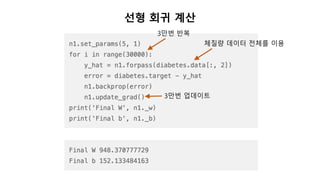
SingleNeuron
In [1]: n1= SingleNeuron()
In [2]: n1.set_params(5, 1) # w, b 를 5, 1 로 셋팅
In [3]: print(n1.forpass(3)) # x 에 3 을 입력
16
In [4]: n1.set_params(6, 1) # w, b 를 6, 1 로 셋팅
In [5]: print(n1.forpass(3)) # x 에 3 을 입력
19
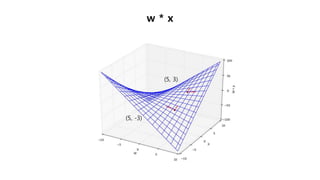
w 에 대한ŷ 의 변화율
In [1]: n1 = SingleNeuron()
In [2]: n1.set_params(5, 1) # w, b 를 5, 1 로 셋팅
In [3]: print(n1.forpass(3)) # x 에 3 을 입력
16
In [4]: n1.set_params(6, 1) # w, b 를 6, 1 로 셋팅
In [5]: print(n1.forpass(3)) # x 에 3 을 입력
19
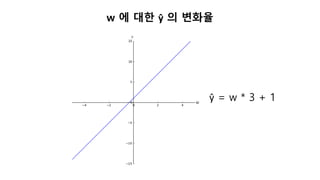
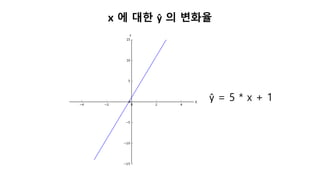
x 에 대한ŷ 의 변화율
In [1]: n1 = SingleNeuron()
In [2]: n1.set_params(5, 1) # w, b 를 5, 1 로 셋팅
In [3]: print(n1.forpass(3)) # x 에 3 을 입력
16
In [4]: n1.set_params(5, 1) # w, b 를 5, 1 로 셋팅
In [5]: print(n1.forpass(4)) # x 에 4 을 입력
21
b 에 대한ŷ 의 변화율
In [1]: n1 = SingleNeuron()
In [2]: n1.set_params(5, 1) # w, b 를 5, 1 로 셋팅
In [3]: print(n1.forpass(3)) # x 에 3 을 입력
16
In [4]: n1.set_params(5, 2) # w, b 를 5, 2 로 셋팅
In [5]: print(n1.forpass(3)) # x 에 3 을 입력
17
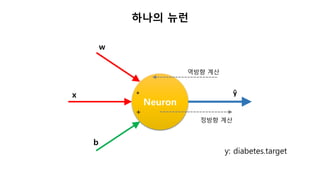
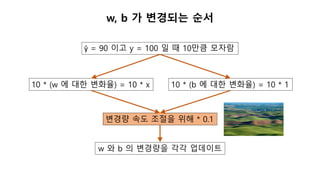
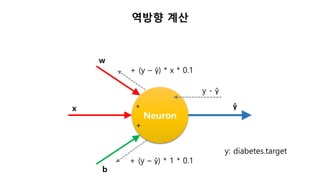
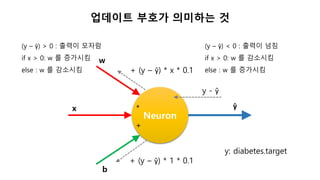
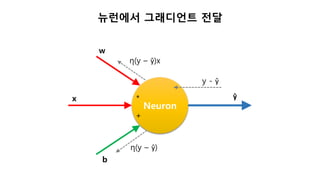
업데이트 부호가 의미하는것
Neuron
ŷ
w
x
b
*
+
y - ŷ
+ (y – ŷ) * x * 0.1
+ (y – ŷ) * 1 * 0.1
(y – ŷ) > 0 : 출력이 모자람
if x > 0: w 를 증가시킴
else : w 를 감소시킴
(y – ŷ) < 0 : 출력이 넘침
if x > 0: w 를 감소시킴
else : w 를 증가시킴
y: diabetes.target
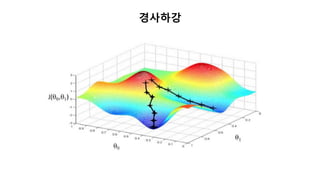
batch, mini-batch
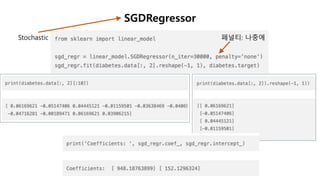
SGDRegressor(Stochastic GradientDescent): 확률적 경사 하강법
훈련 데이터를 하나씩 사용하여 반복 학습
SingleNeuron(Batch Gradient Descent): 훈련 데이터 전체를 사용하
여 반복 학습
Mini-Batch Gradient Descent: 훈련 데이터를 10~20개씩 묶음으로 나
누어 반복 학습
















