Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Kentaro Yoshida
PDF, PPTX
27,963 views
爆速クエリエンジン”Presto”を使いたくなる話
Prestoの導入メリットのほか、HiveQLからPrestoへの書き換えTipsを紹介します
Technology
◦
Read more
49
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 30
2
/ 30
3
/ 30
4
/ 30
5
/ 30
6
/ 30
7
/ 30
8
/ 30
9
/ 30
10
/ 30
11
/ 30
12
/ 30
Most read
13
/ 30
14
/ 30
15
/ 30
16
/ 30
17
/ 30
18
/ 30
19
/ 30
20
/ 30
21
/ 30
22
/ 30
23
/ 30
24
/ 30
25
/ 30
26
/ 30
27
/ 30
28
/ 30
29
/ 30
30
/ 30
More Related Content
PDF
Hadoop/Spark を使うなら Bigtop を使い熟そう! ~並列分散処理基盤のいま、から Bigtop の最近の取り組みまで一挙ご紹介~(Ope...
by
NTT DATA Technology & Innovation
PDF
NTT DATA と PostgreSQL が挑んだ総力戦
by
NTT DATA OSS Professional Services
PPTX
Prometheus入門から運用まで徹底解説
by
貴仁 大和屋
PDF
マルチテナント化で知っておきたいデータベースのこと
by
Amazon Web Services Japan
PPTX
本当は恐ろしい分散システムの話
by
Kumazaki Hiroki
PDF
大規模サービスを支えるネットワークインフラの全貌
by
LINE Corporation
PPTX
コンテナネットワーキング(CNI)最前線
by
Motonori Shindo
PDF
マイクロにしすぎた結果がこれだよ!
by
mosa siru
Hadoop/Spark を使うなら Bigtop を使い熟そう! ~並列分散処理基盤のいま、から Bigtop の最近の取り組みまで一挙ご紹介~(Ope...
by
NTT DATA Technology & Innovation
NTT DATA と PostgreSQL が挑んだ総力戦
by
NTT DATA OSS Professional Services
Prometheus入門から運用まで徹底解説
by
貴仁 大和屋
マルチテナント化で知っておきたいデータベースのこと
by
Amazon Web Services Japan
本当は恐ろしい分散システムの話
by
Kumazaki Hiroki
大規模サービスを支えるネットワークインフラの全貌
by
LINE Corporation
コンテナネットワーキング(CNI)最前線
by
Motonori Shindo
マイクロにしすぎた結果がこれだよ!
by
mosa siru
What's hot
PDF
KafkaとPulsar
by
Yahoo!デベロッパーネットワーク
PPTX
イベント・ソーシングを知る
by
Shuhei Fujita
PDF
At least onceってぶっちゃけ問題の先送りだったよね #kafkajp
by
Yahoo!デベロッパーネットワーク
PPTX
AWSで作る分析基盤
by
Yu Otsubo
PDF
アーキテクチャから理解するPostgreSQLのレプリケーション
by
Masahiko Sawada
PPTX
初心者向けMongoDBのキホン!
by
Tetsutaro Watanabe
PPTX
CloudNativePGを動かしてみた! ~PostgreSQL on Kubernetes~(第34回PostgreSQLアンカンファレンス@オンライ...
by
NTT DATA Technology & Innovation
PDF
入門 Kubeflow ~Kubernetesで機械学習をはじめるために~ (NTT Tech Conference #4 講演資料)
by
NTT DATA Technology & Innovation
PPTX
Apache Spark on Kubernetes入門(Open Source Conference 2021 Online Hiroshima 発表資料)
by
NTT DATA Technology & Innovation
PPTX
PostgreSQLクエリ実行の基礎知識 ~Explainを読み解こう~
by
Miki Shimogai
PDF
Apache Kafkaって本当に大丈夫?~故障検証のオーバービューと興味深い挙動の紹介~
by
NTT DATA OSS Professional Services
PDF
MQTTとAMQPと.NET
by
terurou
PPTX
Kubernetesでの性能解析 ~なんとなく遅いからの脱却~(Kubernetes Meetup Tokyo #33 発表資料)
by
NTT DATA Technology & Innovation
PDF
多要素認証による Amazon WorkSpaces の利用
by
Amazon Web Services Japan
PPTX
PostgreSQLモニタリングの基本とNTTデータが追加したモニタリング新機能(Open Source Conference 2021 Online F...
