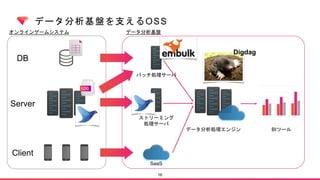
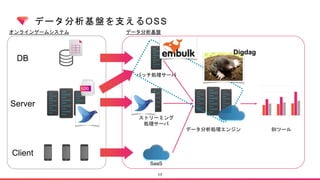
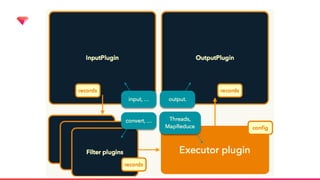
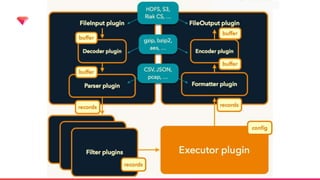
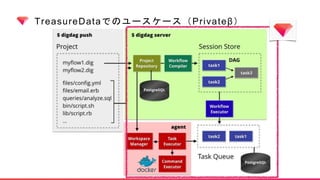
Digdagとは?
Digdag is asimple tool that helps you to build, run, schedule, and monitor
complex pipelines of tasks. It handles dependency resolution so that tasks
run in order or in parallel.
Digdag fits simple replacement of cron, IT operations automation, data
analytics batch jobs, machine learning pipelines, and many more by using
Directed Acyclic Graphs (DAG) as the infrastructure.
47
http://www.digdag.io/index.html









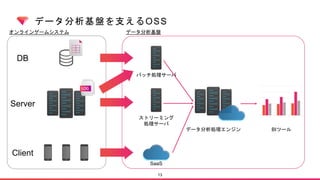
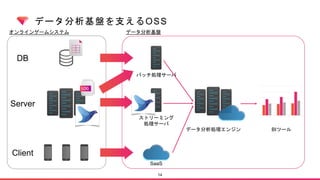
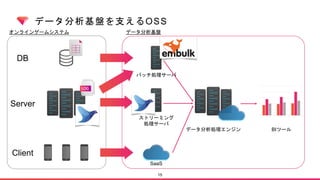











































![[db tech showcase Tokyo 2015] C27:楽天MySQL Backup Structure by 楽天株式会社 粟田啓介](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015c27mysqlrakuten-150617022225-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Aurora事例祭り]Amazon Aurora を使いこなすためのベストプラクティス](https://cdn.slidesharecdn.com/ss_thumbnails/amazonauroratips-170307140000-thumbnail.jpg?width=640&height=640&fit=bounds)

![[B31] LOGMinerってレプリケーションソフトで使われているけどどうなってる? by Toshiya Morita](https://cdn.slidesharecdn.com/ss_thumbnails/b31iti-140624235903-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)






























![[db tech showcase Tokyo 2014] D33: Prestoで実現するインタラクティブクエリ by トレジャーデータ株式会社 斉藤太郎](https://cdn.slidesharecdn.com/ss_thumbnails/dbtstokyo2014d33presto-141120012543-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)
