![데이터 로드
$ ipython
...
In [1]: %pylab
In [2]: from sklearn import datasets
In [3]: diabetes = datasets.load_diabetes()
In [4]: print(diabetes.data.shape, diabetes.target.shape)
Out [5]: (442, 10) (442, )](https://image.slidesharecdn.com/1-161114054930/85/1-26-320.jpg)
![$ ipython
...
In [1]: %pylab
In [2]: from sklearn import datasets
In [3]: diabetes = datasets.load_diabetes()
In [4]: print(diabetes.data.shape, diabetes.target.shape)
Out [5]: (442, 10) (442, )
데이터 로드
넘파이, 맷플롯립 임포트
사이킷런의 데이터 패키지 임포트
데이터 로드
넘파이 변수
442개의 행
10개의 열
442개의 타겟
(병의 악화도)](https://image.slidesharecdn.com/1-161114054930/85/1-27-320.jpg)
![In [1]: print(diabetes.target[:10])
In [2]: print(diabetes.data[:5])
데이터 들여다 보기
슬라이스 연산자](https://image.slidesharecdn.com/1-161114054930/85/1-29-320.jpg)
![In [1]: print(diabetes.target[:10])
[ 151. 75. 141. 206. 135. 97. 138. 63. 110. 310.]
In [2]: print(diabetes.data[:5])
[[ 0.03807591 0.05068012 0.06169621 0.02187235 -0.0442235 -0.03482076 -
0.04340085 -0.00259226 0.01990842 -0.01764613] [-0.00188202 -0.04464164 -
0.05147406 -0.02632783 -0.00844872 -0.01916334 0.07441156 -0.03949338 -
0.06832974 -0.09220405] [ 0.08529891 0.05068012 0.04445121 -0.00567061 -
0.04559945 -0.03419447 -0.03235593 -0.00259226 0.00286377 -0.02593034] [-
0.08906294 -0.04464164 -0.01159501 -0.03665645 0.01219057 0.02499059 -
0.03603757 0.03430886 0.02269202 -0.00936191] [ 0.00538306 -0.04464164 -
0.03638469 0.02187235 0.00393485 0.01559614 0.00814208-0.00259226 -
0.03199144 -0.04664087]]
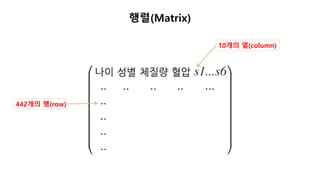
데이터 들여다 보기
10개의 열(column)
442개의 행(row)](https://image.slidesharecdn.com/1-161114054930/85/1-30-320.jpg)
![In [1]: print(diabetes.target[:10])
[ 151. 75. 141. 206. 135. 97. 138. 63. 110. 310.]
In [2]: print(diabetes.data[:5])
[[ 0.03807591 0.05068012 0.06169621 0.02187235 -0.0442235 -0.03482076 -
0.04340085 -0.00259226 0.01990842 -0.01764613]
데이터 들여다 보기
나이 성별 체질량](https://image.slidesharecdn.com/1-161114054930/85/1-31-320.jpg)
![In [1]: print(diabetes.target[:10])
[ 151. 75. 141. 206. 135. 97. 138. 63. 110. 310.]
In [2]: print(diabetes.data[:5])
[[ 0.03807591 0.05068012 0.06169621 0.02187235 -0.0442235 -0.03482076 -
0.04340085 -0.00259226 0.01990842 -0.01764613]
데이터 들여다 보기
나이 성별 체질량
sklearn.preprocessing.scale ---> sklearn.preprocessing.normalize
0.05068012 , -0.04464164](https://image.slidesharecdn.com/1-161114054930/85/1-32-320.jpg)

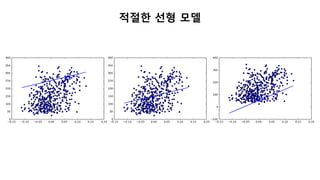
![산점도(Scatter Plot)
In [1]: plt.scatter(diabetes.data[:,2], diabetes.target)](https://image.slidesharecdn.com/1-161114054930/85/1-34-320.jpg)