by
NTT DATA Technology & Innovation
PDF
Apache Sparkに手を出してヤケドしないための基本 ~「Apache Spark入門より」~ (デブサミ 2016 講演資料)
by
NTT DATA OSS Professional Services
PPTX
NTTデータ流Infrastructure as Code~ 大規模プロジェクトを通して考え抜いた基盤自動化の新たな姿~(NTTデータ テクノロジーカンフ...
by
NTT DATA Technology & Innovation
PDF
分散トレーシング技術について(Open tracingやjaeger)
by
NTT Communications Technology Development
PDF
ロードバランスへの長い道
by
Jun Kato
PDF
大規模DCのネットワークデザイン
by
Masayuki Kobayashi
KafkaとPulsar
by
Yahoo!デベロッパーネットワーク
イベント・ソーシングを知る
by
Shuhei Fujita
At least onceってぶっちゃけ問題の先送りだったよね #kafkajp
by
Yahoo!デベロッパーネットワーク
AWSで作る分析基盤
by
Yu Otsubo
アーキテクチャから理解するPostgreSQLのレプリケーション
by
Masahiko Sawada
初心者向けMongoDBのキホン!
by
Tetsutaro Watanabe
CloudNativePGを動かしてみた! ~PostgreSQL on Kubernetes~(第34回PostgreSQLアンカンファレンス@オンライ...
by
NTT DATA Technology & Innovation
入門 Kubeflow ~Kubernetesで機械学習をはじめるために~ (NTT Tech Conference #4 講演資料)
by
NTT DATA Technology & Innovation
Apache Spark on Kubernetes入門(Open Source Conference 2021 Online Hiroshima 発表資料)
by
NTT DATA Technology & Innovation
PostgreSQLクエリ実行の基礎知識 ~Explainを読み解こう~
by
Miki Shimogai
Apache Kafkaって本当に大丈夫?~故障検証のオーバービューと興味深い挙動の紹介~
by
NTT DATA OSS Professional Services
MQTTとAMQPと.NET
by
terurou
Kubernetesでの性能解析 ~なんとなく遅いからの脱却~(Kubernetes Meetup Tokyo #33 発表資料)
by
NTT DATA Technology & Innovation
多要素認証による Amazon WorkSpaces の利用
by
Amazon Web Services Japan
PostgreSQLモニタリングの基本とNTTデータが追加したモニタリング新機能(Open Source Conference 2021 Online F...
by
NTT DATA Technology & Innovation
Apache Sparkに手を出してヤケドしないための基本 ~「Apache Spark入門より」~ (デブサミ 2016 講演資料)
by
NTT DATA OSS Professional Services
NTTデータ流Infrastructure as Code~ 大規模プロジェクトを通して考え抜いた基盤自動化の新たな姿~(NTTデータ テクノロジーカンフ...
by
NTT DATA Technology & Innovation
分散トレーシング技術について(Open tracingやjaeger)
by
NTT Communications Technology Development
ロードバランスへの長い道
by
Jun Kato
大規模DCのネットワークデザイン
by
Masayuki Kobayashi
Viewers also liked
PPTX
Amazon Athena で実現する データ分析の広がり
by
Amazon Web Services Japan
PDF
Apache Kuduは何がそんなに「速い」DBなのか? #dbts2017
by
Cloudera Japan
PDF
NetflixにおけるPresto/Spark活用事例
by
Amazon Web Services Japan
PDF
いまさら聞けない機械学習の評価指標
by
圭輔 大曽根
PDF
“確率的最適化”を読む前に知っておくといいかもしれない関数解析のこと
by
Hiroaki Kudo
PDF
#cwt2016 Apache Kudu 構成とテーブル設計
by
Cloudera Japan
PDF
論文紹介@ Gunosyデータマイニング研究会 #97
by
圭輔 大曽根
PDF
マイクロサービスとABテスト
by
圭輔 大曽根
PDF
WebDB Forum 2016 gunosy
by
Hiroaki Kudo
PPTX
A/B Testing at Pinterest: Building a Culture of Experimentation
by
WrangleConf
PDF
Gunosyデータマイニング研究会 #118 これからの強化学習
by
圭輔 大曽根
PDF
あなただけにそっと教える弊社の分析事情 #data analyst meetup tokyo vol.1 LT
by
Hiroaki Kudo
PDF
Apache Kudu - Updatable Analytical Storage #rakutentech
by
Cloudera Japan
PDF
「新製品 Kudu 及び RecordServiceの概要」 #cwt2015
by
Cloudera Japan
PDF
Gunosy における AWS 上での自然言語処理・機械学習の活用事例
by
圭輔 大曽根
PPTX
ぼくがAthenaで死ぬまで
by
Shinichi Takahashi
PDF
記事分類における教師データおよびモデルの管理
by
圭輔 大曽根
PDF
機械学習で大事なことをミニGunosyをつくって学んだ╭( ・ㅂ・)و ̑̑
by
Seiji Takahashi
Amazon Athena で実現する データ分析の広がり
by
Amazon Web Services Japan
Apache Kuduは何がそんなに「速い」DBなのか? #dbts2017
by
Cloudera Japan
NetflixにおけるPresto/Spark活用事例
by
Amazon Web Services Japan
いまさら聞けない機械学習の評価指標
by
圭輔 大曽根
“確率的最適化”を読む前に知っておくといいかもしれない関数解析のこと
by
Hiroaki Kudo
#cwt2016 Apache Kudu 構成とテーブル設計
by
Cloudera Japan
論文紹介@ Gunosyデータマイニング研究会 #97
by
圭輔 大曽根
マイクロサービスとABテスト
by
圭輔 大曽根
WebDB Forum 2016 gunosy
by
Hiroaki Kudo
A/B Testing at Pinterest: Building a Culture of Experimentation
by
WrangleConf
Gunosyデータマイニング研究会 #118 これからの強化学習
by
圭輔 大曽根
あなただけにそっと教える弊社の分析事情 #data analyst meetup tokyo vol.1 LT
by
Hiroaki Kudo
Apache Kudu - Updatable Analytical Storage #rakutentech
by
Cloudera Japan
「新製品 Kudu 及び RecordServiceの概要」 #cwt2015
by
Cloudera Japan
Gunosy における AWS 上での自然言語処理・機械学習の活用事例
by
圭輔 大曽根
ぼくがAthenaで死ぬまで
by
Shinichi Takahashi
記事分類における教師データおよびモデルの管理
by
圭輔 大曽根
機械学習で大事なことをミニGunosyをつくって学んだ╭( ・ㅂ・)و ̑̑
by
Seiji Takahashi
More from Kentaro Yoshida
PDF
Fluentdのお勧めシステム構成パターン
by
Kentaro Yoshida
PDF
MySQLと組み合わせて始める全文検索プロダクト"elasticsearch"
by
Kentaro Yoshida
PDF
ElasticSearch+Kibanaでログデータの検索と視覚化を実現するテクニックと運用ノウハウ
by
Kentaro Yoshida
PDF
MySQL Casual Talks Vol.4 「MySQL-5.6で始める全文検索 〜InnoDB FTS編〜」
by
Kentaro Yoshida
PDF
Fluentd, Digdag, Embulkを用いたデータ分析基盤の始め方
by
Kentaro Yoshida
PDF
TREASUREDATAのエコシステムで作るロバストなETLデータ処理基盤の作り方
by
Kentaro Yoshida
PDF
Hivemallで始める不動産価格推定サービス
by
Kentaro Yoshida
PDF
Improve data engineering work with Digdag and Presto UDF
by
Kentaro Yoshida
PDF
Fluentdベースのミドルウェア"Yamabiko"でMySQLのテーブルをElasticsearchへレプリケートする話 #fluentdcasual
by
Kentaro Yoshida
PDF
トレジャーデータ 導入体験記 リブセンス編
by
Kentaro Yoshida
PDF
MySQLユーザ視点での小さく始めるElasticsearch
by
Kentaro Yoshida
PDF
MySQL 5.6への完全移行を実現したTritonnからMroongaへの移行体験記
by
Kentaro Yoshida
PDF
Tritonn (MySQL5.0.87+Senna)からの mroonga (MySQL5.6) 移行体験記
by
Kentaro Yoshida
Fluentdのお勧めシステム構成パターン
by
Kentaro Yoshida
MySQLと組み合わせて始める全文検索プロダクト"elasticsearch"
by
Kentaro Yoshida
ElasticSearch+Kibanaでログデータの検索と視覚化を実現するテクニックと運用ノウハウ
by
Kentaro Yoshida
MySQL Casual Talks Vol.4 「MySQL-5.6で始める全文検索 〜InnoDB FTS編〜」
by
Kentaro Yoshida
Fluentd, Digdag, Embulkを用いたデータ分析基盤の始め方
by
Kentaro Yoshida