![SingleNeuron
In [1]: n1 = SingleNeuron()
In [2]: n1.set_params(5, 1) # w, b 를 5, 1 로 셋팅
In [3]: print(n1.forpass(3)) # x 에 3 을 입력
16
In [4]: n1.set_params(6, 1) # w, b 를 6, 1 로 셋팅
In [5]: print(n1.forpass(3)) # x 에 3 을 입력
19](https://image.slidesharecdn.com/1-161114054930/85/1-43-320.jpg)
![w 에 대한 ŷ 의 변화율
In [1]: n1 = SingleNeuron()
In [2]: n1.set_params(5, 1) # w, b 를 5, 1 로 셋팅
In [3]: print(n1.forpass(3)) # x 에 3 을 입력
16
In [4]: n1.set_params(6, 1) # w, b 를 6, 1 로 셋팅
In [5]: print(n1.forpass(3)) # x 에 3 을 입력
19](https://image.slidesharecdn.com/1-161114054930/85/1-45-320.jpg)
![x 에 대한 ŷ 의 변화율
In [1]: n1 = SingleNeuron()
In [2]: n1.set_params(5, 1) # w, b 를 5, 1 로 셋팅
In [3]: print(n1.forpass(3)) # x 에 3 을 입력
16
In [4]: n1.set_params(5, 1) # w, b 를 5, 1 로 셋팅
In [5]: print(n1.forpass(4)) # x 에 4 을 입력
21](https://image.slidesharecdn.com/1-161114054930/85/1-47-320.jpg)
![b 에 대한 ŷ 의 변화율
In [1]: n1 = SingleNeuron()
In [2]: n1.set_params(5, 1) # w, b 를 5, 1 로 셋팅
In [3]: print(n1.forpass(3)) # x 에 3 을 입력
16
In [4]: n1.set_params(5, 2) # w, b 를 5, 2 로 셋팅
In [5]: print(n1.forpass(3)) # x 에 3 을 입력
17](https://image.slidesharecdn.com/1-161114054930/85/1-49-320.jpg)








































![[신경망기초] 신경망의시작-퍼셉트론](https://cdn.slidesharecdn.com/ss_thumbnails/nn02-180318141341-thumbnail.jpg?width=640&height=640&fit=bounds)
![[신경망기초] 선형회귀분석](https://cdn.slidesharecdn.com/ss_thumbnails/nn07-180318142107-thumbnail.jpg?width=640&height=640&fit=bounds)




![[PYCON KOREA 2017] Python 입문자의 Data Science(Kaggle) 도전](https://cdn.slidesharecdn.com/ss_thumbnails/pyconkr2017fianl-170810071737-thumbnail.jpg?width=640&height=640&fit=bounds)






















![[GomGuard] 뉴런부터 YOLO 까지 - 딥러닝 전반에 대한 이야기](https://cdn.slidesharecdn.com/ss_thumbnails/part1mlp2cnn-slidesharev-180308015531-thumbnail.jpg?width=640&height=640&fit=bounds)


![[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 4장. 모델 훈련](https://cdn.slidesharecdn.com/ss_thumbnails/handson-mlch-180814064959-thumbnail.jpg?width=640&height=640&fit=bounds)




![[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 1장. 한눈에 보는 머신러닝](https://cdn.slidesharecdn.com/ss_thumbnails/handon-mlch-180626070350-thumbnail.jpg?width=640&height=640&fit=bounds)








![[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 9장 텐서플로 시작하기](https://cdn.slidesharecdn.com/ss_thumbnails/handson-mlch-181127072259-thumbnail.jpg?width=640&height=640&fit=bounds)


![[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 6장 결정 트리](https://cdn.slidesharecdn.com/ss_thumbnails/handson-mlch-181010080045-thumbnail.jpg?width=640&height=640&fit=bounds)
![[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 5장. 서포트 벡터 머신](https://cdn.slidesharecdn.com/ss_thumbnails/handson-mlch-180905033306-thumbnail.jpg?width=640&height=640&fit=bounds)
![[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 3장. 분류](https://cdn.slidesharecdn.com/ss_thumbnails/handson-mlch-180724063825-thumbnail.jpg?width=640&height=640&fit=bounds)
![[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 2장. 머신러닝 프로젝트 처음부터 끝까지](https://cdn.slidesharecdn.com/ss_thumbnails/handon-mlch-180710075557-thumbnail.jpg?width=640&height=640&fit=bounds)