TREASUREDATAのエコシステムで作るロバストなETLデータ処理基盤の作り方
by
Kentaro Yoshida
Hivemallで始める不動産価格推定サービス
by
Kentaro Yoshida
Improve data engineering work with Digdag and Presto UDF
by
Kentaro Yoshida
Fluentdベースのミドルウェア"Yamabiko"でMySQLのテーブルをElasticsearchへレプリケートする話 #fluentdcasual
by
Kentaro Yoshida
トレジャーデータ 導入体験記 リブセンス編
by
Kentaro Yoshida
MySQLユーザ視点での小さく始めるElasticsearch
by
Kentaro Yoshida
MySQL 5.6への完全移行を実現したTritonnからMroongaへの移行体験記
by
Kentaro Yoshida
Tritonn (MySQL5.0.87+Senna)からの mroonga (MySQL5.6) 移行体験記
by
Kentaro Yoshida
Recently uploaded
PDF
20260119_VIoTLT_vol22_kitazaki_v1___.pdf
by
Ayachika Kitazaki
PDF
TomokaEdakawa_職種と講義の関係推定に基づく履修支援システムの基礎検討_HCI2026
by
Matsushita Laboratory
PDF
自転車ユーザ参加型路面画像センシングによる点字ブロック検出における性能向上方法の模索 (20260123 SeMI研)
by
Yuto Matsuda
PDF
maisugimoto_曖昧さを含む仕様書の改善を目的としたアノテーション支援ツールの検討_HCI2025.pdf
by
Matsushita Laboratory
PDF
ST2024_PM1_2_Case_study_of_local_newspaper_company.pdf
by
akipii ogaoga
PDF
Team Topology Adaptive Organizational Design for Rapid Delivery of Valuable S...
by
akipii ogaoga
20260119_VIoTLT_vol22_kitazaki_v1___.pdf
by
Ayachika Kitazaki
TomokaEdakawa_職種と講義の関係推定に基づく履修支援システムの基礎検討_HCI2026
by
Matsushita Laboratory
自転車ユーザ参加型路面画像センシングによる点字ブロック検出における性能向上方法の模索 (20260123 SeMI研)
by
Yuto Matsuda
maisugimoto_曖昧さを含む仕様書の改善を目的としたアノテーション支援ツールの検討_HCI2025.pdf
by
Matsushita Laboratory
ST2024_PM1_2_Case_study_of_local_newspaper_company.pdf
by
akipii ogaoga
Team Topology Adaptive Organizational Design for Rapid Delivery of Valuable S...
by
akipii ogaoga
爆速クエリエンジン”Presto”を使いたくなる話
1.
page Apr, 2015 24th ! 爆速クエリエンジン”Presto”を使いたくなる話 1
2.
page 1. 自己紹介 2
4.
お知らせ
5.
page 自己紹介 5 好きなプロダクト
6.
page 1. 自己紹介 2. Prestoを使う理由 3.
HiveからPrestoへの書換Tips 4. まとめ 本日の流れ 6
7.
page 2. Prestoを使う理由 7
8.
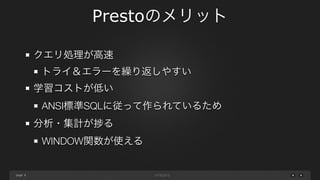
page Prestoのメリット 8 クエリ処理が高速 トライ&エラーを繰り返しやすい 学習コストが低い ANSI標準SQLに従って作られているため 分析・集計が る WITH句・WINDOW関数が使える
9.
page PrestoとHiveの使い分け 9 Presto 長くても2∼3分で終わる集計に最適 コンパクトな処理をすばやく実行したい時 Hive 数分以上∼数時間掛かるバッチクエリ メモリに乗り切らないオーダーの処理 JOIN数が多い時ないし、JOINの条件が文字列である時 結果セットが数百万行、文字列型カラム多数の時
10.
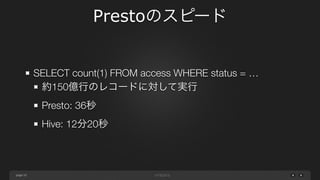
page Prestoのスピード 10 SELECT count(1) FROM
access WHERE status = … 約150億行のレコードに対して実行 Presto: 36秒 Hive: 12分20秒
11.
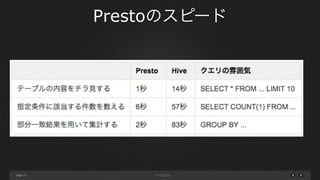
page Prestoのスピード 11
12.
page Presto雑感 12 WITH句がとても便利(可読性・UNION句での再利用性) CASTを使うことが思いのほか多い LIKE句よりregexp_like()が速いので積極的に使うべき JOIN結果が数十∼数百万行となるクエリで、文字列型の キーを使うとメモリを使い切って失敗する TreasureDataにはsmart_digestがあるのでそれを使うと吉 ハッシュ関数の衝突確率を下げるため、 substr()を用いた文字列の先頭一致も併せて行いましょう
13.
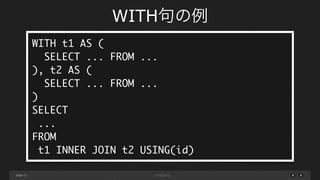
page WITH句の例 13 WITH t1 AS
( SELECT ... FROM ... ), t2 AS ( SELECT ... FROM ... ) SELECT ... FROM t1 INNER JOIN t2 USING(id)
14.
page WITH句の例 14 WITH t1 AS
( SELECT ... FROM ... ) SELECT … FROM t1 WHERE … UNION ALL SELECT … FROM t1 WHERE … UNION ALL SELECT … FROM t1 WHERE …
15.
page 3. HiveからPrestoへの書換Tips 15
16.
page HiveからPrestoへの書換Tips 16 正規表現のエスケープ挙動 select regexp_extract('(123)', '^((.+))$',
1) Hive: (123) Presto: 123 select regexp_extract('(123)', '^((.+))$', 1) Hive: 123 Presto: ※空文字
17.
page HiveからPrestoへの書換Tips 17 INT型の割り算で結果がFLOAT/DOUBLE型となるとき select 3 /
2 as division Hive: 1.5 Presto: 1 select CAST(3 AS DOUBLE) / 2 as division Hive: 1.5 Presto: 1.5 ※ 全てがINT型とならないようにいずれかをCASTする
18.
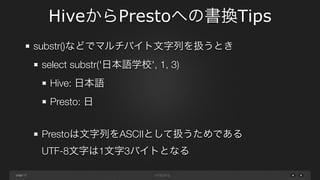
page HiveからPrestoへの書換Tips 18 substr()などでマルチバイト文字列を扱うとき select substr('日本語学校', 1,
3) Hive: 日本語 Presto: 日 ! Prestoは文字列をASCIIとして扱うためである UTF-8文字は1文字3バイトとなる
19.
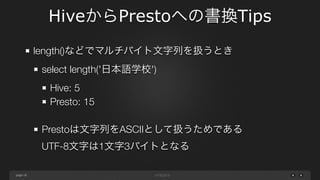
page HiveからPrestoへの書換Tips 19 length()などでマルチバイト文字列を扱うとき select length('日本語学校') Hive: 5 Presto:
15 ! Prestoは文字列をASCIIとして扱うためである UTF-8文字は1文字3バイトとなる
20.
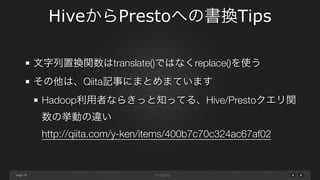
page HiveからPrestoへの書換Tips 20 文字列置換関数はtranslate()ではなくreplace()を使う その他は、Qiita記事にまとめています Hadoop利用者ならきっと知ってる、Hive/Prestoクエリ関 数の挙動の違い http://qiita.com/y-ken/items/400b7c70c324ac67af02
22.
page 4. まとめ 22
23.
page まとめ 23 とてもクエリ実行が速いため調査・分析業務が る MySQLテーブルをHadoopにインポートしてJOINしている Prestgresを用いるとPostgreSQLのように使えるので便利 TreasureDataのオプションサービス契約して良かった
24.
page まとめ 24 2015年4月現在、マルチバイト対応が甘い リソースコントロールが甘い 重たいクエリがノードのリソースを使い切ってしまう SELECTするカラムvarchar型が多いとき、HiveQLより 極端に遅くなることがあったがpresto v0.100現在は解消 日々改善・進歩しているため、今後に期待
25.
page 宣伝 25 サーバ/インフラエンジニア養成読本 ログ収集∼可視化編 [現場主導のデータ分析環 境を構築!] (Software
Design plus) 出版社/メーカー: 技術評論社 定価: 本体1,980円+税
26.
お知らせ
30.
page Thanks! 30 ご清聴ありがとうございました。
Download
















![page
宣伝
25
サーバ/インフラエンジニア養成読本
ログ収集∼可視化編 [現場主導のデータ分析環
境を構築!] (Software Design plus)
出版社/メーカー: 技術評論社
定価: 本体1,980円+税](https://image.slidesharecdn.com/bullethadoopqueryenginepresto-150424064424-conversion-gate01/85/Presto-25-320.jpg)